
Controlling human causal inference through in silico task design - results
이전 포스트에서 하지 못했던 논문의 결과 부분을 알아보겠다.
Results
Task control: In silico task design for guiding human causal inference
태스크 컨트롤러는 지식 베이스(Knowledge Base, KB) 를 기반으로 인지 모델(Cognitive Models) 과 함께 완전히 훈련된 후, 최적화된 S-O(Stimulus-Outcome) 시퀀스 를 활용하여 참가자에게 점진적으로 제시하는 방식으로 작동하였다. 연구진은 이 과정에서 태스크 컨트롤러의 설계 목표에 따라 참가자의 학습 전략이 변화할 것이라는 가설을 세웠다. 즉, 태스크 컨트롤러가 학습을 유도하는 방식이 참가자의 학습 방식에 영향을 미쳐, Oneshot+ 또는 Bayesian+ 조건에 따라 서로 다른 학습 패턴이 나타날 것 으로 예상하였다.
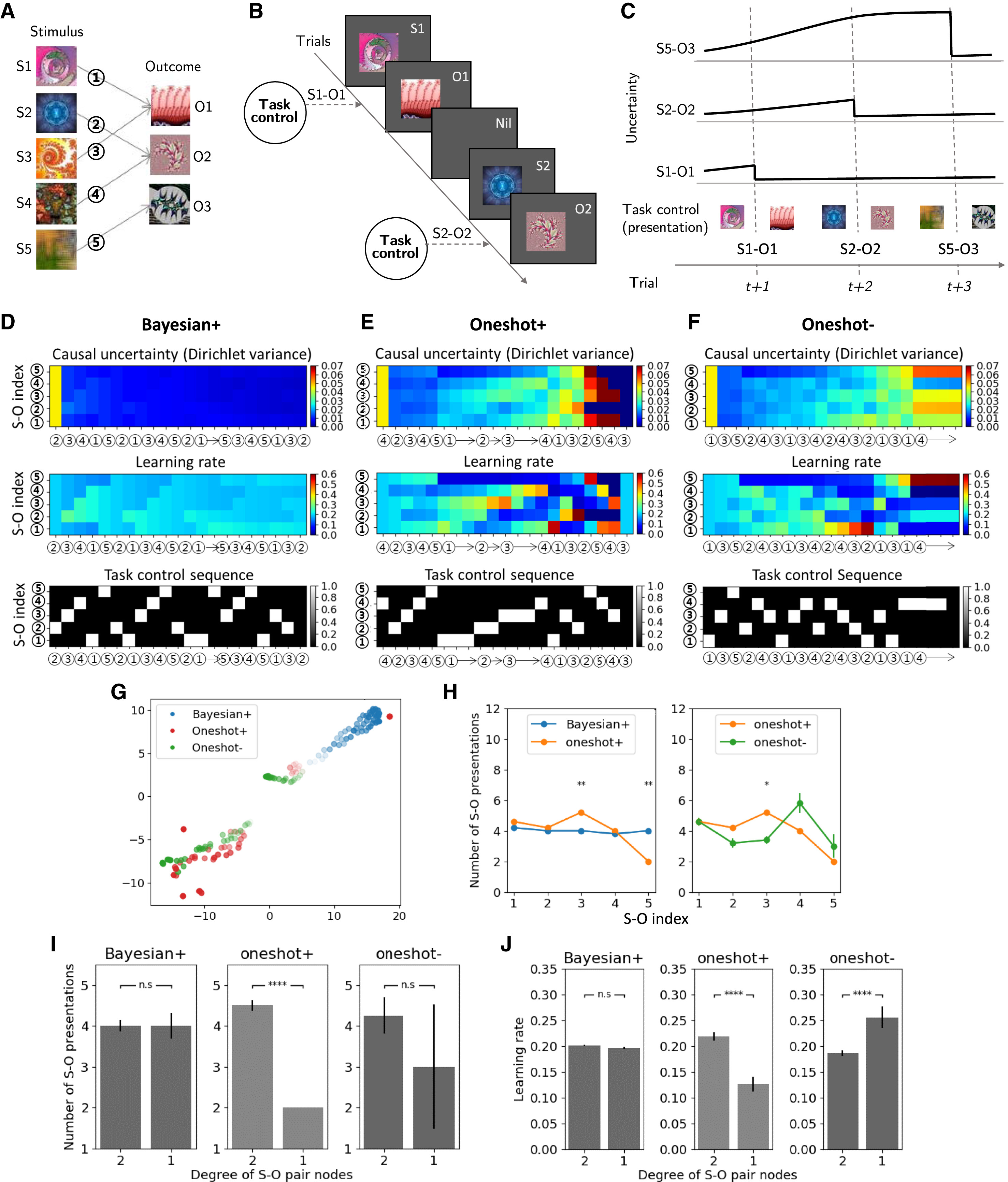
Figure 2A는 태스크 컨트롤러의 학습을 나타낸 것이다. 태스크 컨트롤러는 지식 베이스를 기반으로, 강화학습(RL)과 인지 모델을 결합한 방식 으로 훈련되었다. 이 과정에서 태스크 컨트롤러는 특정 목표(예: One-shot 학습 촉진 또는 억제)를 달성하도록 최적화되었다.
훈련이 완료된 태스크 컨트롤러는 학습된 정책을 활용하여, 참가자들에게 최적화된 S-O 시퀀스를 연속적으로 제시하였다. 이때 Oneshot+ 조건에서는 빠른 학습을 유도하는 방식, Bayesian+ 조건에서는 점진적 학습을 유도하는 방식 으로 시퀀스가 구성되었다.
Figure 2C는 태스크 컨트롤 과정에서의 인지 모델의 불확실도가 변화하는 과정의 예시이다.
태스크 컨트롤이 인과적 복잡성을 조정하는 방식 분석
이 부분에서는 태스크 컨트롤러가 학습한 행동 정책(Behavioral Policy) 을 더 잘 이해하기 위해, 각 인과 추론 모델(Causal Inference Model)의 잠재 상태(latent state)가 태스크 컨트롤러의 영향을 받아 어떻게 변화하는지를 분석하였다. 연구진은 각 태스크 컨트롤러가 최적화한 학습 태스크 수행 과정에서, 인과 불확실성(causal uncertainty)과 학습률(learning rate)이 어떻게 변하는지를 비교하였다.
Figure 2D는 Bayesian+ 모델의 태스크 컨트롤 전략에 따라 최적화된 S-O 시퀀스이다. S-O 불확실성이 점진적으로 감소하며, 학습률이 비교적 균일하게 유지되었다. 이는 합리적인 태스크 컨트롤 전략의 결과로, 매 순간 가장 불확실성이 높은 S-O 페어를 제시하도록 설계되었기 때문이다. 결과적으로 참가자는 인과 관계를 점진적으로 학습하며, Bayesian 모델의 특성에 맞게 최적의 학습 과정을 따르게 된다.
Figure 2E는 Oneshot+ 모델의 태스크 컨트롤 전략에 따라 최적화된 S-O 시퀀스이다. 학습의 후반부에서 S-O 불확실성과 학습률이 급격하게 변화하는데, 초반에는 불확실성이 고르게 유지되지만, 후반부에 들어서면서 급격한 불확실성 해소가 발생한다. 특히 태스크 컨트롤러가 학습 초반에 인위적으로 S-O 불확실성을 불균등하게 조정하는 특징이 나타난다. 학습 과정에서 특정 S-O 페어는 거의 학습되지 않은 상태를 유지하고, 이후 후반부에 급격한 학습이 이루어지는 패턴을 보이는데 이러한 전략은 Oneshot 학습의 핵심적인 특징을 반영한 것으로, 특정 시점에서 한 번의 학습으로 빠르게 인과 관계를 확립하도록 유도하는 방식이다.
Figure 2F는 Oneshot- 모델의 태스크 컨트롤 전략에 따라 최적화된 S-O 시퀀스이다. Oneshot+ 모델과는 정반대로, 태스크 컨트롤러가 불확실성이 낮은 S-O 페어를 계속해서 제시한다. 이로 인해 대부분의 S-O 페어에서 인과 불확실성이 충분히 감소하지 않는 현상이 나타나며 태스크 컨트롤러가 의도적으로 학습을 방해하는 전략을 취한다. 결과적으로 참가자가 새로운 인과 관계를 학습하기 어려운 구조를 형성한다. Oneshot– 모델은 Oneshot 학습을 억제하기 위한 설계로, 특정 S-O 페어에 대한 학습률을 낮추는 방식으로 구현되었다.
Figure 2H에서는 태스크 컨트롤 정책에 따라 S-O 페어가 제시되는 횟수에 차이가 있음을 보여준다. Oneshot+ 조건에서는 특정 S-O 페어가 더 자주 또는 덜 자주 제시되는 반면 Bayesian+ 조건에서는 모든 S-O 페어가 거의 동일한 빈도로 제시됨. 이는 단순한 우연이 아니라, 인과적 복잡성(causal complexity)과 관련된 현상이다.
Figure 2I에서 연구진은 각 S-O 페어의 연결성 정도와 S-O 페어 제시 횟수의 관계를 분석하였다. Bayesian+ 조건에서는 모든 S-O 페어가 거의 동일한 횟수로 제시되어 태스크 컨트롤러는 모든 인과 관계를 고르게 학습하도록 설계된 것을 알 수 있다. Oneshot+ 조건에서는 연결성이 높은(high degree) S-O 페어가 더 자주 제시되며, 이는 태스크 컨트롤러가 특정 페어를 집중적으로 학습시키려는 전략을 취했음을 알 수 있다.
Figure 2J는 연결성 정도와 학습률의 관계를 나타낸 것이다. 결과적으로, Bayesian+과 Oneshot+이 서로 다른 학습 패턴을 유도함을 확인하였다. Bayesian+ 조건에서는 모든 S-O 페어에서 학습률이 일정하게 유지되었으나 Oneshot+ 조건에서는 연결성이 높은 페어에서 학습률이 더 빠르게 증가하며, 후반부에 급격한 학습 효과가 나타났다.
Task Control을 통한 인과 학습 태스크 생성 (Causal learning tasks generated by task control)
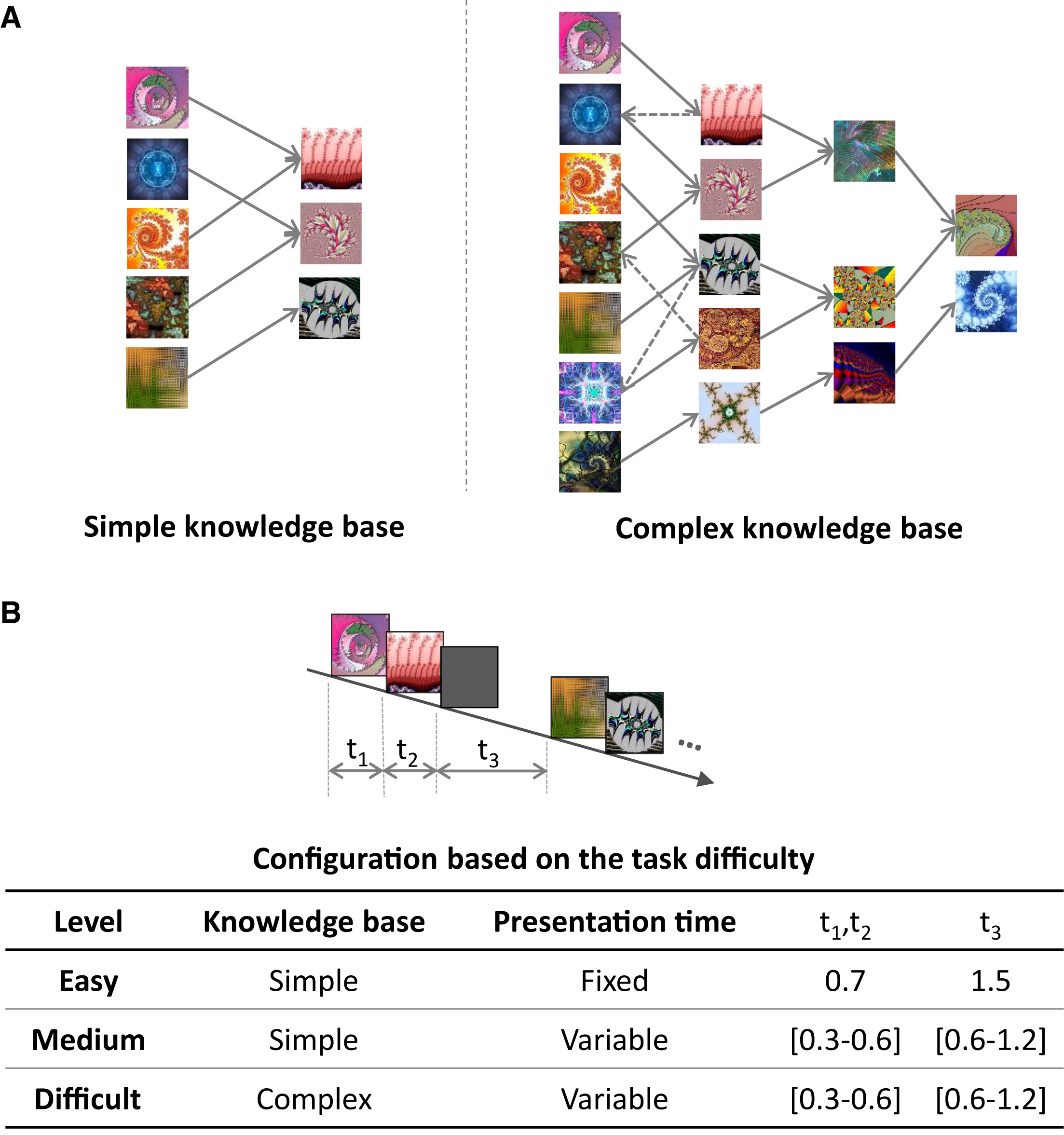
연구에서는 태스크 컨트롤러가 인간의 인과 추론을 조절할 수 있는지를 검증하기 위해, 태스크 컨트롤러를 이용하여 새로운 인과 학습 태스크를 생성하였다. 이를 위해 두 가지 유형의 지식 베이스(Knowledge Base, KB)를 이용, 실험 난이도를 조절하여 3개 난이도의 실험을 구성하였다. 자세한 실험의 구조는 이전 포스트를 참고하고, Figure 3A는 실험에서 사용한 이미지셋 베이스의 형태를 나타낸 것이다. 3B는 난이도에 따른 사용한 이미지셋, 그리고 자극을 보여준 시간이 유동적/고정인지, S-O가 보여진 시간, 간격 시간을 순서대로 나타낸 표이다.
태스크 컨트롤이 수행 성과 및 학습 효율성에 미치는 영향
총 126명의 성인 참가자(여성 65명, 연령 범위: 18~56세)가 실험에 참여하였다. 참가자는 실험 난이도에 따라 세 그룹으로 나뉘었으며, 쉬운 태스크(Easy) 48명 (여성 29명, 연령 범위: 19~56세), 중간 난이도 태스크(Medium) 42명 (여성 19명, 연령 범위: 18~33세), 어려운 태스크(Difficult) 36명 (여성 17명, 연령 범위: 18~37세)구성하였다. 이 연구에서는 4가지 평가 지표를 활용하여 태스크 컨트롤이 인과 학습 성과에 미치는 영향을 분석하였다.
태스크 수행 성과를 평가하기 위해 사용된 4가지 주요 지표는 다음과 같다. 인과 평가 점수 (Causal Rating), 테스트 점수 (Test Score), 학습 효율성 (Learning Efficiency), 태스크 컨트롤의 효과 크기 (Effect Size of Task Control)이다. 각 지표에 대한 설명은 이전 포스트를 참고하기 바란다.
연구자들은 태스크 컨트롤이 참가자의 인과 평가 패턴을 어떻게 변화시키는지를 시각적으로 분석하기 위해, t-SNE (t-Distributed Stochastic Neighbor Embedding) 기법을 사용하여 참가자의 원시 신뢰도 점수를 저차원 공간으로 투영하였다(Figure 4A).
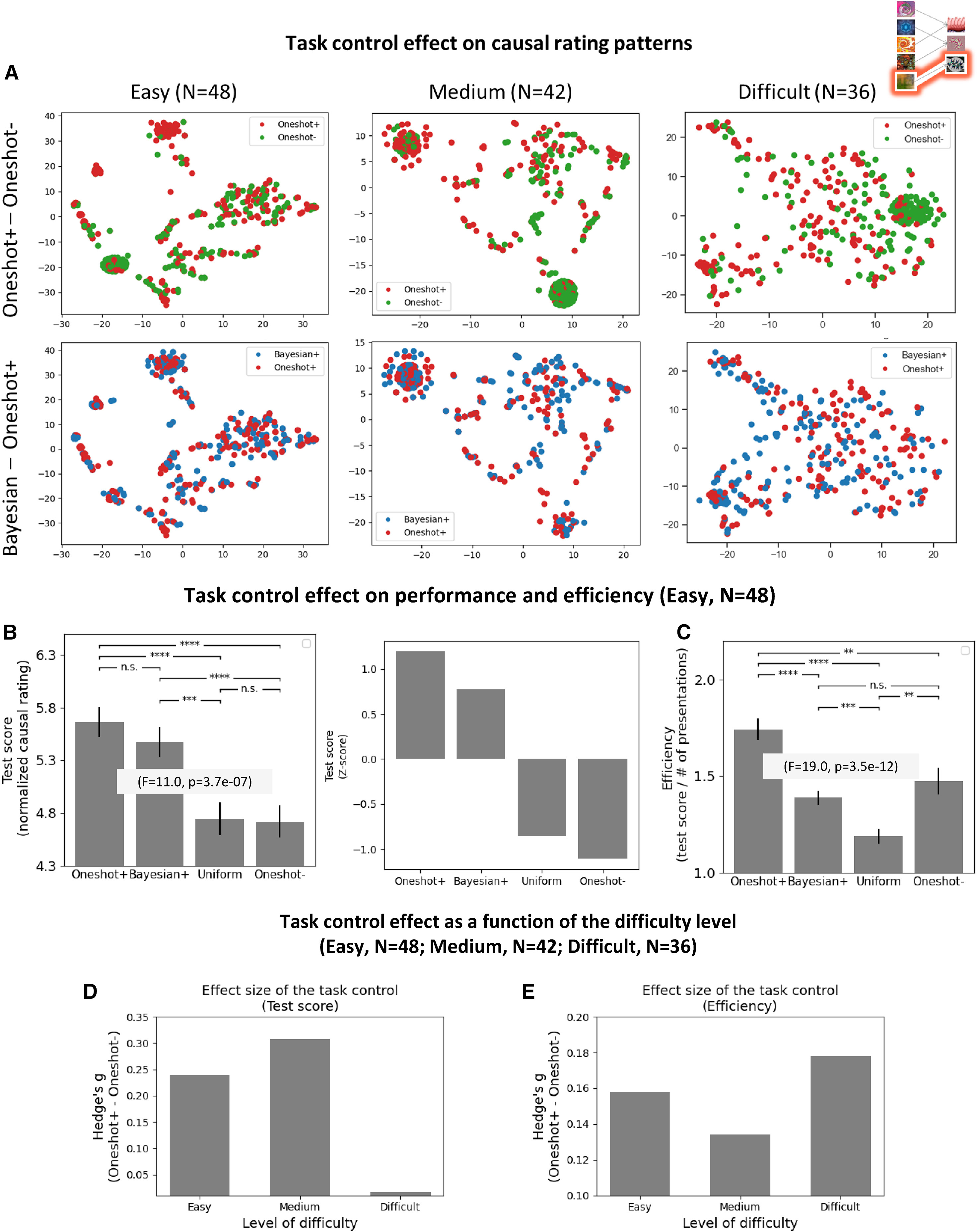
결과적으로, Oneshot+ 조건과 Oneshot– 조건 간의 인과 평가 패턴이 명확하게 구분됨을 확인하였하지만, 어려운 태스크(Difficult Task)에서는 이 효과가 덜 뚜렷하게 나타났다. Oneshot+ 및 Bayesian+ 조건은 유사한 인과 평가 패턴을 보였으며(Figures S10, S13; PCA 분석 결과), 이는 두 조건이 모두 효율적인 학습을 유도하는 역할을 했음을 시사한다.
이후 태스크 컨트롤이 참가자들의 태스크 수행 성과를 향상시키는지 여부를 분석하기 위해 실험 결과를 비교하였다.(Figure 4B)
쉬운 태스크와 중간 난이도 태스크에서 Oneshot+와 Bayesian+ 조건의 테스트 점수가 Oneshot– 조건보다 유의미하게 높게 나타났다. 이 차이는 통계적으로도 유의미한 수준으로 확인되었으며 (p < 1e–4, 대응 표본 t-test), Uniform 조건보다도 높은 점수를 기록하였다 (p < 1e–4, t-test). 표준 테스트 점수(평균 및 표준 편차 포함) 분석에서도, Oneshot+ > Bayesian+ > Uniform > Oneshot– 순서로 효과 크기가 정렬되었다. 이러한 결과는 태스크 컨트롤이 참가자들의 인과 학습 수행을 효과적으로 조절할 수 있음을 실험적으로 입증하는 근거가 된다. 태스크 컨트롤이 제공하는 최적화된 학습 경로를 통해 참가자들은 보다 효과적으로 인과 관계를 학습할 수 있었으며, 이는 Oneshot+와 Bayesian+ 조건에서 더욱 두드러지게 나타났다.
태스크 컨트롤이 참가자의 학습 효율성을 증가시킬 수 있는지를 분석한 결과, 매우 강력한 효과가 관찰되었다. (Figure 4C) Oneshot+ 조건의 학습 효율성이 Oneshot– 조건보다 유의미하게 높았으며 (p < 1e–2, 대응 표본 t-test), Uniform 조건보다도 높은 학습 효율성을 보였다 (p < 1e–4, t-test). 이는 태스크 컨트롤이 참가자의 학습을 최적화된 학습 경로로 유도하여, 최소한의 관찰로 최대한의 정보를 획득할 수 있도록 조정했음을 시사한다.
특히, Oneshot+ 조건의 학습 효율성은 Bayesian+ 조건보다도 유의미하게 높게 나타났으며 (p < 1e–4, 대응 표본 t-test), 이는 인간이 학습 효율성을 극대화하기 위해 원샷 학습(One-shot Inference)을 적극적으로 활용한다는 기존 연구 결과를 뒷받침한다. 태스크 컨트롤을 적용했을 때 참가자는 주어진 자극-결과(S-O) 관계를 더 적은 노출 횟수만으로 효과적으로 학습할 수 있었으며, 이는 학습 효율성 측면에서 태스크 컨트롤이 강력한 도구로 작용함을 의미한다.
태스크 컨트롤의 효과가 난이도에 따라 어떻게 달라지는지를 분석한 결과, (Figures 4D, 4E) 쉬운 태스크 및 중간 난이도 태스크에서는 강력한 태스크 컨트롤 효과가 존재하는 것으로 나타났다. 반면, 어려운 태스크에서는 태스크 컨트롤 효과가 다소 감소하는 경향을 보였다.
한편, 학습 효율성(Figure 4E)은 모든 난이도에서 높은 수준(>0.15)의 효과 크기를 유지하였다. 이는 태스크 컨트롤이 난이도와 관계없이 효율적인 학습 경로를 제공하여 참가자의 학습 효율성을 극대화할 수 있음을 의미한다. 또한, 태스크 컨트롤 효과 크기는 지식 베이스(KB)의 인과적 복잡성(Causal Complexity)에 따라 달라질 수 있으며, 난이도가 증가한다고 반드시 선형적으로 증가할 필요는 없다는 점도 확인되었다.
참가자-모델 적합성(Subject-Model Compatibility) 분석
태스크 컨트롤의 효과는 인지 모델(cognitive model)과 인간 참가자의 학습 스타일 간의 적합성(subject-model compatibility)에 따라 달라질 수 있다. 이를 검증하기 위해 사후 분석(post hoc analysis)을 수행하였으며, 참가자의 원샷 추론 편향(one-shot inference bias)에 따라 태스크 컨트롤 효과가 어떻게 변화하는지를 비교하였다(Figure 5).
분석의 핵심 목표는 인지 모델과 참가자의 학습 스타일이 얼마나 유사한지에 따라 태스크 컨트롤이 다르게 작용하는지를 확인하는 것이다. 특히, 참가자의 원샷 추론 성향이 강할수록(Oneshot+ 모델과 유사할수록) 태스크 컨트롤 효과가 더 크게 나타나는지를 중점적으로 분석하였다.
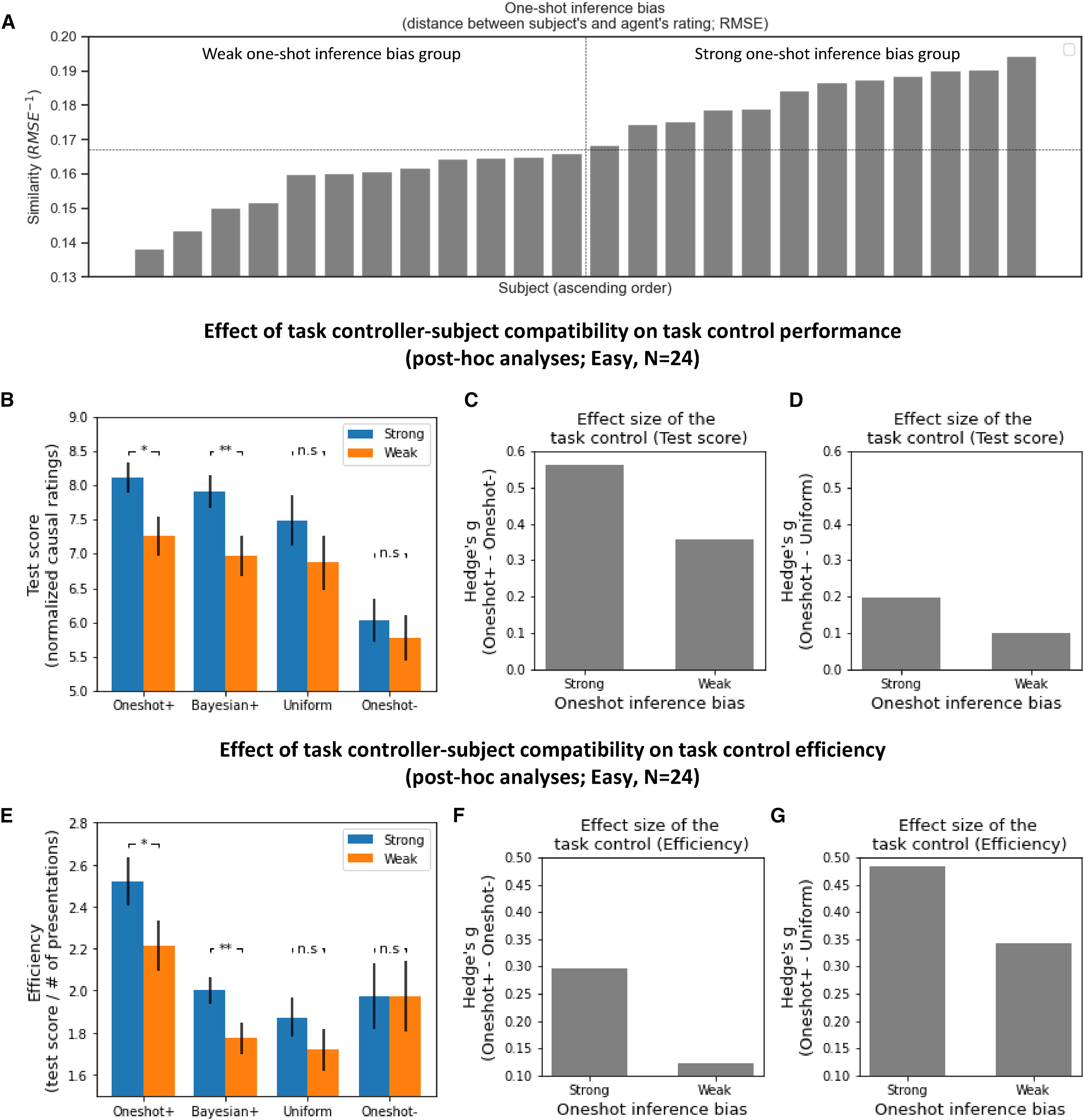
원샷 추론 편향(One-Shot Inference Bias) 측정 (Figure 5A)
개별 참가자의 원샷 추론 편향(one-shot inference bias)은 Oneshot+ 조건에서 사용된 인과 추론 모델과 참가자의 인과 평가 점수 패턴 간의 유사도로 정의된다. 구체적으로, 참가자의 인과 평가 점수와 Oneshot+ 모델의 점수 간의 평균제곱근오차(RMSE, Root-Mean-Square Error)를 계산한 뒤, 그 역수를 유사도 값으로 사용하였다.
이를 통해 참가자를 원샷 추론 편향이 강한 그룹(strong one-shot inference bias group, 상위 50%)과 약한 그룹(weak one-shot inference bias group, 하위 50%)으로 나누었다(Figure 5A). 즉, 원샷 추론 편향이 강한 그룹은 Oneshot+ 모델과의 유사도가 높은 참가자들이며, 반대로 약한 그룹은 모델과의 유사도가 낮은 참가자들이다.
강한 및 약한 원샷 추론 편향 그룹에서의 테스트 점수 비교 (Figure 5B)
Figure 5B는 참가자의 테스트 점수를 네 가지 태스크 컨트롤 조건(Oneshot+, Bayesian+, Uniform, Oneshot–)에 따라 비교한 결과를 보여준다. x축은 태스크 컨트롤 조건을, y축은 해당 조건에서의 평균 테스트 점수를 나타낸다.
분석 결과, 테스트 점수는 Oneshot+ > Bayesian+ > Uniform > Oneshot–의 순서로 높게 나타났다. 특히, 원샷 추론 편향이 강한 그룹에서 Oneshot+ 조건의 테스트 점수가 가장 높았으며, 원샷 추론 편향이 약한 그룹에서는 이러한 효과가 상대적으로 덜 두드러졌다.
이러한 결과는 참가자가 Oneshot+ 모델과 유사한 학습 성향을 가질수록 태스크 컨트롤 효과가 더 크게 나타난다는 것을 의미한다.
태스크 컨트롤 효과 크기 비교 (테스트 점수 기준)
태스크 컨트롤의 효과 크기(effect size)는 Oneshot+ 조건과 다른 조건 간의 테스트 점수 차이로 측정되었다. Figure 5C는 Oneshot+와 Oneshot– 조건 간의 테스트 점수 차이를 비교한 결과를 보여주며, Figure 5D는 Oneshot+와 Uniform 조건 간의 테스트 점수 차이를 비교한 결과를 보여준다. 분석 결과, 원샷 추론 편향이 강한 그룹에서 태스크 컨트롤 효과 크기가 약한 그룹보다 약 2배 더 크게 나타났다. 이는 태스크 컨트롤이 참가자의 학습 성향과 더 잘 맞을수록, 더 효과적으로 작용할 수 있음을 시사한다.
태스크 컨트롤 효과 크기 비교 (학습 효율성 기준)
Figure 5E–5G는 앞서 설명한 테스트 점수 비교 분석을 학습 효율성(learning efficiency) 기준으로 다시 수행한 결과이다. Figure 5F는 Oneshot+와 Oneshot– 조건 간의 학습 효율성 차이를 비교한 결과를 보여주며, Figure 5G는 Oneshot+와 Uniform 조건 간의 학습 효율성 차이를 비교한 결과를 보여준다.결과적으로, 테스트 점수 분석과 유사하게 원샷 추론 편향이 강한 그룹에서 태스크 컨트롤 효과가 더 크게 나타났다. 특히, Oneshot+ 조건에서의 학습 효율성이 가장 높았으며, Oneshot– 조건에서 가장 낮았다.
이러한 결과는 태스크 컨트롤이 참가자의 학습 패턴을 최적화하는 데 기여하며, 특히 원샷 추론 성향이 강한 참가자들에게 가장 효과적으로 작용한다는 점을 뒷받침한다.
Discussion
이 연구에서는 딥러닝 기반 강화학습(Deep Reinforcement Learning, RL) 및 신경과학적 강화학습 원리를 적용하여 인간의 인지 과정을 제어할 수 있는 계산적 프레임워크를 제안하였다. 연구에서 제안된 태스크 컨트롤러(Task Controller)는 2인 게임(two-player game) 설정을 기반으로 설계되었으며, 신경 및 행동 데이터를 설명하는 인간 인과 추론 모델과 상호작용하면서 학습하는 신경망 모델이다.
태스크 컨트롤러는 순수한 컴퓨터 시뮬레이션 환경에서 학습되기 때문에, 인간 참가자를 직접 훈련 과정에 포함할 필요가 없으며, 다양한 실험 디자인을 보다 쉽게 생성하고 최적화할 수 있는 장점이 있다.
- 태스크 컨트롤러가 학습한 인과 관계 조절 능력
태스크 컨트롤러는 인간 인과 추론 모델과의 상호작용을 통해 인과 불확실성(causal uncertainty)을 효과적으로 조절하는 태스크 컨트롤 정책(task control policy)을 학습한다. 연구에서는 이러한 학습 과정을 시각적으로 확인하기 위해 인간 인과 추론 모델의 잠재 공간(latent space) 변화를 시각화하였다(Figure 2).
그 결과, 태스크 컨트롤러는 과제 환경의 인과적 복잡성(causal complexity)을 반영하여 학습 목표에 따라 서로 다른 태스크 컨트롤 정책을 개발하는 것으로 나타났다.
- 인간 참가자를 대상으로 한 태스크 컨트롤러의 검증
컴퓨터 시뮬레이션을 통해 학습된 태스크 컨트롤러의 효과는 126명의 인간 참가자를 대상으로 한 실험을 통해 검증되었다(Figure 4). 실험 결과, 태스크 컨트롤러는 인간의 인과 추론 과정에 내재된 특성을 반영하며(Figure 5), 인간 참가자의 학습 과정을 조절할 수 있는 능력을 보였다.
특히, 단순한 실험 설계만으로도 목표 행동(target behavior)을 유도할 수 있을 것으로 보이지만, 이를 일반화하는 것은 쉽지 않다. 즉, 기존 실험 설계에서는 참가자 행동의 변동성(variance)을 효과적으로 통제하기 어렵고, 새로운 환경에서 동일한 목표 행동을 유도할 방법이 부족하다. 그러나 태스크 컨트롤러를 활용하면, 목표 행동을 효과적으로 유도하는 최적의 실험 디자인을 생성할 수 있으며, 새로운 실험 환경에서도 보다 정밀한 조절이 가능하다.
- 딥러닝 기반 강화학습(RL)과 기존 연구와의 차별점
이 연구는 기존 연구들과 비교했을 때 몇 가지 중요한 차별점을 갖는다.
(1) 태스크 컨트롤러의 역할 확장
기존 연구에서는 강화학습(RL)을 활용하여 인간 의사결정을 방해(adversary)하는 모델을 생성하는 방식이 많았다. 예를 들어, Bak et al.(2020) 연구에서는 최적의 동물 학습 규칙을 찾기 위한 시뮬레이션 모델을 개발하였고, 또 다른 연구에서는 강화학습 알고리즘을 이용하여 인간 의사결정을 방해하는 적대적 환경을 생성하는 방식을 사용하였다.
그러나 본 연구에서는 태스크 컨트롤러를 단순한 적대적(adversarial) 역할이 아니라, 다양한 학습 방식을 유도하는 도구로 활용할 수 있도록 확장하였다. 특히, 태스크 컨트롤러는 목표 지향적 학습(goal-directed learning)을 조절할 수 있으며, 환경 내 인과 구조를 활용하여 보다 정교한 학습을 유도할 수 있다.
(2) 태스크 컨트롤 프레임워크의 범용성
기존 연구들은 주로 의사결정(Decision-making) 문제에 초점을 맞추었으나, 본 연구의 태스크 컨트롤러는 실험 설계의 다양한 매개변수(parameterized task space)를 조절할 수 있는 특징이 있다.
즉, 본 연구에서 제안된 태스크 컨트롤 프레임워크는 다양한 실험 패러다임(experimental paradigms) 및 신경학적 모델과도 호환될 수 있다. 이로 인해, 학습 모델이 특정한 인간 의사결정 패턴에 과적합(overfitting)될 가능성을 줄이고, 보다 일반적인 학습 환경에서도 적용 가능하다.
(3) 학습 모델의 일반화 성능 향상 기존 연구에서는 데이터 기반(data-driven) 방식으로 학습자 모델을 구축하였기 때문에 특정 실험 환경에 과적합될 위험이 컸다. 반면, 본 연구에서는 독립적인 데이터셋을 이용하여 학습된 인과 추론 모델을 사용하였으며, 이 모델이 신경 데이터를 설명할 수 있음을 사전에 검증하였다. 따라서, 태스크 컨트롤러가 특정 실험 환경에 과적합되지 않고, 보다 다양한 환경에서도 효과적으로 작동할 수 있도록 설계되었다.
- 태스크 컨트롤의 확장 가능성: 인지 치료 및 공학적 응용
제안된 태스크 컨트롤 프레임워크는 인지 행동 치료(cognitive behavioral therapy) 및 공학적 응용(engineering applications)에도 활용될 가능성이 있다.
(1) 인지 행동 치료에서의 응용 가능성
태스크 컨트롤 정책을 활용하면 새로운 인지 훈련 원칙을 개발하거나 기존 치료 방법을 보완할 수 있다. 예를 들어, 학습 효율성을 높이는 태스크 컨트롤 → 참가자의 학습 능력을 향상시키는 데 사용될 수 있다. 학습 난이도를 조절하는 태스크 컨트롤의 경우 동기부여(motivation control) 역할을 하거나, 트라우마 기억을 억제하는 치료 방법에 적용 가능하며, 성공적인 학습과 불필요한 정보 억제 학습을 결합하여 환자가 중요한 정보를 빠르게 학습하면서도 불필요한 정보를 억제할 수 있도록 설계 가능하다.