
Neural computations underlying arbitration between model-based and model-free learning
우리의 뇌에는 행동 선택을 조절하는 두 가지 시스템, model-based와 model-free 시스템이 존재한다는 신경학적인 증거가 존재한다. 하지만 특정한 순간에, 어떤 시스템이 행동을 주도하는지에 대한 메커니즘은 정확하게 밝혀진 바가 없다. 본 논문에서는 두 모델 사이의 중재(arbitration) 메커니즘이 존재하며, 각 시스템의 신뢰도(reliability)에 따라 행동 제어 비율을 할당한다는 증거를 제시하고 있다. 이러한 arbitration system은 model-based system의 제어 정도에 따라 model-free system과의 connectivity를 negative direction으로 조절하는 것으로 밝혀졌는데, 즉 arbitrator가 model-based system을 신뢰할 경우 model-free system의 영향력을 감소시키는 방향으로 행동을 조절할 수 있다는 것이다.
Introduction
개체의 행동을 조절하는 두 가지 경쟁적 시스템이 존재하는 것은 오래 전부터 알려진 사실이지만 두 시스템 간 제어가 어떻게 전환되는지에 대한 연구는 부족하다. 두 시스템은 goal-directed, habitual으로, 각각 prefrontal cortex, anterior striatum/posterior lateral striatum과 연관되어 있다고 알려져 있다. 가령 약물 중독같은 경우 goal-directed system과 habitual system 같의 균형이 무너져 약물과 관련된 stimulus-response habit이 억제되지 못해 일어나는 현상일 수 있다는 것이다. 저자들은 RL framework를 활용해서 goal-directed system의 경우 model-based RL(환경에 대한 내부 모델을 활용해 행동의 가치를 실시간으로 계산), habitual system의 경우 model-free RL(시행착오를 통해 행동의 보상을 학습)을 활용하여 디자인하고, 인간의 뇌에서 arbitration process가 어떻게 작동하는지 기제를 규명하는 것을 목표로 한다.
Computational model of arbitration
본 논문에서 제안하는 arbitration 시스템은 세 가지 layer 1)model-based/model-free RL, 2)reliability estimation, 3)reliability competition 으로 구성된다. 첫 번째 단계에서는 MB, MF agent가 각각 state-prediction error(SPE), reward-prediction error(RPE)를 계산하여 학습한다. 이후 각 시스템이 환경을 얼마나 정확하게 예측하는지 계산한다. MB system의 SPE의 경우 값이 0에 가까울수록 정확하며, MF system의 RPE의 경우 값이 작을수록 보상 예측이 정확하다. MB system의 경우 bayesian framework를 이용하여 추론하나, MF system의 경우 RPE를 추정하기 위해 더 단순한 시스템을 사용할 수도 있다. 이후 두 신뢰도 지표가 경쟁하여 PMB(MB system이 선택될 확률)를 결정하며, PMB가 높으면 MB system이 행동을 주도하고 낮으면 그 반대가 되는 방식이다. 두 시스템 간 제어는 이분법적이 아닌 동적 가중치로 조절된다.
Markov Decision Task
저자는 arbitration model의 행동 조절 메커니즘을 검증하기 위해서 decision task를 설계하였다. 이 실험은 MDP를 기반으로 하며 공통적인 컨셉은 참가자는 binary choice를 통해 토큰을 선택하며, 이 토큰은 금전적 보상으로 교환이 가능하다는 것이다.
실험 디자인 1. 조건
이 실험은 두 가지의 조건으로 나뉜다. 즉 서로 다른 통제 조건의 실험 디자인이라고 할 수 있다. 하나는 특정 목표 조건, 다른 하나는 유연한 목표 조건이다. 특정 목표 조건에서는 한 가지 색상의 토큰만 보상이 주어지며, 다른 토큰은 금전적으로 무효한 것이 된다. 보상이 가능한 색상은 매 라운드마다 바뀌며, 특정 색상의 토큰만 유효하기 때문에 실험은 환경의 변화를 실시간으로 고려해야 하는 참가자를 MB system으로 행동하게끔 유도한다. 이 통제 조건에서는 MF system의 RPE가 높아지는 경향성을 보인다.
다른 디자인인 유연한 목표 조건에서는 어떤 색상 토큰이라도 금전적 보상을 취할 수 있으며, 참가자에게 MF system으로의 의존을 유도한다. 특정 목표가 변하지 않기 때문에 경험에 의존하는 습관적 행동을 유도하는 것이 핵심이다.
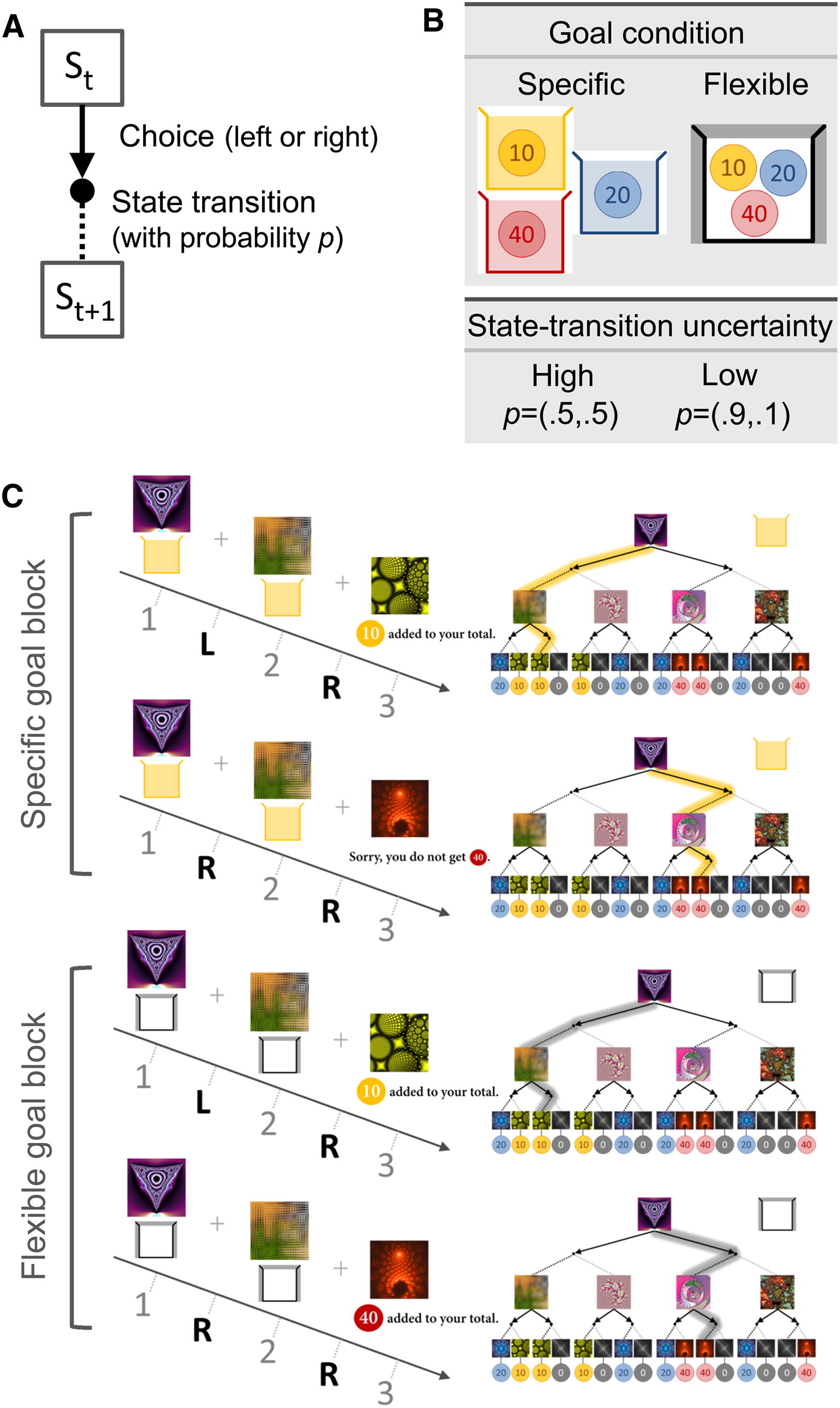
실험 디자인 2. 전이 확률
실험에서는 상태 전이 확률을 조작하여 시스템간의 전환을 유도한다. 예를 들어 전이 확률이 0.5라면 어떤 선택지를 선택해도 상태가 바뀔 확률은 반반이다. 즉 참가자로 하여금 예측이 어려운 상황을 유도하며, MF system이 유리하게 된다. 반대로 전이 확률이 0.1이라면 예측이 쉽기 때문에 MB system이 유리하다.
실험 과정 동안 총 22명의 성인 참가자가 참여하였으며, 실험동안 fMRI로 뇌 활동을 측정하였다.
행동학적 결과들
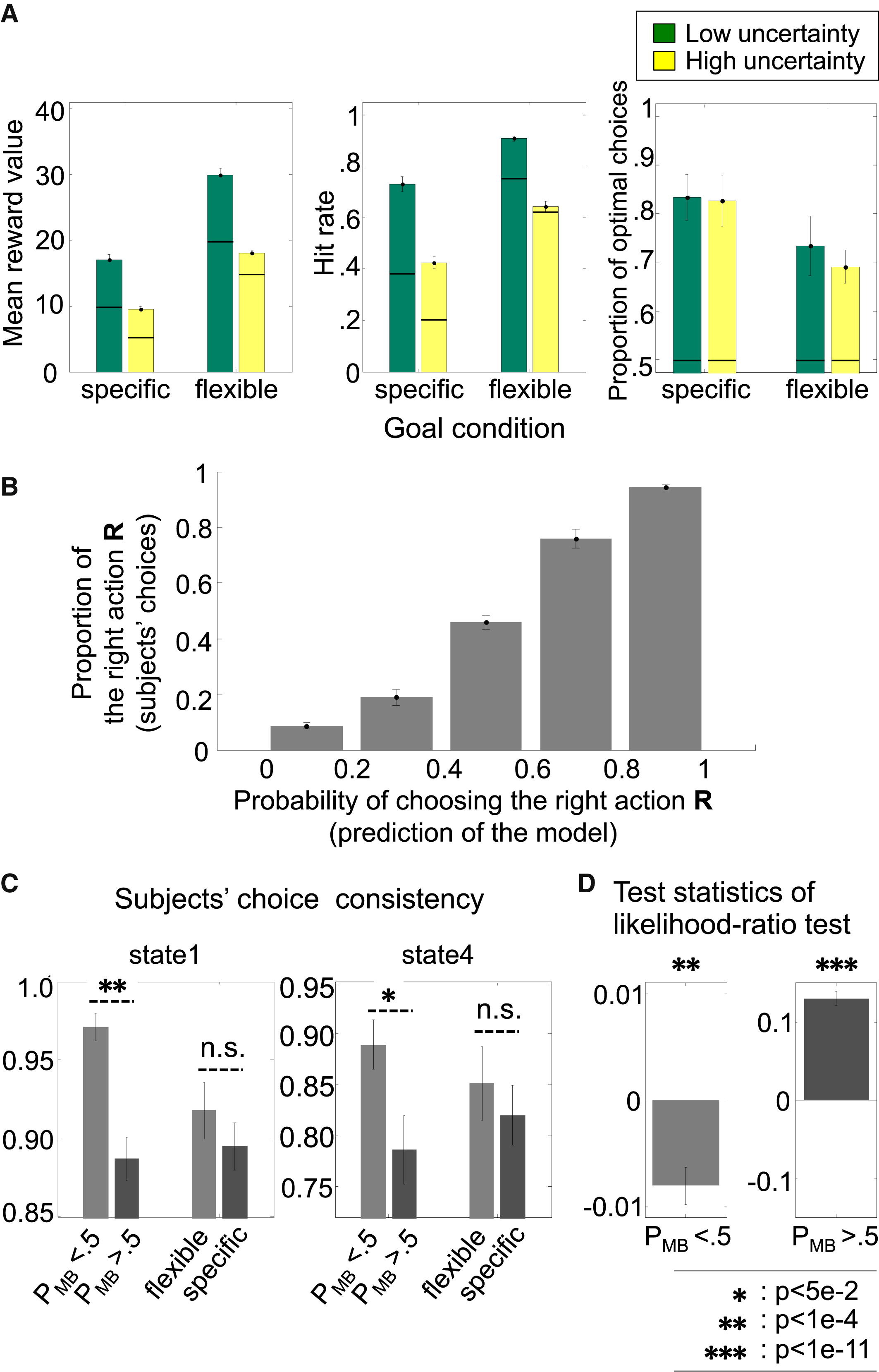
결과를 깊게 분석하기 전 참가자들의 행동학적 결과에 대해 알아보겠다. 일단 모든 참가자들은 실험을 성공적으로 수행하였다. 참가자들의 성과를 알아보기 위해 GLM(generalized linear model) 회귀분석을 수행하였다. 일단 목표 조건이 참가자의 성과에 유의미한 영향을 미쳤다. 목표 조건의 종류에 따라 평균 보상 값이 확실히 차이가 났으며, 불확실성이 클수록 전반적인 성과가 떨어짐도 관찰되었다. 또한 상태 전이의 불확실성은 특정 목표 조건에서 더 큰 영향을 미쳤다. 즉, MB system이 행동을 주도하는 상황에서 환경의 불확실성이 더 강한 영향을 미친다는 것을 의미한다. 반면 MF system이 주도하는 상황에서는 불확실성에 둔감(영향을 덜 받는다)했다.
Model comparison of arbitration process
저자들은 6개의 arbitration model을 테스트하여 behavioral data를 가장 잘 설명할 수 있는 신뢰도 계산 방식을 찾고자 했다. 전반적으로 dynamical threshold를 포함한 모델이 더 우수한 성능을 보였으며, MB system 제어는 시간이 지날수록 MF 제어로 점직적으로 이동하는 경향을 보였다(아마 computational cost때문인 것으로 보인다). 이 점 때문에 임계점을 적용한 모델이 그렇지 않은 모델보다 나은 성능을 보였다. 결국 MF model의 신뢰도를 어떻게 계산하느냐가 성능에 중요한 영향을 미쳤는데, 이를 알아보기 위해 full baysian과 absolute RPE 근사 방식을 비교했으며 absolute RPE를 사용하는 모델이 더 적합한 것으로 드러났다(mixedArb-dynamic model).
- 최우수 모델: 혼합 중재 모델(mixedArb-dynamic model)
- 차선 모델: 완전 베이지안 모델(dualBayesArb-dynamic model)
- 기준 모델: Daw et al. (2005) 제안 모델(UncBayesArb)
Relationship between Arbitration Model and Choice Behavior
저자들은 arbitration model이 참가자들의 행동 변화를 얼마나 잘 설명하는지 검증하기 위해 여러 분석을 수행했다. 첫 번째 그림은 참가자들이 왼쪽/오른쪽을 선택한 비율을 계산하고, 이를 arbitration model이 예측한 오른쪽 선택 확률과 비교하였다.(figure 3B 참고) 그림에서 볼 수 있듯이 모델은 참가자들의 실제 행동을 잘 예측해내었다.
저자들은 또한 arbitration model이 MB system을 에측하는 경우와 MF system을 에측하는 경우를 비교하였다. 참가자들이 동일한 선택(좌/우)을 유지하는 경향은 일관성이 높은 MF system이라고 간주하였다. arbitrator가 계산한 PMB가 0.5보다 낮을 때는 참가자들이 같은 선택을 반복하는 경향이 강했다. 반대로 PMB가 0.5보다 높을 때에는 참가자들은 선택을 바꾸는 행동이 많았다. 다만 이 행동의 결과를 실험 조건으로 나누어 분석하면 차이를 설명할 수 없었다(figure 3C). 즉 과제 조건만으로는 선택 행동의 변화를 설명할 수 없고, arbitrator의 모델 신뢰도를 직접 고려해야한다는 것이 요지이다. 결과를 보면 state 1,4만 표시되어 있는데 나머지는 상대적으로 낮은 보상을 제공해 샘플링된 횟수가 적어 통계를 내기 어려웠다.
figure D는 참가자의 선택 행동이 MB, MF 중 어느쪽에 의해 더 잘 설명되는지 비교한 결과이다. 저자는 MB model과 MF model을 독자적으로 학습시키고 이를 이용해 모델이 어느 것을 잘 설명하는지 분석하였다. log likelihood ratio는 LLR = log(data/MB) - log(data/MF)로 계산되었고, 값이 양수면 MB, 음수이면 MF model이 더 설명력이 높다는 결론을 얻을 수 있다. arbitrator의 PMB값과 LLR을 연관지어 볼 때 arbitrator의 P는 LLR을 잘 반영하는 것으로 보인다.
Neural Correlates of Arbitration
MB/MF stage 간의 제어에 neural computation을 규명하기 위해서 저자들은 fMRI데이터를 이용해 접근하였다. 먼저 MB/MF system에서 중요한 값인 SPE/RPE의 차이를 확인해서 이전 연구와 일치하는지 검토하였다.
- SPE 신호의 경우 배외측 전전두엽(dorsolateral prefrontal cortex, dlPFC), 두정엽구(intraparietal sulcus, IPS),전측섬피질(anterior insula)
- RPE 신호의 경우 복측 선조체(ventral striatum)
이상으로 이전 연구(Gläscher et al., 2010, McClure et al., 2003; O’Doherty et al., 2003)와 일치하는 것으로 확인되었다. MB system의 SPE가 0일 불확실성은 신뢰도를 측정하는 데 사용될 수 있다. 배내측 전전두엽(dorsomedial prefrontal cortex, dmPFC), 보조 운동 영역(SMA, supplementary motor area), 하두정소엽(inferior parietal lobule, IPL), 시상(thalamus)은 위 값과 음의 상관관계를 보였다. 또한 MF system의 absolute RPE는 미상핵(caudate nucleus)에서 활성화되었다.
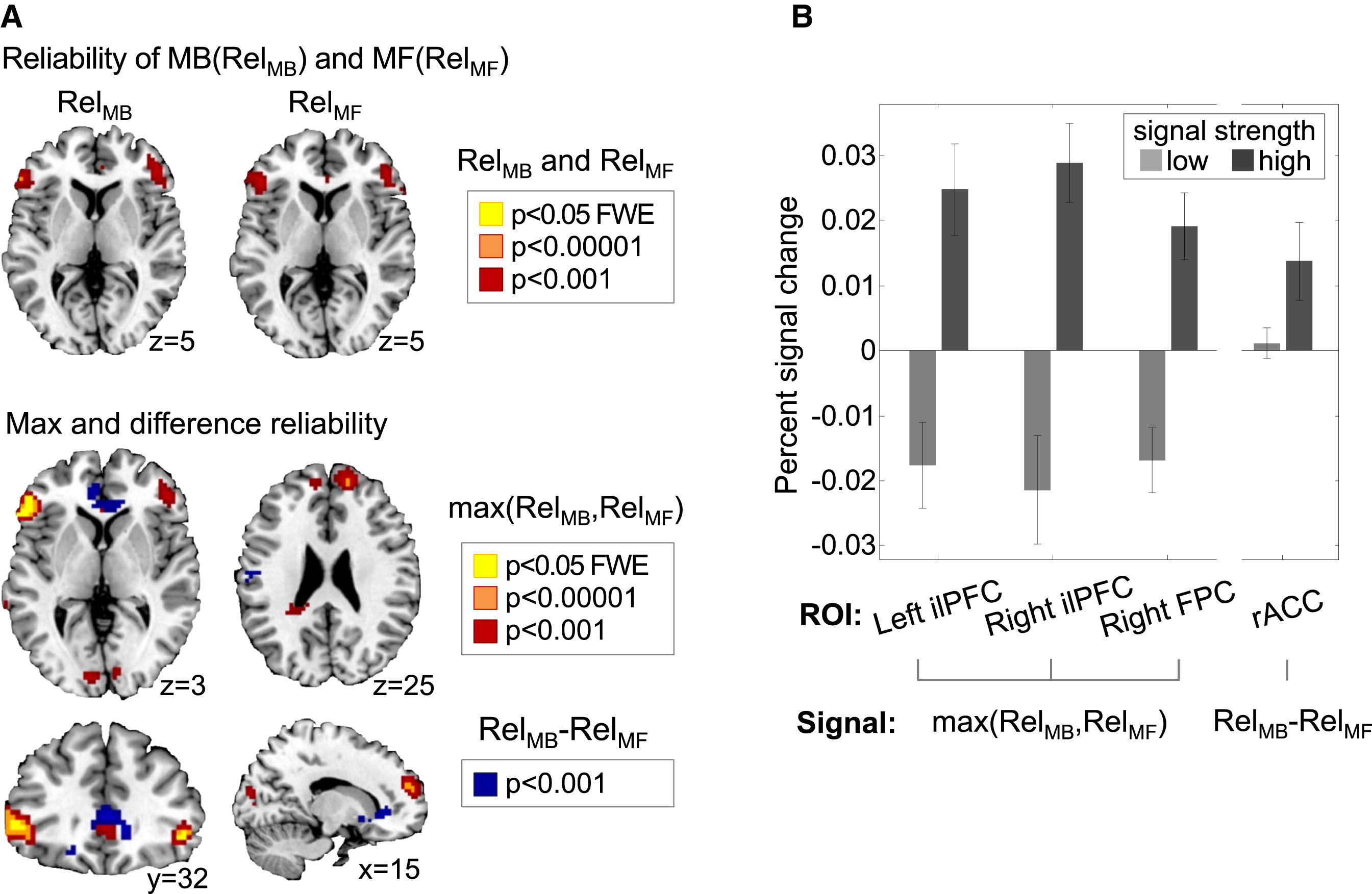
다음은 reliability 계산과 관련된 신경학적인 기전을 알아보았다. 배외측 하전두엽피질(inferior lateral prefrontal cortex, ilPFC)은 MB, MF system의 양쪽 신뢰도 모두와 상관 관계를 가졌다. 하지만 두 신뢰도 중 더 높은 값과 가장 높은 상관관계를 보였다. 위의 첫 번째 그림은 ilPFC의 reliabiltiy signal인데, MB, MF 각각에 대해서 나타나는 것을 볼 수 있다. 또한 두 신뢰도 같의 상관관계는 -0.26으로 낮았으며, 이는 설정한 실험 조건이 MB, MF 학습을 효과적으로 분리할 수 있었음을 시사한다.
A의 아래 그림은 전방 대상회 피질 (rACC)이 신뢰도 차이와 확실한 상관관계를 보이는지 확인한 결과이다. 상황에 따라 MB system이 더 선호될 수도 있고, Mf system이 더 선호받는 경우도 있기 대문에 두 신뢰도의 차와의 상관관계를 살펴보면 어느 시스템이 더 믿을만 한지 평가하는 과정에 관여함을 보일 수 있다. 연구 결과 rACC는 신뢰도 차와 강한 상관관계를 보였다.
Neural Correlates of Model-based and Model-free Value Signals
저자들은 MB system과 MF system의 가치 신호를 계산하는 뇌 영역에 대해 분석하였다. 밑의 그림은 MB, MF의 Q값이 반영된 구역을 나타낸 것이다.
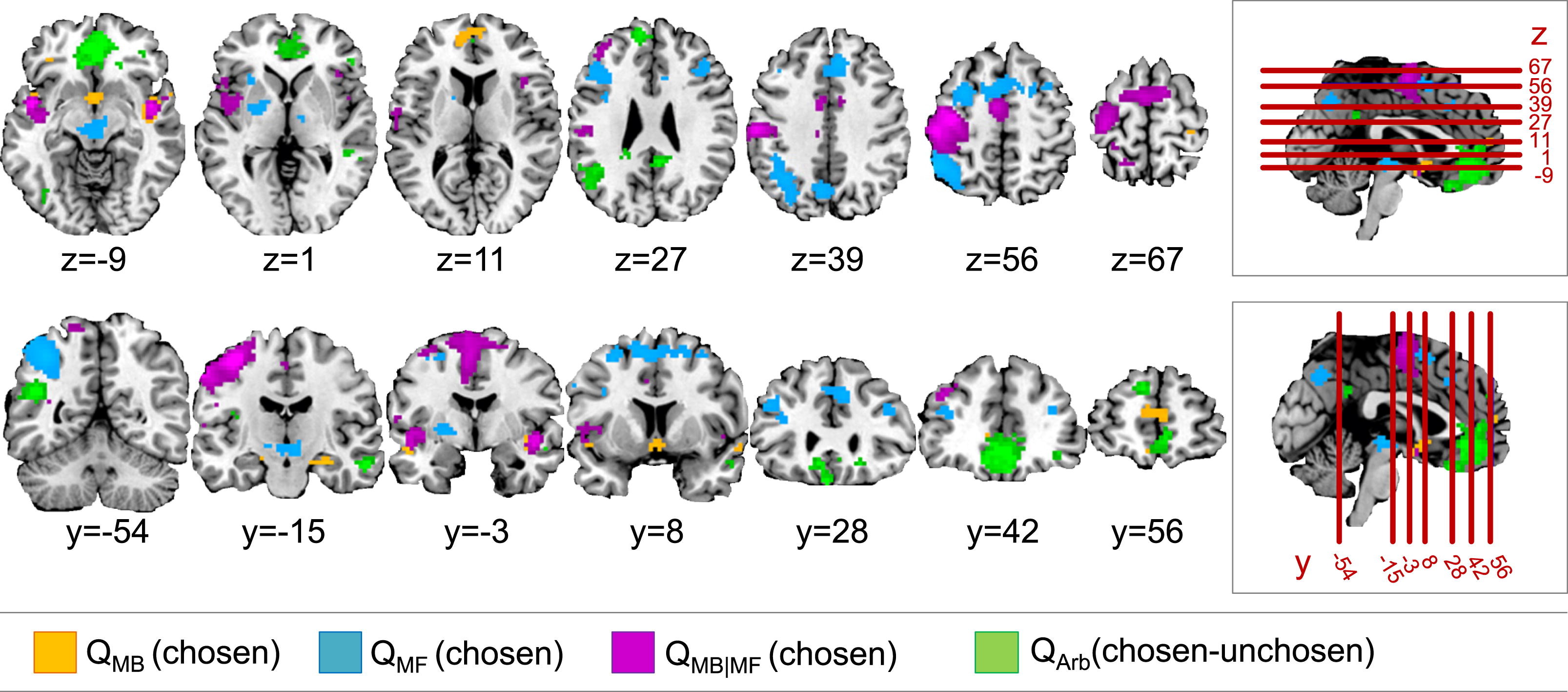
안와 및 내측 전전두엽피질(orbital and medial prefrontal cortex, omPFC)은 MB system에서 행동 가치를 반영하는 핵심 영역으로, 가치 판단과 행동 조절에 중요한 역할을 하는 것으로 보인다. 전방 대상회 피질(anterior cingulate cortex, ACC) 일부 영역은 행동 선택에서 MB learning이 반영하는 가치 신호를 평가하는 과정에 기여한다. 이상의 영역들은 QMB와 강한 상관관계를 보이며, QMF와는 관련이 없었다.
보조운동영역(Supplementary Motor Area, SMA)은 MF dominant한 상황에서 높은 활성을 보였다. 배내측 전전두엽(dmPFC) 및 배외측 전전두엽(dlPFC)은 MF system에서 계산된 행동 가치와 상관관계가 존재했다. 후측 피각(posterior putamen)은 MF learning, 그리고 habitual behavior와 관련된 영역으로, 과거 연구에서도 MF evaluation에 중요한 역할을 한다는 것이 밝혀졌다.
또한 MB, MF 학습 시스템이 공통적으로 가치를 평가하는 뇌 영역도 있었는데, 보조운동영역(SMA) 및 배내측 전전두엽(dmPFC)에서 공통 활성이 관찰되었다. 두 시스템이 함께 행동 선택을 조절할 때 이러한 영역들이 통합적으로 작동할 가능성이 있다. 추가적으로, 저자들은 MB/MF 가치 신호가 weighted integration 방식으로 통합되는 영역을 분석하였다. 복내측 전전두엽 피질(ventromedial prefrontal cortex, vmPFC)에서 유의한 상관관계 발견하였는데, 이전 연구(Boorman et al., 2009; Hare et al., 2009; Rushworth et al., 2011)에서도 vmPFC가 행동 선택에서 가치를 비교하는 데 중요한 역할을 한다는 것이 밝혀진 바 있다. 종합하면 vmPFC는 최종적인 행동 선택을 결정하는 과정에서, 모델 기반과 모델 없는 학습 신호를 가중하여 통합하는 역할을 할 수 있다.
Neural Correlates of Value Integration
이 연구에서 가장 중요한 새로운 발견은 배외측 하전두엽피질(inferior lateral prefrontal cortex, ilPFC)과 우측 전극 전두엽(frontopolar cortex, FPC)이 모델 기반(model-based)과 모델 없는(model-free) 제어 간의 중재(arbitration) 과정에서 신뢰도(reliability) 신호를 포함한다는 것이다. 그러나 중재 과정이 실제로 어떻게 작동하는지 이해하려면, 신뢰도를 인코딩하는 뇌 영역과 모델 기반/모델 없는 시스템에서 가치를 계산하는 뇌 영역 간의 상호작용(interactions)을 분석할 필요가 있다. 이를 위해 연구진은 PPI(Psychophysiological Interaction) 분석을 수행했다. PPI는 특정 뇌 영역 간의 기능적 연결(functional connectivity)이 특정 실험 조건(심리적 변수, psychological variable)에 따라 어떻게 변화하는지를 측정하는 방법이다.
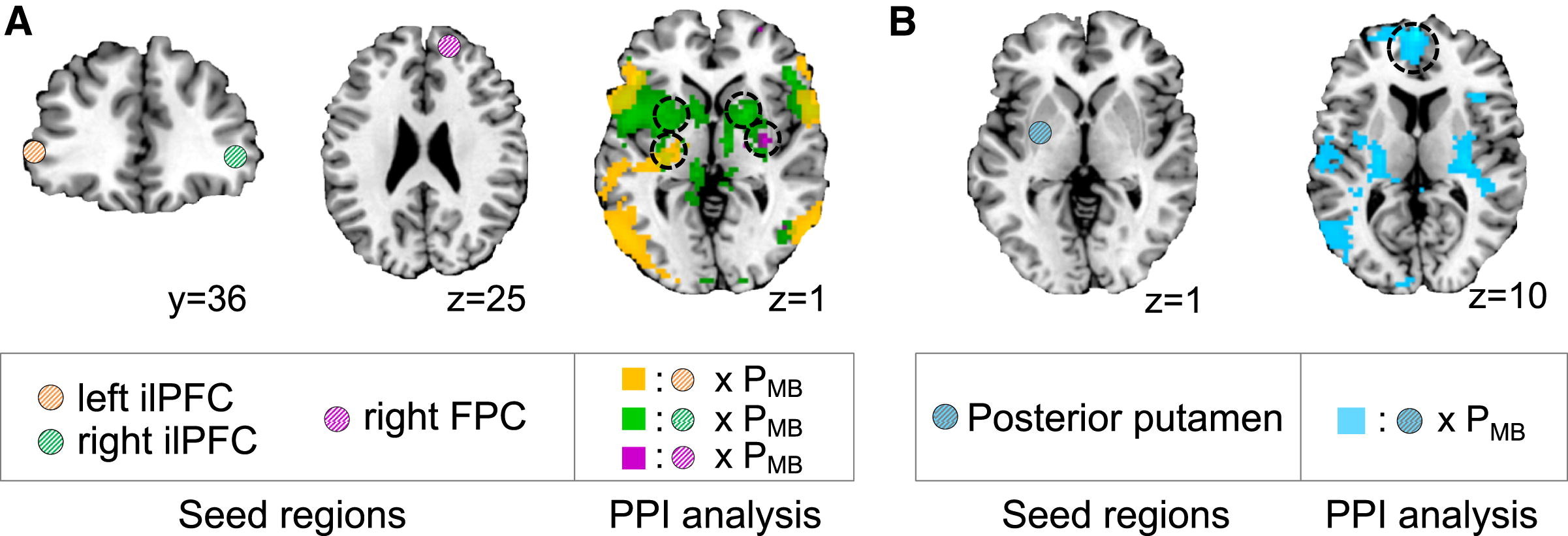
저자들은 ilPFC가 후측 피각(posterior putamen) 및 중간 피각(mid-putamen)과 음의 연결성을 보임을 발견함. 후측 피각(posterior putamen)은 모델 없는 학습에서 행동 가치를 인코딩하며, 보조 운동 피질(supplementary motor area, SMA)은 모델 없는 학습과 습관적 행동(habitual behavior)과 관련된 영역이다. 즉, ilPFC가 활성화될수록, 후측 피각과 SMA의 활동이 감소함을 의미한다. 이러한 음의 상관관계(negative coupling)는 ilPFC가 모델 없는 학습 시스템의 활성도를 억제하는 방식으로 행동을 조절할 가능성을 시사한다.
연구진은 모델 기반 학습이 우세할 때(PMB 값이 높을 때), ilPFC나 FPC가 모델 기반 시스템과 강한 양의 연결성을 보일 것으로 예상하였다. 그러나 모델 기반 시스템과 ilPFC/FPC 간의 유의미한 양의 연결성은 발견되지 않았다. 즉, arbitrator가 모델 기반 시스템을 직접 활성화하는 것이 아니라, 주로 모델 없는 시스템을 억제하는 방식으로 작동할 가능성이 높다. 이는 arbitration 과정이 MB 시스템을 직접 강화하는 방식이 아니라, MF 시스템을 억제하는 방식으로 작동한다는 것을 의미할 수 있다.
연구진은 모델 없는 학습 시스템의 가치 신호가 최종적으로 vmPFC에서 통합될 가능성을 분석하였는데, 후측 피각(posterior putamen)과 복내측 전전두엽 피질(vmPFC) 간의 연결성이 PMB 값에 의해 음의 방향으로 조절되었다. 즉, PMB 값이 높아질수록(모델 기반 학습이 우세할수록), 후측 피각과 vmPFC 간의 연결성이 약해진다는 것이다. PMB 값이 높을 때(즉, arbitrator가 MB system을 선호할 때), 후측 피각에서 vmPFC로 전달되는 모델 없는 가치 신호가 감소하였는데 이는 vmPFC가 최종적인 행동 선택을 내리는 과정에서, arbitrator가 MF system 신호의 기여도를 줄이는 역할을 수행한다는 것을 의미한다.
Discussion
이 연구는 인간의 뇌가 모델 기반(model-based)과 모델 없는(model-free) 학습 시스템을 어떻게 조정하는지를 설명하는 중재 메커니즘(arbitration mechanism)이 존재한다는 증거를 제시했다. 특히, 중재자는 두 학습 시스템의 신뢰도를 평가하고, 더 신뢰도가 높은 시스템이 행동을 조절하도록 결정한다. 연구 결과, 배외측 하전두엽(inferior lateral prefrontal cortex, ilPFC)과 전극 전두엽(frontopolar cortex, FPC)이 신뢰도와 관련된 신경 신호를 포함하고 있음을 확인했다.
- ilPFC는 모델 기반 및 모델 없는 학습의 개별 신뢰도 신호와 함께, 둘 중 더 신뢰도가 높은 시스템을 선택하는 신호를 반영했다.
- FPC는 두 시스템 중 가장 높은 신뢰도를 가진 시스템만을 반영하는 것으로 나타났다.
- 전방 대상회 피질(rostral anterior cingulate cortex, rACC)은 두 시스템 간 신뢰도 차이(RelMB - RelMF)를 반영하는 역할을 했다.
추가적으로, 연구진은 중재자가 행동을 조절하는 방식에 대해 두 가지 가능성을 고려했다. (1. 모델 기반 시스템을 직접 활성화하는 방식, 2. 모델 없는 시스템을 억제하는 방식) fMRI 분석 결과, 중재자는 모델 없는 학습 시스템을 억제하는 방식으로 작동함을 발견했다. 즉, ilPFC가 활성화될수록 후측 피각(posterior putamen)의 활동이 감소하는 패턴을 보였으며, 이는 습관적 행동이 자동적인(default) 방식이므로, 중재자는 특정 상황에서만 습관적 행동을 억제하고 모델 기반 학습을 강화하는 역할을 수행함을 의미한다.
Valuation of Model-based and Model-free Learning System
연구진은 각각의 학습 시스템이 행동 가치를 평가할 때 활성화되는 뇌 영역을 분석하였다. 이를 통해 모델 기반과 모델 없는 시스템이 독립적으로 가치를 평가하는지 확인하고, 최종적으로 이들이 어떻게 통합되는지를 조사했다.
먼저, 모델 기반 학습에서 계산된 가치 신호(QMB)는 복내측 전전두엽 피질(ventromedial prefrontal cortex, vmPFC)에서 강한 신경 활성을 보였다. 이는 vmPFC가 목표 지향적 의사결정과 관련된 영역이며, 모델 기반 학습의 가치 평가를 담당한다는 점을 시사한다. 또한, 이 영역이 모델 기반 가치 신호를 처리하는 것은 이전 연구(O’Doherty, 2011; Wunderlich et al., 2012)에서 보고된 결과와 일치한다.
반면, 모델 없는 학습에서 계산된 가치 신호(QMF)는 후측 피각(posterior putamen)과 보조운동피질(supplementary motor area, SMA)에서 강한 신경 활성을 보였다. 연구진은 습관적 행동이 강화될수록 후측 피각의 활동이 증가하는 경향을 관찰했으며, 이는 이전 연구(Tricomi et al., 2009; Wunderlich et al., 2012)에서 모델 없는 학습의 가치 평가와 관련된 영역으로 보고된 결과와도 일치한다.
추가적으로, 연구진은 vmPFC가 최종적으로 모델 기반과 모델 없는 시스템의 가치 신호를 통합하여 행동을 결정하는 역할을 수행한다고 주장했다. 특히, 중재자의 신호(PMB 값)가 증가할수록 후측 피각과 vmPFC 간의 연결성이 감소하는 것으로 나타났으며, 이는 습관적 행동의 가치 평가가 줄어들고 목표 지향적 행동의 가치 평가가 강화됨을 의미한다.
Computations Involved in Arbitration between Two Learning Systems
연구진은 중재자가 각 학습 시스템의 신뢰도를 어떻게 추정하는지를 분석했다. 분석 결과, 모델 기반 학습의 신뢰도는 Bayesian 방식으로 추정되었다. 상태 예측 오류(SPE, State Prediction Error)를 기반으로 신뢰도를 계산하며, 전두-두정 네트워크(Fronto-Parietal Network)의 Bayesian 추론 방식과 일치하는 결과를 보였다(Gläscher et al., 2010).
반면, 모델 없는 학습의 신뢰도는 보다 단순한 방식으로 추정되었다. 보상 예측 오류(RPE, Reward Prediction Error)의 절대값을 평균하여 신뢰도를 계산하는 방식이었으며, 이는 기존의 학습 이론(Pearce and Hall, 1980)에서 제안된 unsigned prediction error 방식과 유사했다. 즉, 모델 기반 학습은 더 복잡한 계산을 사용하여 신뢰도를 추정하지만, 모델 없는 학습은 단순한 방식으로 신뢰도를 평가하는 차이가 있었다.
Arbitration Process Reflected by Functional Connectivity
연구진은 중재 과정이 모델 없는 학습 시스템을 억제하는 방식으로 작동함을 PPI(Psychophysiological Interaction) 분석을 통해 입증했다. 분석 결과, ilPFC의 활동이 증가할수록 후측 피각(posterior putamen)의 활동이 감소하는 패턴을 보였으며, FPC도 유사하게 모델 없는 시스템의 활성도를 억제하는 역할을 수행하는 것으로 나타났다. 이는 중재자가 모델 기반 학습을 직접 활성화하는 것이 아니라, 모델 없는 학습 시스템을 억제하는 방식으로 행동을 조절함을 의미한다.
이러한 결과는 모델 없는 학습이 기본적으로 더 효율적이고 자동적인(default) 방식이며, 특별한 이유가 없는 한 모델 없는 학습이 행동을 주도하는 것이 더 유리할 수 있음을 시사한다. 따라서, 중재자는 특정 상황에서 습관적 행동을 억제하고 목표 지향적 행동을 촉진하는 역할을 한다고 볼 수 있다.
Control Between Multiple Learning Systems in Lateral Prefrontal and Frontopolar Cortex
연구진은 ilPFC와 FPC가 각기 다른 방식으로 중재 과정에 기여할 가능성이 있음을 제안했다. 분석 결과, ilPFC는 두 학습 시스템의 개별 신뢰도와 최대 신뢰도를 모두 반영하는 반면, FPC는 오직 최대 신뢰도만 반영하는 것으로 나타났다. 이는 FPC가 ilPFC보다 상위의 제어 수준에서 동작할 가능성을 시사하며, FPC가 ilPFC의 활동을 조절하여 최종적인 행동 선택을 결정하는 역할을 할 수 있음을 의미한다.