
The hippocampus as a predictive map
이 논문의 해당 부분에서는 hippocampus(해마)의 기능을 기존의 인지 지도(cognitive map) 가설과 대비되는 예측 지도(predictive map) 가설을 강화학습(RL) 관점에서 설명하고 있다.
전통적으로 hippocampus의 place cells(장소 세포)는 공간을 명확하게 코딩하는 역할을 한다고 여겨져 왔다. 즉, place cells는 동물이 특정 위치에 있을 때 활성화되며, 이들이 모이면 공간의 구조를 나타내는 ‘인지 지도(cognitive map)’를 형성한다고 본다. 그러나 최근 연구에 따르면 place cells의 활성 패턴이 단순히 공간 정보만을 반영하는 것이 아니라는 점이 밝혀졌다. 예를 들어, 예측 부호화(predictive coding), 보상 민감성(reward sensitivity), 정책 의존성(policy dependence) 등의 특성은 place cells가 단순한 공간 지도로서의 역할을 넘어서 더 복잡한 정보를 담고 있을 가능성을 시사한다.
Introduction
이 논문에서는 hippocampus의 역할을 강화학습(RL) 관점에서 해석하며, 기존 cognitive map 이론을 확장하는 predictive map 이론을 제안한다. 강화학습에서 미래 보상을 예측하는 것이 중요하며, 이를 위해 전통적으로 두 가지 접근법이 존재한다. 첫 번째는 모델 기반 RL(Model-Based RL), 두 번째는 모델 프리 RL(Model-Free RL)이다. 그러나 이 논문에서는 hippocampus가 세 번째 해결책을 제공한다고 주장한다. hippocampus는 각 상태를 단순한 공간 정보로 저장하는 것이 아니라, 그 상태에서 도달할 수 있는 후속 상태(successor states)들의 가중 평균으로 표현하는 예측 지도(predictive map)을 학습한다. 즉, hippocampus는 단순한 위치 정보가 아니라 미래 상태를 예측하는 구조를 학습하며, 이를 통해 장기적인 보상 예측이 가능하고, 보상이 변화해도 빠르게 적응할 수 있다. 이는 기존의 Successor Representation (SR) 개념과 직접 연결되며, 현재 상태를 단순한 위치 정보로 저장하는 것이 아니라, 미래 상태의 가중치로 표현하는 방식이다.
Predictive Map 이론이 place cells의 여러 특성을 더 잘 설명할 수 있다고 주장한다. 첫째, place cells의 활성 패턴이 장애물(obstacles), 환경의 지형(environment topology), 이동 방향(direction of travel)과 같은 변수들에 의해 조절되는 이유를 설명할 수 있다. 단순한 공간 정보가 아니라, 미래 상태를 예측하는 방식으로 동작하기 때문이다. 둘째, predictive map 이론은 공간적(spatial) 과제뿐만 아니라 비공간적(non-spatial) 과제에서도 hippocampus의 역할을 설명할 수 있다. 기존의 cognitive map 이론은 공간적 정보만 설명할 수 있지만, predictive map은 강화학습에서 일반적으로 활용될 수 있는 구조이기 때문이다. 셋째, 이 방식은 모델-프리 RL보다 보상 변화에 더 빠르게 적응할 수 있으며, 모델-기반 RL보다 계산량이 적다는 장점이 있다.
hippocampus와 함께 작용하는 entorhinal cortex(내후각 피질)의 grid cells(격자 세포)는 공간을 주기적인 패턴으로 표현한다. 이 논문에서는 grid cells가 predictive map을 더 효과적으로 활용하기 위해 중요한 역할을 한다고 주장한다. grid cells는 predictive representation의 저차원 표현(low-dimensional basis set)을 제공하며, hippocampus에서 학습한 predictive map이 grid cells의 역할을 통해 더 정교해지고, 노이즈가 감소하며, 다중 스케일의 구조(multiscale structure)를 추출하여 계층적 계획(hierarchical planning)에 유리해진다. 이러한 Predictive Map 이론은 기존 Cognitive Map 이론을 확장하며, 보상 학습과의 연결을 설명할 수 있는 강력한 개념이다.
Results
Successor Representation(SR)과 Hippocampus의 역할
전통적으로, hippocampus는 장소(place) 자체를 인코딩하는 역할을 한다고 알려져 있다. 즉, place cells(장소 세포)는 특정 장소에서 활성화되며, 동물이 해당 위치에 있을 때만 firing(발화)한다고 여겨져 왔다. 그러나 SR 모델에서는 place cells가 단순히 현재 위치를 인코딩하는 것이 아니라, 미래 상태(successor states)에 대한 예측적 표현(predictive representation)을 인코딩한다고 주장한다. 즉, 각 상태(state)는 미래에 방문할 상태들의 가중 합으로 표현되며, 미래 상태가 비슷한 두 지점은 유사한 표현을 갖는다.
강화학습(RL)에서 가치 함수(value function) \(V(s)\)는 특정 상태 \(s\)에서 시작하여 얻을 미래 보상의 기댓값으로 정의된다. 이는 할인 계수 \(\gamma\)를 포함하여 다음과 같이 표현된다.
\[V(s) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t R(s_t) \mid s_0 = s \right]\]여기서, \(s_t\)는 시간 \(t\)에서 방문한 상태(state), \(\gamma\)는 할인 계수 (\(0 \leq \gamma \leq 1\)), \(R(s_t)\)는 상태 \(s_t\)에서 얻는 보상을 의미한다. 그리고 SR은 현재 상태에서 시작했을 때 미래 상태들의 가중 평균을 저장하는 행렬 \(M\)로 정의된다.
\[M(s, s') = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t \mathbf{I}(s_t = s') \mid s_0 = s \right]\]여기서 \(M(s, s')\)는 현재 상태 \(s\)에서 시작했을 때 미래 상태 \(s'\)를 방문할 확률의 가중치(Successor Representation), \(\mathbf{I}(s_t = s')\)는 특정 시간 \(t\)에서 \(s_t\)가 \(s'\)이면 1, 아니면 0으로 표현된다. 즉, SR 행렬 \(M(s, s')\)는 현재 상태에서 특정 미래 상태로의 이동 가능성을 할인 계수를 적용해 예측한 값이다. 이를 행렬 형태로 다시 표현하면
\[M = \sum_{t=0}^{\infty} \gamma^t P^t\]이 식이 수렴하면 닫힌 형태로 다음과 같이 표현할 수 있다.
\[M = (I - \gamma P)^{-1}\]즉, SR 행렬 \(M\)은 Bellman 방정식과 직접적으로 연결되며, 전이 확률 행렬 \(P\)을 기반으로 계산된다.
기존의 강화학습에서는 상태의 가치 \(V(s)\)를 보상 함수 \(R(s)\)를 이용하여 직접 계산해야 한다. 하지만 SR을 이용하면 가치 함수는 단순한 행렬 곱으로 표현될 수 있다.
\[V(s) = \sum_{s'} M(s, s') R(s')\]이 식을 사용하면, 보상이 변경되었을 때도 SR 행렬 \(M\)을 유지한 채 새로운 보상 함수 \(R(s)\)만 바꾸어 즉시 새로운 가치 함수를 계산할 수 있다. 또한 SR 행렬 \(M(s, s')\)은 Temporal Difference (TD) Learning 알고리즘을 통해 점진적으로 업데이트될 수 있다.
\[M(s, s') \leftarrow M(s, s') + \alpha \left[ \mathbf{I}(s = s') + \gamma M(s', s'') - M(s, s') \right]\]이 방정식은 기존의 TD 학습법과 유사하지만, 보상이 아닌 미래 상태를 예측하는 방식으로 학습이 진행된다는 점이 다르다. SR을 사용하면 보상이 변해도 \(M\)은 유지되며, \(R\)만 변경하면 즉시 \(V(s)\)를 재계산할 수 있다는 장점이 있다. 기존 모델-기반 RL에서는 전이 확률 \(P(s' \mid s)\)을 명시적으로 저장해야 하지만 SR은 전이 확률을 직접 저장하지 않고, 미래 상태의 가중 평균을 학습하므로 계산량이 상대적으로 적다. 또한 SR의 중요한 특징은 비슷한 미래 상태를 가지는 현재 상태는 유사한 SR 표현을 갖는다는 특징이 있는데, 이는 SR이 공간적인 과제 뿐만 아니라 비공간적 과제에도 적용 가능함을 의미한다.
Hippocampus가 Successor Representation(SR)을 인코딩하는 방식
이 논문의 핵심 주장 중 하나는 hippocampus가 Successor Representation(SR)을 인코딩한다는 가설이다. 기존 연구에서는 hippocampus가 공간과 환경의 맥락(context)을 인코딩하며, 순차적 의사결정(sequential decision-making)에 기여한다고 알려져 있다. 이러한 역할은 hippocampus가 SR을 인코딩할 가능성을 시사한다. 이 논문에서 설명하는 predictive map 이론에서는 place cells가 단순히 현재 위치를 인코딩하는 것이 아니라, 미래 위치를 예측적으로 인코딩한다고 주장한다.
SR 모델에서 Place Cells의 역할
SR 가설에서는 각 뉴런이 환경 내에서 미래 상태(successor state)를 인코딩한다고 본다. 현재 상태 \(s\)에서 hippocampus의 전체 뉴런 집단(population)은 SR 행렬 \(M(s, :)\)의 한 행(row)을 인코딩한다. 특정 뉴런이 인코딩하는 상태 \(s'\)의 발화율(firing rate)은 현재 상태 \(s\)에서 시작했을 때 미래에 \(s'\)를 방문할 할인된 기대 횟수 (discounted expected number of visits)와 비례한다. 이러한 SR 모델에서 각 뉴런의 발화 패턴을 SR 장소 필드(SR place field)라고 하며, 이는 SR 행렬 \(M(:, s')\)의 한 열(column)에 해당한다. 즉, hippocampus의 개별 뉴런은 특정 위치를 직접적으로 나타내는 것이 아니라, 해당 위치에서 시작했을 때 미래에 방문할 가능성이 높은 위치들을 반영하는 방식으로 발화한다.
또한 SR 모델은 다양한 공간적 환경에서 place cell의 발화 패턴을 예측할 수 있는데, 열린 2차원(2D) 환경에서는 전형적인 place cell은 점진적으로 감소하는 원형 발화 필드(circular firing field)를 가진다. SR 모델도 이와 유사한 예측을 하는데, 무작위 이동(random walk) 시, 동물은 현재 위치 및 주변 위치를 즉시 방문하고, 먼 위치는 더 나중에 방문하게 된다. 따라서 현재 위치와 가까운 상태일수록 미래 방문 가능성이 높으므로 인코딩 뉴런의 발화율이 더 높게 나타난다.
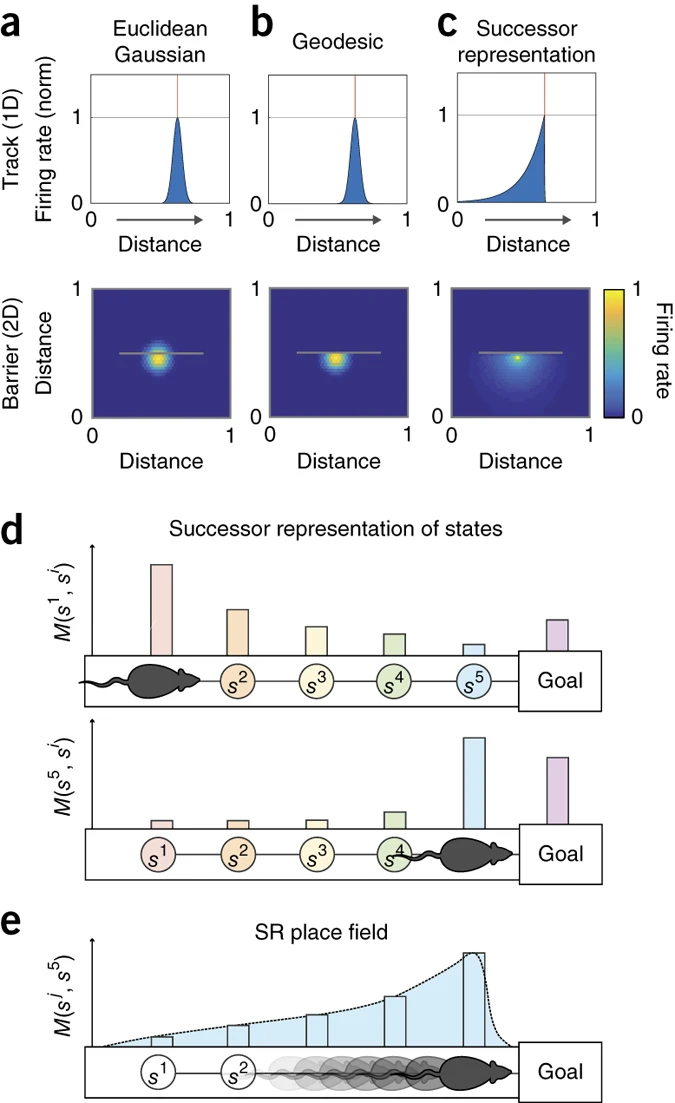
하지만 SR 모델은 기존의 모델과 차별화되는 점도 존재한다. 기존의 유클리드 거리 기반 Gaussian 모델은 모든 방향에서 같은 거리만큼 발화율이 감소한다고 가정하여 (Figure 2a)발화 패턴이 장애물의 영향을 받지 않고 단순히 거리 기반으로 결정된다. 또한 지형학적(topologically-sensitive) 모델은 장애물을 고려하여, 특정 위치에서 출발해 장애물을 피해 도달하는 최단 거리(geodesic distance)를 기준으로 발화 패턴이 형성되는데, (Figure 2b) 장애물이 존재할 경우 반대편 위치로의 직접적인 경로가 없으므로, place field가 단절되어 이동 방향성(behavioral policy)의 영향을 반영하지 못한다. SR 모델(Figure 2c)은 장애물이 있으면, 반대편 공간은 방문할 가능성이 낮으므로 발화 필드가 끊어진다. 이는 topologically-sensitive한 공간 인코딩을 설명할 수 있는 강력한 특성이다.
일차원(1D) 트랙에서 동물이 일정한 방향으로 이동하는 경우(Figure 3), SR place fields는 이동 방향의 반대쪽으로 비대칭적으로 기울어진다(skewing). 동물이 일정한 방향으로 움직이면, 현재 위치에서 특정 미래 상태를 더 확실하게 예측할 수 있기 때문에 place cell의 receptive field는 예측적 특성을 가지며, 실제 상태보다 조금 앞서서 발화하기 시작한다. 이로 인해 각 개별 뉴런의 receptive field는 후방(backward) 방향으로 기울어진 패턴을 보인다. Figure 3a는 SR 모델이 예측하는 backward skewing 패턴을 보여주며, Figure 3b는 실제 동물의 hippocampus에서 기록된 place cell 발화 패턴을 나타낸다. 결과적으로, 실험에서 관찰된 발화 패턴이 SR 모델의 예측과 매우 유사하게 나타났다.
Hippocampus에서 SR 모델의 예측과 실험적 검증
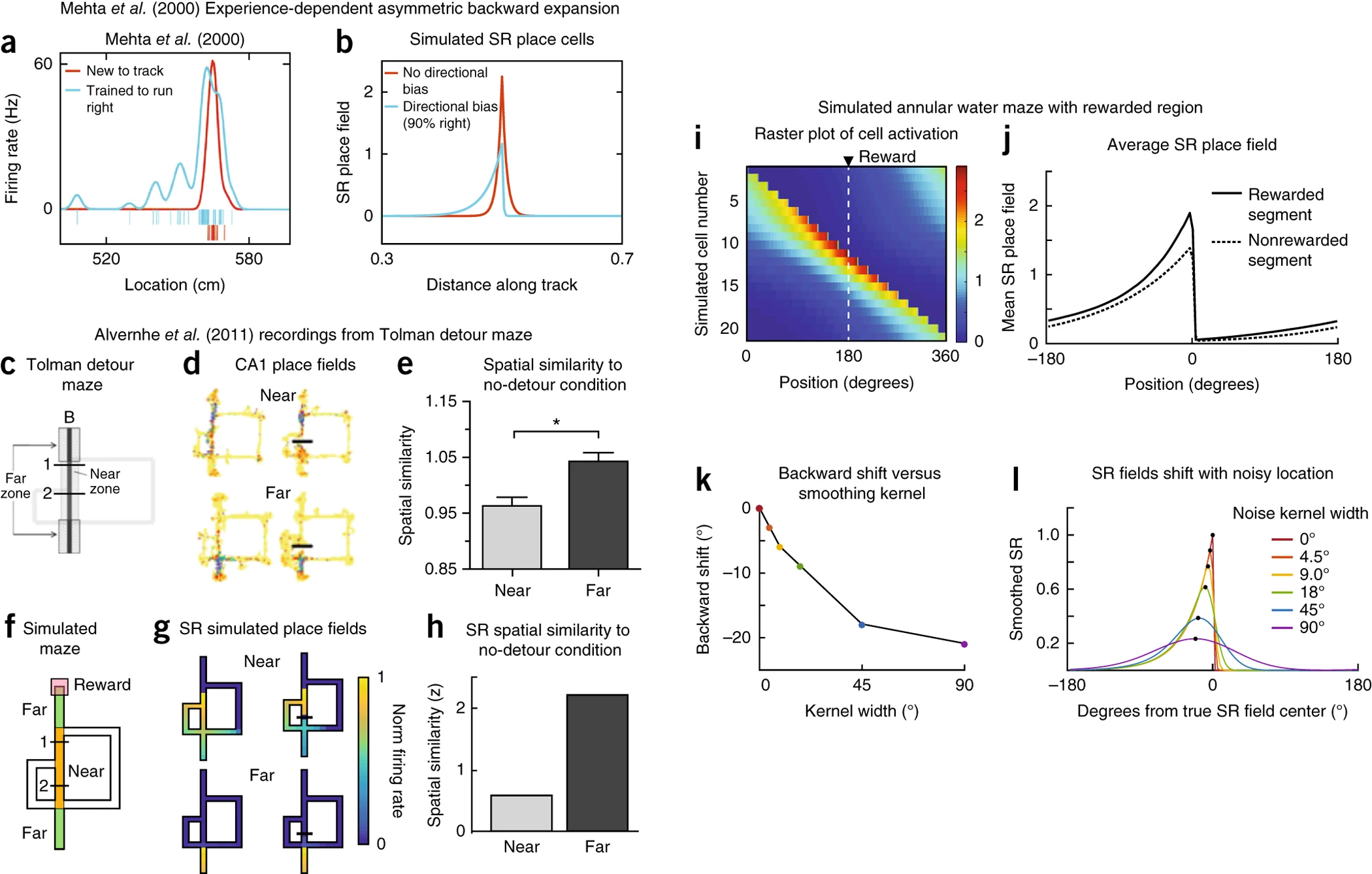
1. 장애물이 존재할 때 장소 필드의 변화 (Figure 3c–h)
장소 세포의 발화 패턴이 단순한 공간적 위치에 따라 고정되지 않고, 행동 정책(transition policy)에 의해 영향을 받는다는 점이 중요하다. 기존 연구에 따르면 장소 필드는 장애물 근처에서 더 크게 변형(local remapping)되며, 장애물에서 멀어질수록 변화가 적다 (Alvernhe et al., 2018). 이러한 실험 결과를 SR 모델을 통해 시뮬레이션하여 비교하였다.
SR 모델은 동물이 환경을 탐색하면서 학습한 이동 정책에 따라 장소 필드가 조정될 수 있음을 가정한다. 따라서 장애물이 추가되면 동물은 새로운 최적 경로를 따르게 되며, 이에 따라 장소 필드도 영향을 받는다. 특히, 장애물 가까이에 위치한 장소 필드는 변경된 이동 경로로 인해 발화율이 크게 변하는 반면, 장애물에서 멀리 떨어진 장소 필드는 상대적으로 적은 변화를 보인다.
Figure 3d에서는 Tolman detour maze(Figure 3c)에서 장애물이 추가되었을 때(Barrier Insertion), 장애물 근처에서 장소 필드(상단)가 급격히 변화하는 양상을 보여준다. 통계적으로도 유의미한 차이가 나타났으며(P < 0.001), 이는 장소 필드가 환경 내 장애물 배치에 따라 동적으로 조정될 수 있음을 시사한다.
Figure 3f–h에서는 SR 모델을 이용한 시뮬레이션 결과를 제시한다. Figure 3f는 사용한 미로의 모양을 제시하며, Figure 3g는 SR 모델로 시뮬레이션한 결과를 보여준다. SR 모델에서는 장애물 근처의 장소 필드(상단)가 크게 변형되었으며, 먼 지역(하단)에서는 상대적으로 변동이 적었다. 특히, 초기 장애물 삽입 위치에 따라 장소 필드의 변화 양상이 다르게 나타났으며, 이는 이동 정책이 반영된 결과임을 보여준다.
이러한 결과를 종합하면, SR 모델은 장애물이 환경에 삽입되었을 때 동물의 행동 정책 변화에 따라 장소 필드가 어떻게 조정되는지를 설명할 수 있는 강력한 모델임을 확인할 수 있다. 이는 기존 Gaussian 모델이 장애물을 고려하지 않는 한계를 극복하는 중요한 특징이다.
2. 보상의 영향을 받은 장소 필드의 변화 (Figure 3i–l)
장소 필드의 발화 패턴은 단순한 환경적 요소뿐만 아니라, 보상(reward)과 같은 행동적으로 중요한 요인에 의해서도 조정될 수 있다. Hollup et al.(2001)의 연구에서는 동물이 은폐된 보상(hidden reward)이 있는 위치에서 더 많은 시간을 머물렀으며, 이에 따라 보상 위치 주변에서 장소 필드가 더 밀집하는 경향이 관찰되었다.
SR 모델이 이러한 보상의 영향을 어떻게 설명할 수 있는지 시뮬레이션을 통해 분석하였다. 이 실험은 Hollup et al.(2001)의 환형 수중 미로(Annular Water Maze) 실험을 기반으로 한다. 동물(주로 쥐 또는 랫)이 수영해야만 이동할 수 있는 원형의 미로(링 모양의 수조)에서 특정한 위치에 숨겨진 보상(플랫폼)이 있을 때, 장소 필드(place fields)가 어떻게 변하는지를 연구하였다. Figure 3ㅑ, j에서 SR 모델을 사용하여 보상 위치에서의 발화 패턴을 재현한 결과, 보상 근처에서 장소 필드가 더욱 밀집되는 경향이 나타났으며, 보상 직전 상태에서도 발화율이 증가하는 양상이 확인되었다. 이는 SR 모델이 강화학습(reinforcement learning)의 특성을 반영하여, 보상이 있는 위치뿐만 아니라 그 직전 상태에서도 발화 패턴이 조정될 수 있음을 시사한다.
Figure 3k에서는 보상의 위치가 불확실할 때, SR 모델에서도 장소 필드가 부드럽게 변화(smoothing)하고, 발화 중심이 뒤쪽으로 이동하는 현상이 나타났다. 이는 실험에서 관찰된 asymmetric firing field를 잘 설명할 수 있는 중요한 특징이다. 그러나 SR 모델이 모든 실험 결과를 완벽하게 설명하는 것은 아니다. 예를 들어, 실험에서는 보상 위치에서 장소 필드의 크기가 일정하게 유지되었지만, SR 모델은 보상 근처에서 장소 필드의 크기가 커질 것이라고 예측하였다.(Figure 3l) 이는 SR 모델이 아직 보상에 대한 장소 필드의 변화를 완벽하게 반영하지 못하는 한계를 나타낸다.
3. 비공간적 환경에서의 SR 모델 적용 (Figure 4a–g)
SR 모델이 단순히 공간적(spatial) 환경에서만 유용한 것이 아니라, 비공간적(non-spatial) 태스크에서도 적용 가능할 수 있음을 검증하였다.
Schapiro et al.(2013)의 연구에서는 인간 피험자들에게 특정한 그래프(graph) 구조를 기반으로 한 프랙탈 자극(fractal stimuli)을 학습시키고, 실험 중 피험자들에게 랜덤 워크(random walk)를 통해 특정한 순서로 자극을 제시하고, 학습이 진행됨에 따라 hippocampus에서의 신경 신호 변화를 관찰하였다. Figure 4b의 결과에서, 특정 영역에서 같은 커뮤니티 내의 상태들이 강하게 연관된 신호 패턴을 보였다.
Figure 4a–d에서는 실제 실험에서 관찰된 hippocampal 신호의 패턴 유사성 결과를 보여준다.
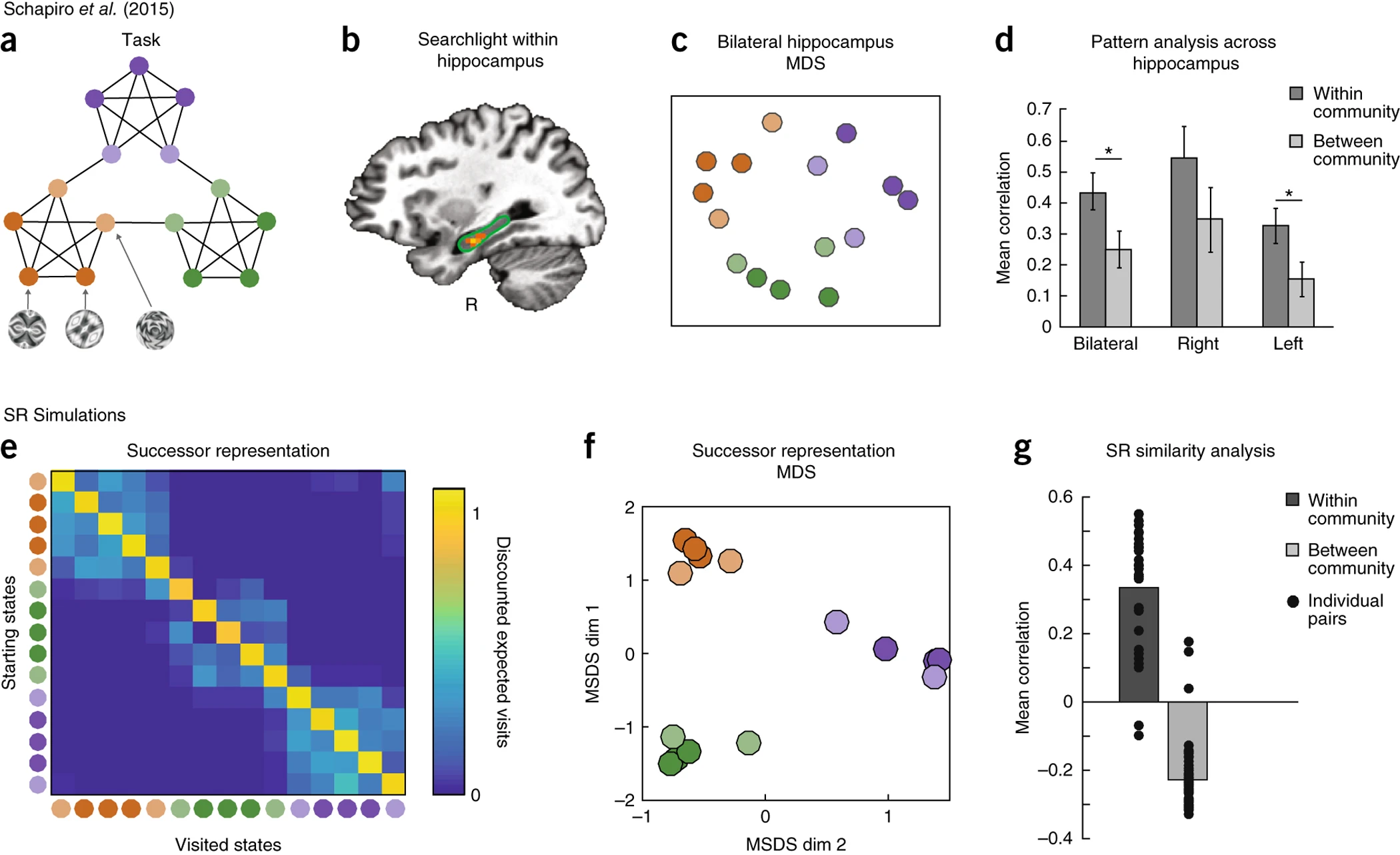
Figure 4e–g에서는 SR 모델을 적용하여 실험 결과를 재현한 결과, SR 행렬(SR matrix)에서도 동일한 커뮤니티 구조가 나타났으며, SR 기반의 다차원 스케일링(MDS, Multidimensional Scaling)을 통해 실험 결과와 유사한 구조가 형성됨이 확인되었다. 이러한 결과는 SR 모델이 공간적 정보뿐만 아니라, 일반적인 상태(state) 간의 관계를 반영하는 보편적인 기제로 작용할 수 있음을 시사한다.
4. 시공간적(spatiotemporal) 태스크에서의 SR 적용 (Figure 5a–f)
Hippocampus가 단순한 공간적 정보 저장소가 아니라, 공간적 정보와 시간적 정보를 통합적으로 반영하는 역할을 수행할 수 있는가? 이에 대한 검증을 위해 Deuker et al.(2016)의 연구를 기반으로 SR 모델을 적용하였다.
Figure 5a–c에서는 피험자들은 가상의 도시(virtual city)에서 특정한 물체를 탐색하는 태스크를 수행하였다. 실험 환경에서는 일반적인 이동 경로(winding path)뿐만 아니라 특정 장소 간 순간이동(teleportation)도 가능하도록 설정, 즉 공간적으로 먼 두 지점이라도 텔레포트 기능이 있으면 짧은 시간 내에 이동할 수 있는 환경이 조성되었다. 이는 공간적 근접성(spatial proximity)과 시간적 근접성(temporal proximity)을 분리할 수 있는 실험 조건을 제공한다. Figure 5b에서는 hippocampal representational similarity(해마의 신경 표현 유사성)를 분석하였다. 실험 결과, 단순히 공간적으로 가까운 장소들뿐만 아니라, 시간적으로 가까운 장소들도 hippocampus 내에서 유사한 방식으로 인코딩됨이 확인되었다. 이는 hippocampus가 순수한 공간적 정보만을 저장하는 것이 아니라, 이동 경로와 시간적 관계를 함께 반영하고 있음을 시사한다.
다만 공간적 근접성과 시간적 근접성이 서로 상관관계를 가질 수 있기 때문에, 연구자들은 공간적 요인을 통제한 상태에서 시간적 관계의 효과를 분석하였다(Figure 5c). 통계적으로 P<0.05 수준에서 유의미한 차이가 확인되었으며, 공간적 근접성과 독립적으로 시간적 근접성 또한 hippocampal 신경 표현을 결정하는 요인임을 보였다.
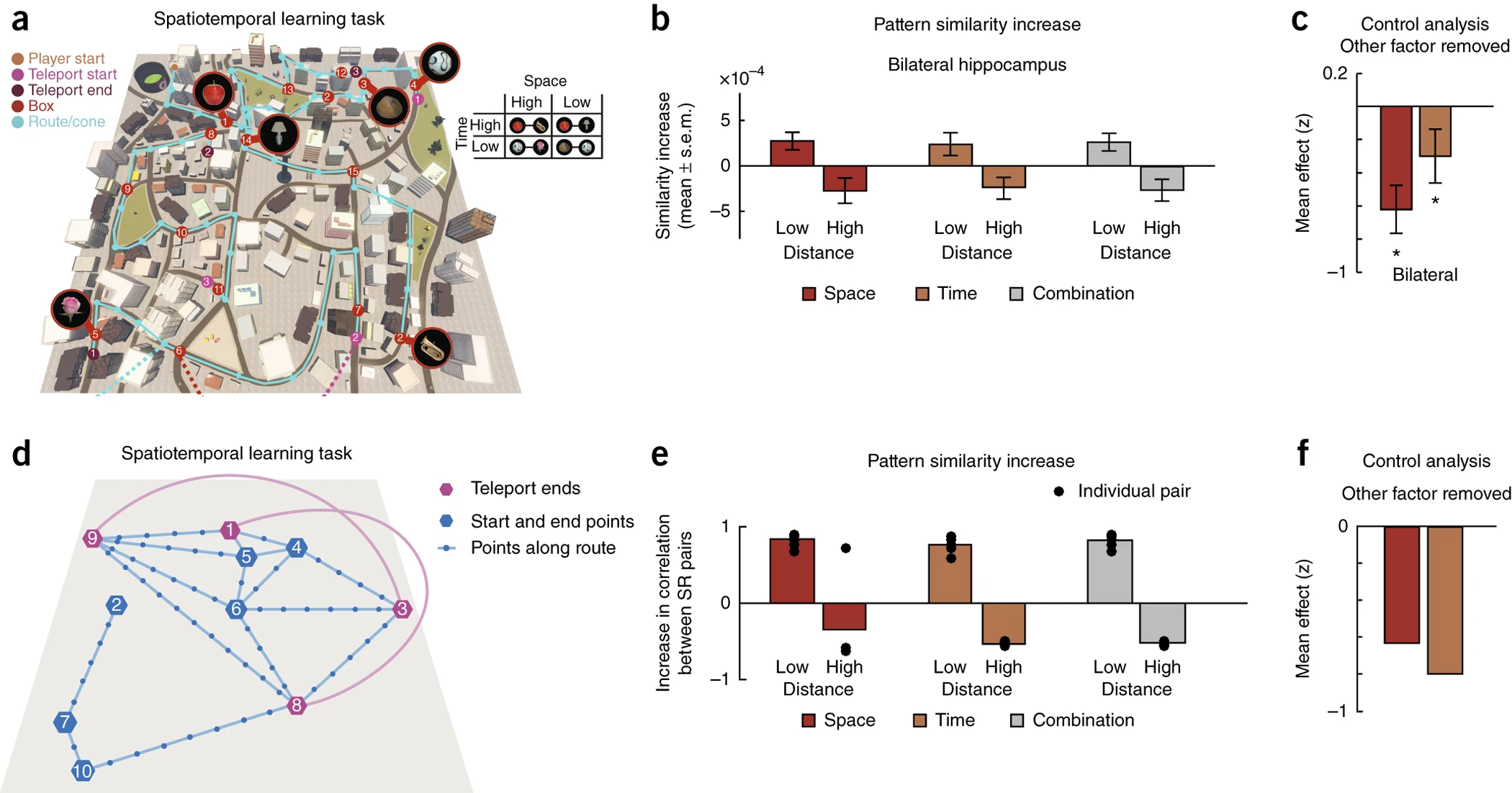
이후 SR 모델을 이용하여 동일한 실험 태스크를 시뮬레이션하고, 모델이 학습한 상태 표현(state representation)이 hippocampus의 신경 표현과 유사한 패턴을 나타내는지 검증하였다. Figure 5d–f에서는 SR 모델이 학습한 상태 표현을 분석하였으며, 실험 데이터에서 관찰된 공간적-시간적 관계가 SR에서도 반영됨을 확인하였다. SR 모델은 현재 상태에서 미래 상태를 예측하는 방식으로 학습되므로, 이동 경로와 소요 시간을 반영한 상태 표현을 학습하는 것이 가능하다. 이를 통해 hippocampus에서 관찰된 신경 패턴과 SR 모델의 예측이 일치한다는 점을 검증하였다.
Entorhinal Grid Cells의 역할: Predictive Map의 차원 축소 (Dimensionality Reduction of the Predictive Map by Entorhinal Grid Cells)
Hippocampus의 공간적 표현이 SR(Successor Representation)이라는 예측 기반 지도(predictive map) 형식으로 구성된다고 가정할 때, entorhinal grid cells는 이 지도에서 차원 축소(dimensionality reduction) 역할을 수행할 수 있는가? 이 질문에 대한 답을 찾기 위해, 연구진은 grid cells가 SR의 저차원 고유벡터(eigendecomposition)를 반영한다는 가설을 제시하였다.
1. 기존 Grid Cell 이론과 SR 가설의 통합
Entorhinal grid cells는 격자 형태(hexagonal pattern)의 공간적 발화(spatial firing)를 가지며, 위치 추적(dead reckoning)에 기여한다는 가설이 제안된 바 있다(Hafting et al., 2005). 그러나, 다른 연구들은 grid cells의 발화 패턴이 해마(hippocampus)의 공간 지도(cognitive map)를 저차원으로 압축한 결과일 수 있다고 주장했다.
이에 따라, 본 연구에서는 grid cells가 SR의 고유벡터(eigenvectors)로 표현될 수 있으며, 이를 통해 환경의 전이(transitional dynamics) 정보를 내재적으로 반영할 수 있다는 가설을 제시하였다. 즉, grid fields는 SR의 저차원 구조를 나타내는 뉴런의 집합으로 볼 수 있으며, 이 가설의 주요 예측 중 하나는 환경의 경계(boundary conditions)에 따라 grid cell의 발화 패턴이 달라진다는 점이다.
2. Grid Cell의 Boundary Sensitivity 실험 (Krupic et al., 2015)
이 가설을 검증하기 위해, Krupic et al. (2015)는 환경의 기하학적 경계를 조작하여 grid cell의 반응이 어떻게 변화하는지 연구하였다. 연구진은 사각형(Square)과 원형(Circular) 환경을 비교하였으며, 각각의 환경에서 grid cell의 정렬(grid alignment) 패턴을 분석하였다. 그 결과, 사각형 환경에서는 grid field가 일정한 방향으로 정렬되었다.(Figure 6b) 이는 grid field의 육각 대칭(hexagonal symmetry, 60° 간격 정렬)으로 인해 발생할 가능성이 높다. 원형 환경에서는 Grid cells의 정렬이 불규칙적이고 가변적(variable alignment)이며, 특정 경계에 고정되지 않았다.(Figure 6c) 이는 원형 환경이 회전 대칭(rotational symmetry)을 가지며, grid cells가 특정 경계를 기준으로 정렬할 필요가 없기 때문으로 해석된다.
이러한 결과는 grid cells가 단순히 유클리드 거리(Euclidean distance)를 기반으로 하는 것이 아니라, 환경의 구조적 요소를 반영하여 작동할 가능성을 시사한다.
3. 사각형과 사다리꼴 환경 비교: Split-Halves 분석 (Figure 6d, 6e 참고)
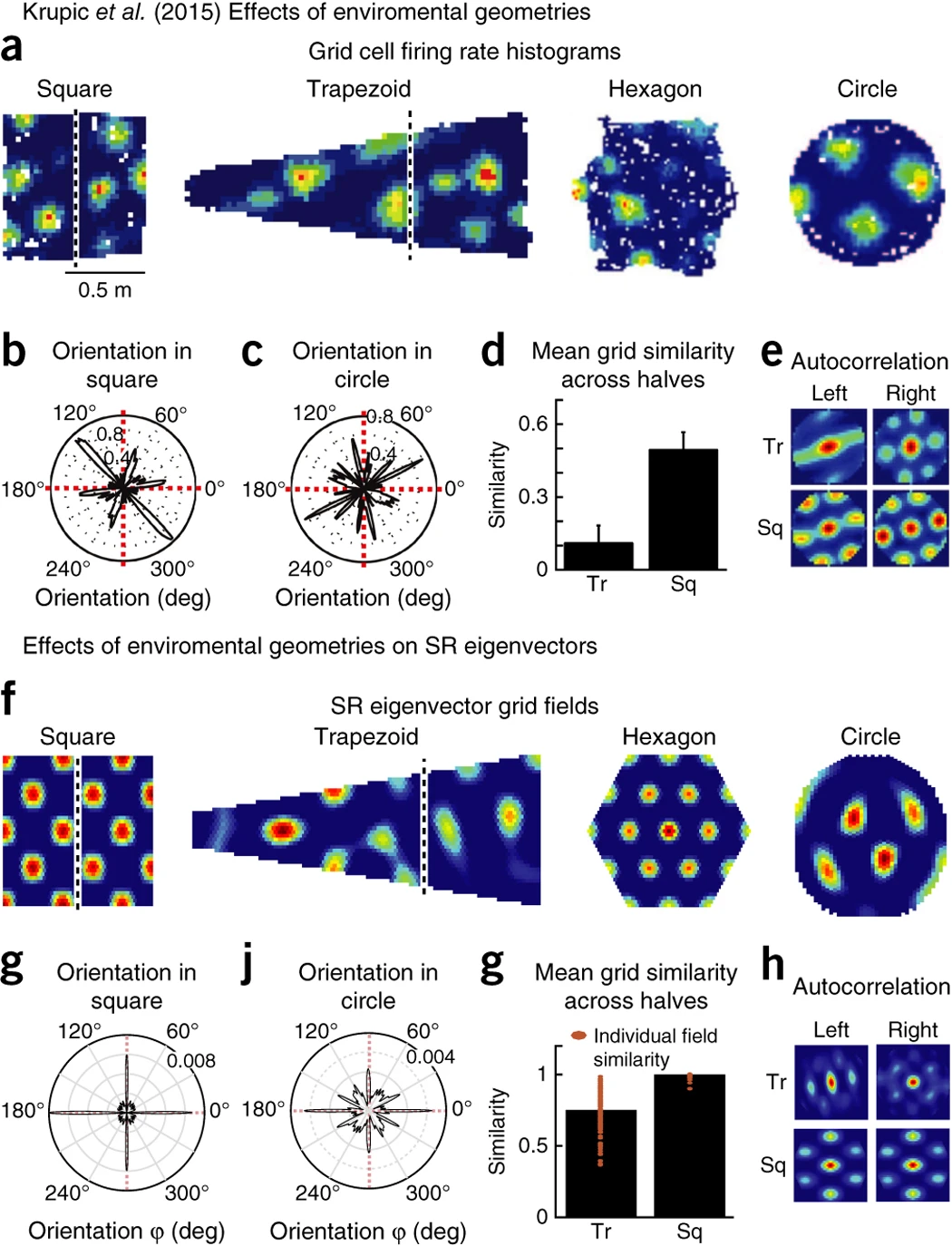
Krupic et al. (2015)는 grid cell이 환경의 비대칭적 구조(asymmetrical boundaries)에 따라 다르게 반응하는지 확인하기 위해, 사각형(sq)과 사다리꼴(tr) 환경을 비교하였다. 사각형 환경에서는 grid field가 환경의 양쪽에서 유사한 패턴을 보였고, grid cell의 발화 패턴은 환경 좌우(side-to-side)에서 큰 차이가 없었다.(Figure 6d) 사다리꼴 환경에서는 grid field의 구조가 양쪽에서 다르게 나타났는데, 환경이 비대칭적(asymmetrical)으로 변경될 경우, grid cell의 정렬이 깨지고, 양쪽에서 서로 다른 발화 패턴을 형성하는 것이 관찰되었다. 특히, 자동 상관분석(autocorrelation analysis) 결과, trapezoidal 환경에서는 grid pattern의 반복 주기가 양쪽에서 달라지는 것으로 확인되었다(Figure 6e).
이러한 결과는 grid cell이 단순한 공간적 거리 측정 도구가 아니라, 환경의 전이 확률(transition probability)과 경계 구조를 반영하는 예측 기반 표현(predictive representation)을 구성할 가능성이 높다는 점을 시사한다.
4. SR Eigenvector 모델을 통한 Grid Field 시뮬레이션 (Figure 6f–h 참고)
연구진은 SR 모델을 기반으로 한 시뮬레이션을 수행하여, grid field가 환경의 기하학적 구조에 따라 어떻게 변화하는지 분석하였다. SR 모델에서 추출한 고유벡터(eigenvectors)를 이용하여 grid field를 시뮬레이션한 결과, 실험 결과와 유사한 패턴이 관찰되었다. (Figure 6f–h). 또한 원형 환경에서 eigenvector의 방향성이 불규칙적으로 변하는 반면, 사각형 환경에서는 경계를 따라 정렬되는 경향을 보였다. (Figure 6g, j). 사각형 환경에서 사다리꼴 환경으로 이동하면, SR의 고유벡터도 비대칭적으로 변화하며, grid field의 구조가 달라졌다. 이러한 결과는 grid cell이 SR의 저차원 고유벡터를 반영하며, 환경의 구조에 따라 그 표현이 변화한다는 가설을 뒷받침한다.
5. Grid Cells의 Boundary Sensitivity와 환경 구조에 따른 변화 (Figure 7, 8 분석)
Grid cells의 발화 패턴은 단순히 공간의 유클리드적 구조를 반영하는 것이 아니라, 환경의 경계(boundary)와 공간적 전이 구조(transition structure)에 의해 결정된다. Krupic et al. (2015)의 연구는 grid cell이 환경 회전에 어떻게 반응하는지, 그리고 비정형적인 환경(예: hairpin maze)에서 어떻게 발화 패턴이 변화하는지를 분석하였다.
Krupic et al. (2015)의 주요 발견 중 하나는 사각형 환경을 회전시켜도 grid cell의 정렬(alignment)은 원거리 단서(distal cues)가 아니라 환경의 경계(boundaries)에 고정된다는 점이다. SR 모델에서는 grid cell의 발화 패턴이 환경의 전이 구조(transition structure)에 의해 결정되므로, 환경이 회전되더라도 grid field가 경계를 기준으로 유지되는 특성이 자동적으로 나타난다. (Figure 7a)
SR 모델에서 grid field는 환경의 전이 확률을 반영하므로, 경계가 변화하지 않는 한 grid alignment가 그대로 유지됨을 관찰하였다. (Figure 7b–c)

Grid Cell의 환경 적응 및 공간 표현 변화
다중 구획 환경에서의 Grid Field 변화
격자 세포(Grid cells)는 초기에는 각 구획(compartment)별로 독립적인 격자 구조(grid fields)를 형성하지만, 시간이 지나면서 더 넓은 범위를 포괄하는 전역적(global) 격자 패턴으로 변화하는 특징을 보인다. 이를 통해 격자 세포가 단순한 유클리드적 공간 측정 장치가 아니라, 환경의 구조적 특성을 반영하는 예측 지도(predictive map) 역할을 할 가능성이 제기된다.
Carpenter et al.(2015) 연구에서는 다중 구획 환경(multi-compartment environment)에서 격자 세포의 활동이 시간이 지나면서 어떻게 변화하는지를 분석한 결과, 초기에는 개별 구획(compartment)에서 동일한 격자 패턴(repeated grids)이 나타났다. 하지만 여러 날 동안 탐색한 후에는 격자 패턴이 점점 더 넓은 영역을 포함하는 전역적(global) 패턴으로 변형되었으며, 동시에 격자 패턴의 규칙성이 감소하였다(Figure 8d,f). 또한, 두 개의 서로 다른 방(room)에서 기록된 격자 패턴 간의 유사성이 감소하는 현상(Figure 8c)이 관찰되었다. 즉, 시간이 지나면서 개별 compartment별로 독립적으로 유지되던 격자 구조가 전체 공간을 반영하는 하나의 격자로 통합되는 과정이 나타났다.
연구진은 SR(Successor Representation) 모델을 활용하여 초기에는 동물이 각 compartment가 어떻게 연결되어 있는지 모른다고 가정하고, 각 구획에서 독립적인 격자 패턴을 형성하도록 설정하였다. 이후, SR의 고유벡터(eigenvectors)를 학습하면서 격자 패턴이 점점 더 전역적인 구조를 반영하도록 변화하는 과정을 구현하였다. 이 과정에서 초기에는 두 개의 방(room)에 동일한 격자 패턴을 유지하던 것이, 학습이 진행됨에 따라 서로 다른 구조로 변화하였다. 결과적으로, 시간이 지남에 따라 개별 compartment에 대한 격자 표현이 점점 더 전역적인 구조를 반영하는 패턴으로 변화하였으며, 두 개의 방에서의 격자 표현 유사성이 점점 감소하였다. (Figure 8i) 이러한 결과는 격자 세포가 단순히 공간을 유클리드적으로 측정하는 장치가 아니라, 환경의 구조적 특성을 반영하여 예측 지도를 형성할 가능성이 있음을 시사한다.

Discount Factor(γ)와 Grid Field 변화의 관계
R 행렬은 여러 개의 전이 확률 행렬(transition probability matrix)의 가중합(weighted sum)으로 표현될 수 있으며, discount factor(γ)의 크기에 따라 학습되는 고유벡터의 특성이 달라진다. γ가 클수록(longer timescales 반영) 더 넓은 공간을 반영하는 대규모 격자 패턴이 강화되며, γ가 작을수록(shorter timescales 반영) 보다 지역적인 공간 패턴이 강화된다. 이러한 결과는 hippocampus가 다양한 시간적 스케일에서 환경을 인코딩할 수 있는 메커니즘을 가질 수 있음을 시사한다. 즉, discount factor(γ)를 조절하는 방식으로 hippocampus 내에서 계층적인 공간 표현이 가능할 수 있음을 보여준다.
Grid Fields의 불규칙성 감소와 Regularization 효과
격자 세포의 신호는 환경 적응 과정에서 시간이 지나면서 불규칙해지는 경향이 있다. Carpenter et al.(2015) 연구에서는 학습이 진행됨에 따라 격자 패턴의 규칙성이 감소하는 현상이 관찰되었다. 연구진은 SR 모델을 기반으로 이러한 현상이 발생하는 원인을 규명하였다.
격자 세포는 SR 행렬의 저차원 표현(low-dimensional representation)을 기반으로 학습하는데, SR 행렬의 고유벡터를 활용한 투영 과정에서 noise가 제거되며, 학습 초기에 비해 점차 예측 지도(predictive map)의 형태를 반영하는 구조로 변화한다. 이러한 과정은 스펙트럼 정규화(spectral regularization)와 유사한 방식으로 작동하여 학습이 진행될수록 고유벡터의 구조가 변형된다. (Supplementary Figure 12) 결과적으로, SR 모델의 고유벡터를 활용한 투영 과정은 학습 초기에 존재하는 noise를 제거하면서 점진적으로 최적화된 격자 구조를 형성하게 된다.
Grid Fields와 Hierarchical Planning의 연결 가능성
이 연구는 격자 세포가 단순한 공간 좌표(coordinate system)로서 작동하는 것이 아니라, 환경의 구조를 반영하는 예측 지도(predictive map)를 형성하며, 계층적 계획(hierarchical planning)과 연계될 가능성이 있음을 시사한다. 격자 세포는 단순한 유클리드 공간 좌표 체계가 아니라, 예측 지도(predictive map)와 계층적 계획(hierarchical planning)에 기여할 가능성이 크다.
결론적으로, 격자 세포는 시간이 지남에 따라 compartment별 독립적인 격자 패턴에서 전역적(global) 패턴으로 변화하며, discount factor(γ)에 따라 공간 표현이 달라질 수 있으며, 학습 과정에서 noise를 제거하는 regularization 효과가 나타난다. 이러한 과정은 hippocampus와 entorhinal cortex에서 관찰되는 격자 세포의 공간 표현 변화와 일치할 가능성이 있으며, hippocampus가 환경의 구조를 학습하고 예측하는 기능을 수행할 수 있음을 강력히 시사한다.
Grid Fields와 Subgoal Discovery
구조화된 환경(structured environment)에서 효율적인 계획(planning)을 수행하기 위해서는 작업을 여러 개의 하위 목표(subgoals)로 나누는 것이 효과적이다. 하지만, 적절한 subgoal을 자동으로 발견하는 것은 어려운 문제이다. 이 연구에서는 SR(Successor Representation) 모델의 고유벡터(eigenvectors)를 활용하여 중요한 ‘bottleneck states’를 찾아 subgoal을 설정하는 방법을 제안한다.
SR 모델을 이용한 서브골 추론
SR 모델에서는 가장 큰 공간적 규모(spatial scale)를 갖는 고유벡터(eigenvector)가 환경 내의 주요한 병목 상태를 중심으로 공간을 분할하는 역할을 한다. Supplementary Figure 13에서는 이원 결정 과제(two-step decision task) 및 다중 구획 환경(multi-compartment environment)에서 발견된 서브골의 위치를 시뮬레이션하였다. 결과적으로, 발견된 서브골이 문(doorway)이나 결정 지점(decision points) 근처에 위치하는 경향이 있는 것으로 나타났다. 이는 높은 수준의 계획(high-level planning)을 수행할 때 자연스러운 서브골이 형성됨을 시사한다.
이러한 서브골 탐색은 SR 행렬의 할인 계수(discount factor, γ)에 따라 달라진다. 할인 계수가 큰 경우(γ ↑), SR은 더 광범위한 공간 구조를 반영하게 되며, 대규모 공간적 패턴과 연결된 격자 요소(grid components)에 투영된다(Supplementary Fig. 10). 반면, 할인 계수가 작은 경우(γ ↓)는 보다 세밀한 지역적 공간 표현이 강화된다. Supplementary Figure 6에서는 같은 공간 내의 상태들이 유사하게 인코딩되는 경향이 관찰되었으며, 이러한 클러스터 간의 연결을 정의하는 서브골이 각 고유값(eigenvalue) 임계값에 따라 달라질 수 있음을 보여준다.
격자 세포와 위계적 계획(Hierarchical Planning)의 연결
신경학적 연구에서는 entorhinal cortex의 병변(lesions)이 탐색 과제(navigation task) 수행에 부정적인 영향을 미치며, 해마에서의 순차적 활성화(temporal ordering)를 방해하는 반면, 단순한 위치 인식(location recognition) 능력에는 영향을 미치지 않는다는 결과가 보고되었다(참조: 29, 32번 논문). 이는 격자 세포(grid cells)가 단순한 공간 인코딩 역할을 넘어 공간적 계획(spatial planning) 및 위계적 계획(hierarchical planning) 과정에 필수적인 역할을 할 가능성을 시사한다.
따라서, SR 모델을 기반으로 한 격자 세포의 고유벡터는 환경을 위계적으로 구조화하는 데 기여할 수 있으며, 탐색 전략에서 서브골을 정의하는 중요한 기제(mechanism)로 작용할 수 있다. 이러한 결과는 해마-격자 세포 시스템이 단순한 공간 내비게이션뿐만 아니라, 더 복잡한 계층적 계획(hierarchical planning)에도 중요한 역할을 할 가능성이 높음을 시사한다.
Discussion
해마(hippocampus)는 오랫동안 인지 지도(cognitive map)를 형성하는 역할을 수행한다고 여겨져 왔다. 전통적인 해마 지도 개념은 공간적(spatial) 정보를 기반으로 한다는 점에서 공간 지도(spatial map)와 동일시되어 왔으나, 이는 해마의 대표적인 신경 활성 패턴을 완전히 설명하지 못한다. 예를 들어, 장소 세포(place cells)의 활성 패턴이 단순한 유클리드 공간 정보가 아니라 동물의 행동 정책(behavioral policy)이나 환경의 위상적 구조(topology)에 의해 변화하는 현상을 설명하기 어렵다. 이에 대해 본 연구에서는 해마가 단순히 공간을 인코딩하는 것이 아니라 예측적(predictive) 기능을 수행하며, 이를 강화학습(reinforcement learning, RL) 프레임워크 내에서 공식화할 수 있음을 제안하였다.
해마의 예측적 기능과 강화학습
해마의 예측적 기능과 관련된 연구는 기존에도 존재했다. 예를 들어, Gustafson & Daw는 해마에서 위상적으로 민감한 공간 표현(topologically sensitive spatial representations)이 강화학습 과정에서 중요한 역할을 한다고 제안했다. 특히, 위상적 구조를 인코딩하는 것이 복잡한 공간 환경에서의 강화학습을 용이하게 한다는 점을 보여주었다. 또한, Foster et al. (2000)의 연구에서는 장소 세포가 강화학습에서 중요한 특징(feature) 역할을 할 수 있음을 보여주었지만, 공간 표현이 위상적 구조를 명시적으로 인코딩하는 것은 아니었다.
본 연구는 이러한 선행 연구들을 확장하여, 후행 표현(successor representation, SR)이 해마에서 자연스럽게 위상적 구조를 인코딩하는 방식을 제안한다. SR은 단순한 공간적 지도보다 강화학습을 보다 효율적으로 수행할 수 있도록 한다. Dordek et al. (2016)은 가우시안 장소 세포(Gaussian place cells)의 주성분 분석(principal component analysis)을 수행한 결과, 격자 세포(grid cells)와 유사한 활성 패턴을 보인다는 점을 발견했다. 이는 해마와 내후각 피질(entorhinal cortex)에서의 공간 표현이 단순한 유클리드적 공간 정보가 아니라, 예측적 구조를 반영할 가능성을 시사한다.
SR과 모델 기반 학습(Model-based Learning)의 관계
SR은 모델-프리 학습(model-free learning)과 모델-기반 학습(model-based learning) 사이의 중간 단계에 해당하는 학습 방식으로 볼 수 있다. 모델-프리 학습에서는 강화학습 에이전트가 보상 이력(reward history)을 기반으로 캐시된 값(look-up table)을 저장하여 정책을 최적화한다. 반면, 모델-기반 학습은 보상 구조가 변화해도 유연하게 적응할 수 있지만, 트리 탐색(tree search)과 같은 비효율적인 계산이 필요하다.
SR은 이 두 가지 학습 방식의 장점을 결합한다. SR을 사용하면 예측적 표현(predictive representation)과 보상 표현(reward representation)을 분리하여 저장할 수 있으므로, 보상이 변화해도 환경의 상태 전이(state transition dynamics)를 재학습할 필요 없이 빠르게 가치(value) 재계산이 가능하다. 예를 들어, 문맥 사전 노출 촉진 효과(context pre-exposure facilitation effect)는 동물이 환경을 사전 탐색할 기회를 가질 경우 이후 공포 조건화(fear conditioning)가 더 빠르게 학습된다는 연구 결과이다.(Rudy et al., 2004).
기존 연구에서는 이러한 현상이 해마가 문맥적 표현(conjunctive representation)을 형성하기 때문이라고 해석해 왔다. 그러나 SR 모델을 적용하면, 해마가 사전 탐색 과정에서 해당 환경의 예측적 표현을 학습하고, 이후 공포 자극(shock)이 발생했을 때 이 정보를 기반으로 빠르게 학습을 진행할 수 있음을 설명할 수 있다(Supplementary Figure 14 참조).
SR과 해마 내 모델 기반 탐색(Model-based Search)의 결합
해마에서 예측적 인코딩(predictive encoding)과 관련된 또 다른 연구는 세타 위상(theta phase)와의 정렬(alignment)을 기반으로 한 순차적 코딩(sequential coding)이다 (Hasselmo, 2005). 해마에서는 샤프 웨이브-리플(sharp wave-ripple) 이벤트 중에 특정 행동 경로를 재생(replay)하는 것이 모델 기반 탐색(model-based search)과 연결될 수 있음이 밝혀졌다(Foster & Wilson, 2006).
그러나 SR 모델은 이러한 모델 기반 탐색과 달리, 예측적 비율 코딩(predictive rate coding)을 기반으로 동작한다. 예를 들어, 역방향 확장(backward expansion)을 통해 장소 세포(place cells)가 특정 환경에서 뒤쪽 방향으로 확장되는 현상을 설명할 수 있다(Supplementary Note Section 1 참조).
SR은 기존의 모델 기반 탐색을 완전히 대체할 수는 없지만, 탐색 범위를 확장하는 기능을 수행할 수 있다. 예를 들어, 해마에서 순차적 탐색(sweep)이 SR 공간에서 수행된다면(Supplementary Figure 15f, g 참조), 기존보다 더 먼 미래 상태를 예측하는 것이 가능해질 수 있다. 이는 부트스트랩된 탐색(bootstrapped search) 알고리즘과 유사한 개념이다 (Sutton, 1990).
SR 모델의 한계와 보완 기제
SR 모델이 훈련되는 방식은 동물이 경험한 정책(policy)에 따라 학습된다는 점을 특징으로 한다. 보상이 변화하면, 기존의 SR을 활용하여 새로운 가치 함수(value function)를 계산하지만, 이는 이전 정책을 기반으로 하기 때문에 최적 정책과 일치하지 않을 가능성이 있다. 이 문제는 정책 일반화(policy generalization) 또는 탐색 기반 업데이트(sweep-based update)를 통해 해결할 수 있다.
예를 들어, Dyna 모델(참조: 46번 논문)은 환경 모델을 기반으로 통계적 정보를 업데이트하는 방식을 제안하며, SR 역시 이러한 방식으로 업데이트될 수 있다. 인간 실험에서도 보상이 변경될 경우 정책-의존적(policy-dependent) 방식으로 가치 재평가(revaluation)가 이루어진다는 증거가 보고되었다(Gläscher et al., 2010).