
Tools of the Trade Multivoxel pattern analysis in fMRI: a practical introduction for social and affective neuroscientists
기능적 자기공명영상(fMRI) 데이터는 뇌의 각 지점(즉, 복셀)에서 시간별 혈중 산소 농도 의존 신호(BOLD signal) 값을 제공한다. 전통적인 단변량(univariate) 분석에서는 개별 복셀을 독립적으로 분석하거나 특정 뇌 영역 내 복셀의 신호를 평균하여 비교한다. 반면, 다중복셀 패턴 분석(MVPA)은 이러한 개별 복셀 값을 고려하는 것이 아니라, 여러 복셀에 걸친 신경 반응 패턴을 분석하여 정보를 추출한다.
MVPA는 다양한 방식으로 수행될 수 있으나, 가장 널리 사용되는 두 가지 분석 기법은 디코딩 분석(decoding analysis) 과 표상 유사성 분석(Representational Similarity Analysis, RSA) 이다. 디코딩 분석은 특정 조건에서 나타나는 신경 반응 패턴을 기반으로 조건을 예측하는 것을 목표로 하며, RSA는 서로 다른 조건 간 신경 반응 패턴의 유사성을 평가한다.
Introduction
이 논문은 다중복셀 패턴 분석(Multivoxel Pattern Analysis, MVPA) 기법을 사회 및 감정 신경과학(Social and Affective Neuroscience) 연구자들에게 실용적이고 이해하기 쉬운 방식으로 소개하는 것을 목표로 한다. 기존의 fMRI 데이터 분석에서는 단변량(univariate) 또는 질량 단변량(mass-univariate) 접근법이 일반적으로 사용되었다. 이러한 방법들은 특정 실험 조건에서 개별 복셀(voxel)이나 특정 뇌 영역의 평균 신호 강도를 분석하는 방식이다. 예를 들어, 공포 유발 자극(fear-inducing stimuli) 이 중립 자극보다 편도체(amygdala) 의 활성화를 더 크게 유발하는지를 평가하는 것이 대표적인 단변량 접근법이다.
단변량 분석의 특징은 각 조건당 단 하나의 값을 고려한다는 점이다. 즉, 한 실험 조건에서 특정 복셀 또는 뇌 영역의 평균 신호 강도만 분석 대상으로 삼는다. 이 방법은 신경 활성의 전반적인 강도 변화를 평가하는 데 적절하지만, 다중 복셀에 걸친 패턴 정보는 포착하지 못하는 한계가 있다. 반면, 최근 들어 연구자들은 개별 복셀이 아니라 여러 복셀에 걸친 신경 반응 패턴(response patterns) 을 분석하는 MVPA 기법을 점점 더 많이 활용하고 있다. MVPA는 특정 조건에서 뇌가 정보를 어떻게 표상하는지를 이해하는 데 도움을 주며, 단순한 활성화 정도뿐만 아니라 공간적 패턴(Spatial Pattern)과 정보 내용(Information Content) 을 분석할 수 있다는 강점이 있다.
What is MVPA?
기능적 자기공명영상(fMRI) 데이터는 뇌의 각 지점(복셀, voxel)에서 매 순간(시간 반복, TR)마다 혈중 산소 농도 의존 신호(BOLD signal) 값을 기록한다. 전통적인 단변량(univariate) 분석은 이러한 데이터를 개별 복셀 단위로 분석하거나, 특정 뇌 영역 내 복셀들의 신호를 평균 내어 비교하는 방식이다. 하지만 이러한 접근법은 개별 복셀의 신호 크기만을 고려할 뿐, 복셀 간의 공간적 관계나 신호 패턴을 반영하지 못한다는 한계를 가진다.
MVPA(Multivoxel Pattern Analysis, 다중복셀 패턴 분석) 는 단변량 분석과 달리, 단순히 복셀별 신호 강도를 평가하는 것이 아니라 복셀들 사이의 반응 패턴(response pattern) 에서 정보를 찾아낸다. 즉, 특정 조건에서 뇌의 공간적 반응 패턴을 통해 어떤 정보가 표상되고 있는지를 분석하는 방법이다.
Decoding analyses
디코딩 분석은 특정 신경 반응 패턴을 기반으로 어떤 조건(자극이나 인지 상태 등)이 이를 유발했는지를 예측하는 분석 기법이다. 이는 전통적인 단변량 분석과는 추론의 방향이 반대라는 점에서 차이가 있다. 전통적인 단변량 분석은 특정 조건에서 뇌의 특정 영역이 활성화되는지 여부를 평가하는 방식으로, \(P(\text{뇌 활성} \mid \text{조건})\) 을 분석한다. 반면, 디코딩 분석은 주어진 신경 반응 패턴이 어떤 조건에서 유발되었는지를 추론하는 것으로, \(P(\text{조건} \mid \text{뇌 활성})\) 을 분석하는 접근법이다.
디코딩 분석에는 크게 두 가지 주요 방법이 있다. 첫 번째는 분류(Classification) 로, 신경 반응 패턴을 바탕으로 자극이 특정 범주(category)에 속하는지를 예측하는 방법이다. 예를 들어, 특정 신경 반응이 분노한 얼굴(angry face) 과 놀란 얼굴(surprised face) 중 어느 자극에서 유발되었는지를 예측할 수 있다. 주로 서포트 벡터 머신(SVM), 로지스틱 회귀(Logistic Regression) 등의 기계 학습 알고리즘이 사용된다. 두 번째 방법은 회귀(Regression) 로, 신경 반응 패턴을 바탕으로 연속적인 값(continuous value)을 예측하는 방식이다. 예를 들어, 주어진 신경 반응이 유발된 얼굴이 얼마나 화가 난 얼굴인지(0~100의 연속 값으로 평가)를 예측할 수 있다. 선형 회귀(Linear Regression), 랜덤 포레스트 회귀(Random Forest Regression)와 같은 알고리즘이 주로 활용된다. 디코딩 분석의 과정은 데이터 분할-학습-평가-결과 해석의 절차를 따르며, 성능은 Accuracy, Specificity, Sensitivity 등의 지표를 사용할 수 있다.
디코딩 분석은 전통적인 단변량 분석이 간과할 수 있는 정보를 효과적으로 탐지할 수 있다. Haxby et al. (2001) 의 연구는 이를 대표적으로 보여주는 사례다. 연구 참가자들에게 얼굴, 집, 의자, 신발 등의 다양한 시각 자극을 제시한 후 fMRI 데이터를 수집한 결과, 전통적인 단변량 분석으로는 특정 범주의 자극(예: 의자, 신발, 집)에 대해 명확한 신경 활성 차이를 확인할 수 없었다. 그러나 MVPA를 적용한 디코딩 분석을 수행한 결과, 복셀 패턴을 통해 각 범주를 명확히 구별할 수 있음이 밝혀졌다. 이러한 연구 결과는 이후 MVPA를 활용한 다양한 디코딩 연구로 확장되었으며, 인간이 꿈을 꾸는 동안 나타나는 신경 패턴(Horikawa et al., 2013), 듣고 있는 소리(Giordano et al., 2013), 인식하는 얼굴(Goesaert & Op de Beeck, 2013), 상상하는 인물(Hassabis et al., 2014) 등을 해독하는 연구로 이어졌다.
Representational similarity analysis
표상 유사성 분석(RSA)은 특정 자극이 유발한 신경 반응 패턴의 유사성을 분석하는 기법이다. 이는 단순히 개별 신경 반응을 비교하는 것이 아니라, 자극 간의 상대적인 관계를 분석하는 데 초점을 맞춘다. 즉, RSA는 특정 신경 반응 패턴이 나타나는지를 평가하는 것이 아니라, 서로 다른 자극들이 신경 반응 패턴에서 어떻게 구별되는지를 측정하는 방식이다.
First- vs. Second-order Isomorphisms
대부분의 신경과학 연구는 일차적 동형성(first-order isomorphism) 에 초점을 맞춘다. 이는 특정 자극이 특정한 신경 반응을 직접적으로 유발하는 관계를 의미한다. 예를 들어, 얼굴을 보면 방추회 얼굴 영역(Fusiform Face Area, FFA) 이 집을 볼 때보다 더 활발하게 반응하는 경우가 이에 해당한다. 이러한 접근법은 단순한 신경 활성화 패턴과 자극 간의 관계를 연구하는 전통적인 방식이다. 반면, RSA는 이차적 동형성(second-order isomorphism) 을 분석한다. 이는 개별 신경 반응 패턴이 아니라 자극들 간의 유사성과 차이를 비교하는 것에 초점을 맞춘다.
예를 들어 광고판에 있는 커다란 얼굴 사진과 종이에 그린 작은 웃는 얼굴을 비교해 보자. 두 이미지의 세부적인 얼굴 특징(눈, 코, 입의 모양 등)은 매우 다를 수 있다(즉, 일차적 동형성이 없음). 그러나 눈은 코보다 가깝고, 코는 입보다 위에 위치하는 등 얼굴 구성 요소들 간의 관계는 두 이미지에서 동일하다. 이것이 바로 이차적 동형성이다. 즉, 개별 요소들이 어떻게 배열되는지가 아니라 자극들 간의 상대적인 관계가 중요한 것이다.
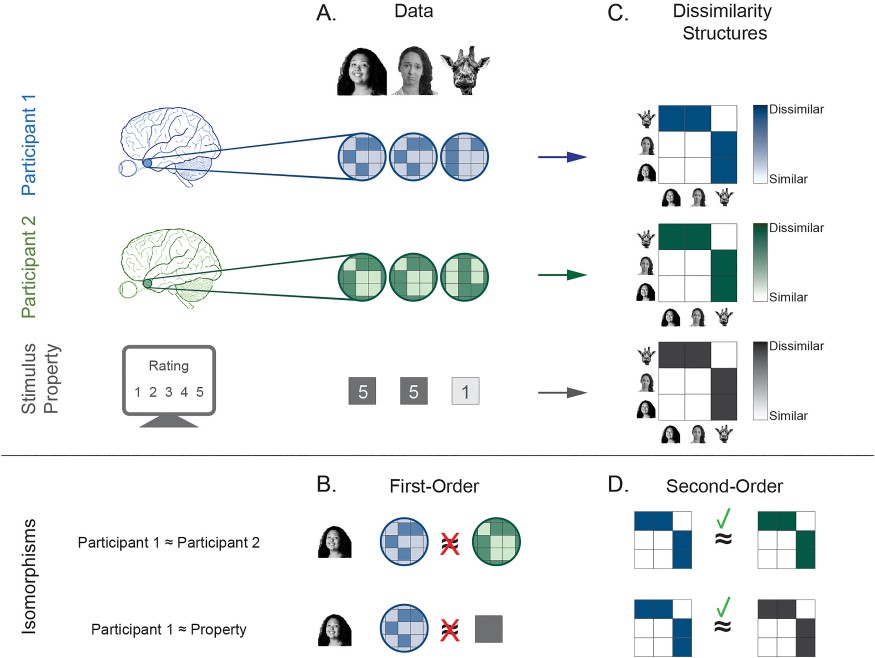
같은 방식으로, 특정 뇌 영역이 어떤 속성을 인코딩한다면, 해당 속성과 신경 반응 크기 간의 직접적인 상관관계는 보이지 않을 수 있으나 자극들 간의 유사성(예: 두 사람의 얼굴은 서로 유사하지만, 기린의 얼굴과는 다름)과 신경 반응 패턴의 유사성이 일치한다면, 그 뇌 영역이 해당 속성을 처리하고 있을 가능성이 높다고 볼 수 있다. RSA는 이러한 원리를 활용하여, 신경 반응 패턴 간의 유사성을 비교함으로써 자극 간의 상대적 관계를 분석한다. 즉, 두 개의 서로 다른 사람이 동일한 자극을 보았을 때, 개별 신경 반응 패턴 자체는 다를 수 있지만(Figure 2B), 그 신경 반응들 간의 관계는 일정하게 유지될 수 있다.(Figure 2D) 이와 같이 RSA는 개인 간 비교, 다른 측정 방식 간 비교, 모델과 신경 반응 간 비교 등을 가능하게 한다.
Comparison Across Modalities
RSA에서 가장 중요한 도구는 표상 비유사성 행렬(Representational Dissimilarity Matrix, RDM) 이다. 이는 각 자극이 유발한 신경 반응 패턴 간의 유사성을 수량화한 행렬이다. 즉, 특정 뇌 영역이 두 개의 자극을 얼마나 다르게 처리하는지를 측정하는 역할을 한다.(Figure 2C) 신경 RDM 외에도 여러 종류의 RDM을 만들 수 있다. 예를 들어,
- 행동 데이터 기반 RDM: 참가자들이 평가한 두 자극 간의 유사성(예: 두 얼굴이 얼마나 비슷한가?)을 바탕으로 생성.
- 객관적 속성 기반 RDM: 이미지의 픽셀 차이, 색상 차이, 구조적 차이를 바탕으로 생성.
- 신경망 모델 기반 RDM: 딥러닝 모델이 예측한 자극 간 유사도를 바탕으로 생성.
이러한 다양한 RDM은 신경 RDM과 비교하여 특정 뇌 영역이 어떤 속성을 중요하게 처리하는지를 분석하는 데 사용된다. 예를 들어, 특정 뇌 영역의 신경 RDM이 행동 데이터 기반 RDM과 높은 상관관계를 보인다면, 해당 뇌 영역은 사람들이 주관적으로 판단하는 자극 간의 유사성을 반영하고 있을 가능성이 높다.
Data-driven exploration of representational structure.
표상 유사성 분석(Representational Similarity Analysis, RSA)은 단순히 자극 간의 신경 반응 패턴을 비교하는 것이 아니라, 뇌가 정보를 어떻게 구조화하는지(data-driven way) 를 탐색하는 데에도 활용될 수 있다. 이를 위해 다차원 척도법(Multidimensional Scaling, MDS), 군집 분석(Clustering), 차원 축소(Dimensionality Reduction) 와 같은 데이터 분석 기법이 사용된다.
예를 들어, 연구자가 특정 뇌 영역에서 얼굴이 어떻게 표상되는지를 알고 싶다고 가정해 보자. 단순히 얼굴의 감정 표현(예: 행복, 슬픔, 분노)을 기준으로 신경 반응을 비교하는 대신, MDS를 사용하여 데이터가 자연스럽게 형성하는 군집을 시각화할 수 있다. 이를 통해, 얼굴이 감정 표현이 아니라 연령(age)에 따라 클러스터링(clustering) 되는 패턴을 발견할 수도 있다. 만약 연구자가 감정 표현만을 기준으로 분석했다면, 이러한 정보를 놓쳤을 가능성이 크다.
이는 사전에 특정 가설을 강제하지 않고 데이터가 나타내는 자연스러운 구조를 탐색할 수 있다는 점에서 중요한 장점이 있다. 즉, 데이터가 특정 속성(예: 연령, 성별, 인종 등)에 따라 구조화될 가능성을 연구자가 사전에 예측하지 않아도, RSA를 통해 자연스럽게 나타나는 구조를 발견할 수 있다.
Comparison across individuals
표상 유사성 분석(Representational Similarity Analysis, RSA)은 개별 참가자의 신경 데이터를 비교하여 특정 자극이 유발하는 신경 반응 패턴이 개인마다 어떻게 다르거나 유사한지를 분석하는 데 활용될 수 있다. 특히, RSA는 개별 참가자의 신경 반응 패턴 자체가 아니라, 자극 간 신경 반응 패턴의 유사성(Relational Similarity)을 비교하기 때문에 개인 간 차이에 덜 민감하다는 장점이 있다.
fMRI 연구에서는 일반적으로 참가자들의 데이터를 공통된 해부학적 좌표계(Talairach space, MNI space 등)로 변환하여 비교한다. 그러나 이러한 공간 정렬(spatial alignment) 방식은 개별 참가자 간의 미세한(fine-scale) 신경 반응 패턴 차이를 제대로 정렬하지 못하는 경우가 많다. 예를 들어, 방추회 얼굴 영역(Fusiform Face Area, FFA) 은 모든 참가자에서 비슷한 위치에 존재하지만, 세부적인 신경 반응 패턴은 개인마다 다를 수 있다. 이는 뇌의 대규모 기능적 구조(coarse-scale functional organization) 는 비교적 일정한 반면, 세부적인 신경 패턴(fine-scale spatial pattern) 은 개인마다 상당한 차이가 있기 때문이다. 이는 RSA를 이용하면 개별 참가자 간 신경 반응 패턴이 다를지라도, 자극 간의 신경 반응 관계(RDM, Representational Dissimilarity Matrix)가 유사하면, 두 사람이 동일한 방식으로 자극을 표상(represent)하고 있다고 해석할 수 있다.
RSA는 신경 반응 패턴 자체가 아니라, 신경 반응 간의 관계를 비교하기 때문에 개별 참가자의 신경 반응 차이에 덜 민감하다. 다시 말해, 신경 반응 패턴 자체는 다르더라도, 동일한 자극을 받았을 때의 신경 반응 관계가 유지된다면, 두 사람이 자극을 비슷하게 표상하고 있다고 해석할 수 있다.
이러한 접근법은 개인 간 신경 데이터의 정렬(alignment) 문제가 있는 경우에도 신뢰할 수 있는 비교를 가능하게 한다. 예를 들어, 딥러닝 모델이 두 개의 신경 데이터셋을 비교하려고 할 때, 직접적인 신경 반응 패턴을 정렬하는 것은 어렵지만, 신경 반응 패턴의 관계(RDM)를 비교하면 보다 일관된 결과를 얻을 수 있다.
Spatially mapping effects
신경영상 연구에서 중요한 목표 중 하나는 어떤 신경 반응이 뇌의 어느 위치에서 발생하는지를 파악하는 것이다. 이는 크게 두 가지 방법을 통해 수행될 수 있다. 영역 기반 분석 (Region of Interest, ROI-based analysis, 연구자가 사전에 특정 뇌 영역을 정의한 후, 해당 영역에서 신경 활성 패턴을 분석하는 방법이다.), 점별 분석 (Point-by-point analysis, 연구자가 사전 정의한 특정 영역이 아니라, 뇌 전체에서 개별 복셀(voxel)을 기준으로 분석하는 방법이다. 단변량 분석에서는 복셀 단위(voxel-wise) 로 분석하며, MVPA에서는 서치라이트 분석(searchlight analysis) 을 사용한다.)이다.
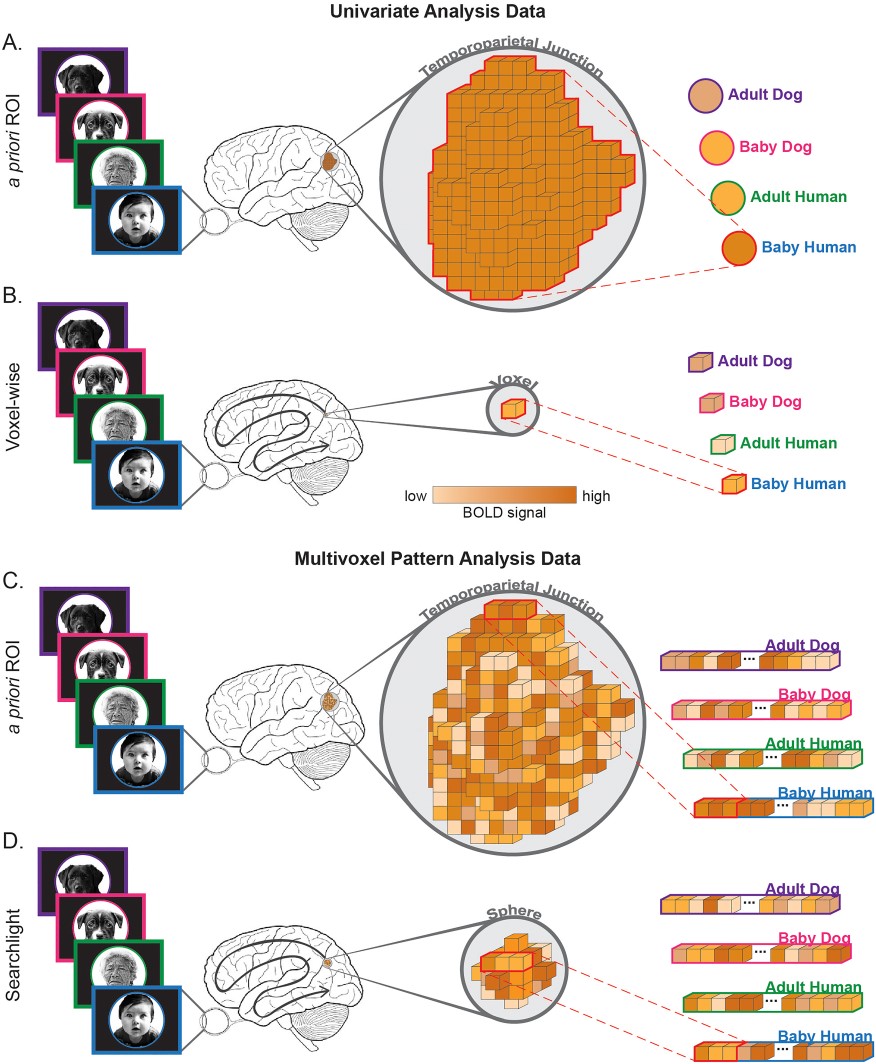
서치라이트 분석은 MVPA에서 공간적 매핑(spatial mapping) 을 수행하는 중요한 기법이다. 이는 뇌의 특정 위치에서 신경 반응 패턴이 실험 조건 간 차이를 보이는지 평가하는 방법이며, 기본적인 원리는 다음과 같다. 각 복셀을 중심으로 일정 반경(보통 8–12mm)의 구(sphere)를 설정하고, 해당 구 내의 복셀들을 이용해 MVPA를 수행하여 조건 간 차이를 평가한다. 이후 분석 결과를 구의 중심 복셀에 할당하고 이 과정을 모든 복셀에 반복하여, 뇌 전체에서 어떤 영역이 특정 조건을 구별하는 정보를 포함하는지 확인한다. 이렇게 얻어진 결과는 각 복셀을 중심으로 한 구(sphere)의 정보 판별력(distinctiveness)에 대한 맵을 생성한다. 연구자는 이 맵을 통해 특정 조건을 구별하는 데 중요한 뇌 영역이 어디인지 파악할 수 있다.
다만 서치라이트 분석은 복셀 간 공간적 관계를 반영할 수 있지만, 개별 복셀의 정보가 아니라 주변 복셀들의 패턴 차이에 의해 결과가 결정된다는 점을 고려해야 한다. 따라서 결과 해석 시, 단순히 특정 복셀에서 유의미한 차이가 나타났다고 해석하기보다는, 해당 복셀을 중심으로 한 구 내의 신경 패턴 차이가 특정 조건을 구별하는지를 평가하는 방식임을 이해하는 것이 중요하다.
Benefits of MVPA
다중복셀 패턴 분석(MVPA)은 뇌의 특정 영역이 정보를 처리하는 방식을 더 깊이 이해할 수 있도록 하는 강력한 도구이다. 단순히 뇌의 특정 영역에서 반응 강도(response magnitude) 가 증가했는지를 분석하는 단변량(univariate) 분석과 달리, MVPA는 복셀(voxel) 간의 신경 반응 패턴을 분석하여 정보 처리를 탐색한다. 이를 통해 단순한 활성화 강도를 넘어, 뇌가 특정 자극을 어떻게 구별하는지를 밝힐 수 있다.
분포된 신경 반응 패턴에서 정보를 추출하는 민감성 (Sensitivity to Information in Distributed Response Patterns)
MVPA는 개별 복셀의 활성 강도가 아니라, 복셀 간의 분포된 신경 반응 패턴에서 정보를 추출하는 방식이다. 단변량 분석에서는 개별 복셀의 신호 변화가 통계적으로 유의하지 않으면 해당 복셀은 분석에서 제외되지만, MVPA는 이러한 복셀을 포함하여 전체적인 신경 반응 패턴을 분석한다. 이로 인해, 신경 반응이 미세하게 변화하는 영역에서도 특정 조건 간의 차이를 감지할 수 있다.
뉴런 활동을 직접 측정한 연구에 따르면, 뇌는 다양한 유형의 정보를 뉴런 집단 코드(distributed neuronal population code) 로 인코딩한다. 감각 정보(Uchida et al., 2000), 운동 계획(Georgopoulos et al., 1988), 고차원 범주 정보(Kiani et al., 2007), 주관적 의사 결정(Kiani et al., 2014) 등 여러 인지 기능이 이러한 방식으로 처리된다.
비록 fMRI가 개별 뉴런 활동을 직접 측정하는 것은 아니지만, MVPA를 통해 다중복셀 패턴을 분석하면 뉴런 집단 코드에서 다루는 정보와 유사한 수준의 정보를 추출할 수 있음이 밝혀졌다(Kriegeskorte et al., 2008b; Dubois et al., 2015). 최근 연구에서는 디코딩 분석을 활용하여 특정 조건을 잘 구별하는 신경 반응 패턴을 학습한 후, 이 패턴을 RSA와 비교하는 ‘혼합 RSA(mixed RSA)’ 기법이 개발되었다. 이는 특히 저차원 시각 정보 처리 영역에서 적용되었으나, 향후 사회적 및 감정적 정보 처리 연구에서도 활용될 가능성이 크다(Khaligh-Razavi et al., 2017).
특정 뇌 영역이 정보를 조직하는 방식 분석 (Uncovering the Information Content of Brain Regions)
MVPA는 특정 뇌 영역이 다양한 자극을 어떻게 조직하고 구별하는지를 탐색할 수 있는 강력한 도구이다. 예를 들어, Peelen et al. (2010)의 연구에서는 내측 전전두엽(mPFC)과 좌측 상측두구(left superior temporal sulcus, STS) 이 얼굴, 몸짓, 목소리와 같은 다양한 감정 단서에 동일하게 반응하지만, 감정이 무엇인지(분노, 혐오, 두려움, 행복, 슬픔)를 구별하는 방식은 다중복셀 패턴에 의해 반영됨을 발견했다. 이는 STS와 mPFC가 감정을 특정한 감각 방식(얼굴, 목소리, 몸짓 등)이 아니라, 추상적인 감정적 가치(abstract emotional value)에 따라 조직하고 있음을 시사한다.
또한, MVPA는 신경 반응 패턴이 자극의 다양한 특성을 어떻게 구별하는지를 분석하여 정보가 뇌에서 어떻게 변환되는지를 탐색할 수 있다. 예를 들어, 초기 감각 피질에서 저차원 시각적 속성(예: 색상, 모양)을 처리하는 방식과, 이후 단계에서 고차원적인 의미적 범주(예: 감정, 사회적 의미)를 인코딩하는 방식 간 차이를 분석할 수 있다. 이를 통해 정보가 뇌에서 처리되는 여러 단계들을 탐색할 수 있으며, 특정 뇌 영역이 인지 과정에서 수행하는 기능적 역할을 더 정확하게 이해할 수 있다.
유사한 활성 패턴이 동일한 인지 과정을 의미하는지 검증 (Testing the Significance of Overlapping Activations Across Tasks, Domains, and Contexts)
MVPA는 동일한 뇌 영역이 서로 다른 유형의 정보(예: 사회적 보상 vs 금전적 보상)를 동일한 방식으로 인코딩하는지 여부를 탐색하는 데 유용하다. 예를 들어, 많은 연구에서 복측 선조체(ventral striatum) 가 사회적 보상(예: 칭찬, 행복한 얼굴)과 비사회적 보상(예: 돈, 주스)에 모두 반응하는 것으로 나타났다(Lin et al., 2012; Bhanji & Delgado, 2014). 하지만, 이 영역이 두 유형의 보상을 동일한 방식으로 처리하는지는 단변량 분석으로는 확인하기 어렵다.
Wake & Izuma (2017)의 연구에서는 MVPA를 활용하여 사회적 보상과 금전적 보상이 복측 선조체에서 유사한 다중복셀 반응 패턴을 유발하는지 분석하였다. 그 결과, 두 보상 유형이 유사한 패턴을 보였으며, 이는 두 보상이 공통적인 신경 기제를 공유할 가능성을 시사한다. 반면, 다른 연구에서는 특정 뇌 영역이 동일한 자극에 반응하더라도, MVPA를 수행하면 서로 다른 신경 반응 패턴을 보이는 경우도 발견되었다(Peelen et al., 2006; Downing et al., 2007).
이러한 결과는 단순히 동일한 뇌 영역이 활성화된다는 것이 반드시 동일한 정보 처리를 의미하는 것은 아니며, 반대로 다른 신경 반응 패턴을 보인다고 해서 두 과정이 전혀 관련이 없는 것도 아님을 시사한다. MVPA를 통해 상대적인 유사성과 차이를 평가함으로써, 특정 뇌 영역이 어떻게 정보를 조직하고 처리하는지를 보다 정밀하게 이해할 수 있다.
또한, MVPA는 공간적으로 정렬된 데이터에서 공통적인 ‘신경 표식(biomarkers)’을 식별하는 데에도 활용될 수 있다(Wager et al., 2013; Chang et al., 2015; Woo et al., 2017). 예를 들어, 특정 감정 상태(예: 불안, 스트레스)와 관련된 다중복셀 패턴을 찾아 개인을 넘어서 일반화 가능한 신경 지표를 정의하는 것이 가능하다. 이러한 접근법은 임상 신경과학 및 정신의학 연구에서도 점점 더 중요해지고 있다.
a note on terminology
이 논문에서 다루고 있는 MVPA(Multivoxel Pattern Analysis) 기법들은 fMRI 데이터 분석을 위해 새롭게 개발된 것이 아니며, fMRI 분석에만 국한된 방법도 아니다. MVPA에서 사용하는 분석 기법들은 이미 다양한 학문 분야와 산업에서 널리 활용되는 데이터 분석 기법이며, 신경과학뿐만 아니라 머신러닝, 통계학, 심리학에서도 오랫동안 연구되어 왔다.
MVPA에서 사용하는 디코딩 분석(decoding analysis) 은 일반적으로 (지도형) 기계 학습(supervised machine learning) 또는 통계적 학습(statistical learning) 으로도 불린다(Hastie et al., 2017). 또한 유사성 구조(similarity structure) 분석 은 1960년대부터 심리학자들이 심적 표상(mental representations) 을 연구하는 데 사용해 왔다(Shepard, 1963, 1964; Shepard & Chipman, 1970; Shepard & Cooper, 1992).
그리고 MVPA에서 사용하는 디코딩 및 유사성 분석 기법들은 fMRI 데이터뿐만 아니라, 다양한 유형의 신경영상(neuroimaging) 데이터에도 적용될 수 있다.즉, MVPA는 특정한 분석 기법 자체가 아니라, fMRI 데이터에서 다중복셀 반응 패턴을 분석하는 방법을 의미한다. 같은 데이터 분석 기법이더라도, fMRI뿐만 아니라 다양한 신경영상 데이터에도 적용될 수 있으며, 연구 목적에 따라 다양한 방식으로 활용될 수 있다.
Practical implementation
MVPA를 연구에 적용할 때는 실험 설계와 데이터 분석의 여러 요소를 신중하게 고려해야 한다. 실험 자극을 어떻게 제시할 것인지, 데이터를 어떻게 전처리할 것인지, 어떤 알고리즘을 사용할 것인지, 하이퍼파라미터를 어떻게 조정할 것인지, 어떤 특성을 선택할 것인지 등 여러 결정들이 연구 결과에 큰 영향을 미칠 수 있다. 이러한 결정들은 단순히 분석 기법에 따라 정해지는 것이 아니라, 연구 질문과 실험 패러다임에 따라 달라져야 한다. 따라서 연구자는 자신의 연구 주제를 깊이 이해하고, 적절한 분석 방법을 선택해야 한다.
Representational spatial scale
표상의 공간적 규모 (Representational Spatial Scale)
뇌가 정보를 표상하는 공간적 규모(Spatial Scale)는 실험 설계 및 데이터 분석의 여러 결정에 중요한 영향을 미친다. 연구자가 분석하려는 정보가 세밀한 수준(fine-scale)에서 표상되는지, 혹은 더 넓은 공간적 패턴(coarse-scale)에서 표상되는지를 이해하는 것이 중요하다.
예를 들어서 어떤 정보가 세밀한 공간 패턴에서 인코딩된다면(예: 얼굴 개별성을 구별하는 패턴, Kriegeskorte et al., 2007; Nestor et al., 2011), 참가자 개개인의 뇌 공간에서 분석하는 것이 적절하다. 즉, 데이터를 표준 해부학적 템플릿(MNI, Talairach 등)에 정렬하지 않고, 개별 참가자의 뇌 공간에서 분석하는 것이 바람직하다. 이러한 접근 방식은 공간 정렬 과정에서 미세한 신경 반응 패턴이 왜곡되거나 평균화되는 것을 방지할 수 있다. 따라서 디코딩 분석(Decoding Analysis)과 신경 RDM(Neural Representational Dissimilarity Matrix, Neural RDM) 계산은 개별 참가자의 원래 뇌 공간에서 수행하는 것이 적절하다. 이 경우, 공간적 스무딩(spatial smoothing)을 최소화하거나 수행하지 않는 것이 일반적이다.
반면, 감정 상태와 같은 상대적으로 넓은 영역에서 표상되는 정보를 분석하는 경우에는 더 광범위한 공간 정렬과 데이터 처리 기법을 적용하는 것이 바람직하다. 감정 상태나 사회적 정보 처리는 개별 복셀보다는 여러 뇌 영역의 상대적인 활성도 차이를 반영하는 패턴에서 표상될 가능성이 크기 때문에, 공간적 스무딩을 더 넓은 범위에서 적용하면 이러한 패턴을 보다 안정적으로 추출할 수 있다. 또한, 연구자가 참가자 간 비교(Between-subject analysis)를 수행하려면, 데이터를 표준 해부학적 템플릿(MNI, Talairach 등)에 맞추는 것이 필요하다.
실험 설계에서 공간적 규모의 영향
공간적 규모는 단순히 데이터 분석 방법뿐만 아니라, 실험 설계에도 영향을 미친다. 연구자가 분석하려는 정보가 세밀한 패턴에서 표상된다면, 개별 참가자 내에서 분석할 데이터가 충분히 확보되어야 한다. 반면, 더 넓은 패턴에서 표상되는 정보라면, 더 많은 참가자를 모집하는 것이 중요하다. 세밀한 공간적 패턴을 연구할 경우, 개별 참가자가 충분한 반복 실험(trials)을 수행해야 한다. 참가자 간 데이터 비교보다는 참가자 내 데이터 분석을 우선으로 하며, 한 명의 참가자가 수행하는 데이터량을 늘리는 것이 중요하다. 반대로 넓은 공간적 패턴을 연구할 경우, 더 많은 참가자를 모집하는 것이 중요하며, 개별 참가자당 적은 수의 반복 실험(trials)도 가능하다.
Design considerations
MVPA는 조건 간 신경 활성 패턴이 신뢰할 수 있고 체계적으로 차이가 나는지를 평가하는 분석 기법이므로, 실험 설계가 신경 활성 패턴을 안정적으로 측정할 수 있도록 최적화되어야 한다. 이를 위해 가장 중요한 요소는 잡음(noise)을 최소화하고, 조건 간 균등하게 분포되도록 하는 것이다. 실험 데이터에서 신호 대 잡음 비(signal-to-noise ratio, SNR)를 최대화하는 것이 신뢰할 수 있는 결과를 얻는 핵심이 된다.
Minimizing noise
1. 충분한 실험 반복 횟수(trials) 확보
MVPA 연구에서는 특정 조건에서 나타나는 신경 활성 패턴을 안정적으로 측정하기 위해, 각 조건에 대한 충분한 실험 반복 횟수(trials)가 필요하다. 단변량 분석에서도 소규모 표본 연구에서 발생하는 잡음을 줄이기 위해 참가자 수를 늘리는 것이 중요하듯, MVPA에서도 각 조건의 샘플 수(trials)를 충분히 확보하는 것이 중요하다.
각 참가자에게 가능한 한 많은 실험 반복을 제공하는 것은 참가자 내 분석(within-subject analysis) 이 수행되는 경우 특히 중요하다. 참가자별로 독립적인 신경 반응 패턴을 학습하는 분석에서는 충분한 반복 실험이 필요하며, 그렇지 않으면 신경 패턴의 안정성이 떨어질 수 있다.
그러나 실험 반복 횟수의 최적 개수는 연구의 신호 대 잡음 비(SNR)에 따라 달라진다. 일반적으로 더 많은 반복이 바람직하지만, 신경 반응이 충분히 모델링될 수 있도록 자극 간 간격(interstimulus interval, ISI)을 확보하는 것이 중요하다. 이러한 이유로, MVPA에서 필요한 반복 횟수를 일반적으로 정해진 기준으로 제안하는 것은 어렵다. 마치 t-검정을 수행할 때, 효과 크기를 모른 채 무조건 20개의 데이터 포인트가 충분하다고 말할 수 없는 것과 같다. 다만, 더 세밀한 차이를 탐색하는 분석일수록 더 많은 반복 실험이 필요 하며, 실험 조건 간 신경 패턴이 명확히 구별될 경우 상대적으로 적은 반복 실험으로도 구분이 가능하다.
2. 샘플 수와 특성(feature) 수의 균형 유지
MVPA에서 디코딩 분석을 수행할 때는, 샘플 수(반복 실험 횟수, trials)와 특성(feature) 수(보통은 복셀 개수)의 비율이 중요한 역할을 한다. 일반적으로 머신러닝 알고리즘에서 훈련 데이터의 샘플 수는 특성(feature) 수보다 충분히 많아야 한다. Jain & Chandrasekaran (1982)에 따르면, 샘플 수는 특성(feature) 수보다 최소 5~10배 많아야 한다는 것이 일반적인 경험 법칙이다.
그러나 fMRI 연구에서는 현실적으로 이러한 조건을 충족하기 어려운 경우가 많다. 예를 들어, 100개의 복셀을 포함하는 ROI(뇌 영역)를 분석할 경우, 500~1000개의 반복 실험이 필요하다. 하지만, 참가자를 이렇게 오랜 시간 동안 스캔하는 것은 현실적으로 어렵다. 이 문제를 해결하는 방법 중 하나는 가능한 한 많은 반복 실험을 포함하는 것이며, 다른 방법으로는 샘플 수를 유지하면서 특성(feature) 수를 줄이는 것이 있다. 특성 수를 줄이는 방법에는 특성 선택(feature selection), 차원 축소(dimensionality reduction) 등이 있다.
또한, 참가자 간 세밀한 신경 반응 패턴을 일치시키는 하이퍼얼라인먼트(Hyperalignment, Haxby et al., 2011), 또는 다수의 참가자로부터 공통적인 신경 반응 패턴을 추출하는 공유 반응 모델(Shared Response Model, Chen et al., 2015) 등의 방법도 있다. 일부 알고리즘(SVM 등)은 상대적으로 많은 특성(feature)을 포함하더라도 잘 작동하지만, 데이터를 훈련 및 테스트 세트로 나누어야 하는 디코딩 분석에서는 충분한 반복 실험이 필요하다. 반면, RSA(표상 유사성 분석)와 같은 방법은 데이터를 훈련 및 테스트 세트로 나눌 필요가 없으므로 상대적으로 적은 샘플로도 분석이 가능하다.
3. 기타 잡음 완화 전략 (Other Ways to Mitigate Noise)
충분한 반복 실험을 포함하는 것 외에도, 자극과 관련 없는 잡음을 최소화하는 또 다른 방법은 짧은 스캔 세션(runs)을 여러 번 수행하는 것이다. 짧은 세션을 여러 번 수행하면, 실험 세션마다 독립적인 잡음이 발생하기 때문에 여러 세션을 평균내면 신경 RDM(Representational Dissimilarity Matrix)의 신뢰도가 높아지고, 패턴 분류기(classifier)의 성능이 향상될 수 있다(Coutanche & Thompson-Schill, 2012). 또한, 단일 세션 내에서 조건을 비교할 경우 발생할 수 있는 편향(bias) 을 줄이는 데도 도움이 된다(Mumford et al., 2014).
Even sampling of noise
fMRI 연구에서 발생할 수 있는 중요한 문제 중 하나는 특정 조건과 체계적으로 공변하는 잡음(noise) 이 존재할 가능성이다. 이는 MVPA 분석에서 특히 중요한데, MVPA는 조건 간 신경 반응 패턴을 구별하는 데 민감하기 때문에, 특정 조건과 잡음이 함께 변하면 연구 결과가 왜곡될 가능성이 크다. 잡음의 원인은 외부 요인일 수도 있고 참가자의 행동이나 인지적 차이때문일 수도 있지만 이러한 요인들은 잘못된 결과나 해석 오류를 초래할 수도 있으므로 최대한 통제해야 한다.(Todd et al., 2013).
MVPA 연구에서는 모든 조건에서 잡음이 균등하게 분포하도록 실험을 설계해야 한다. 실험을 여러 번 반복하는 경우, 특정 조건이 특정 run에만 존재하면 해당 조건이 시행에 의한 잡음과 함께 변할 가능성이 있다. 따라서 모든 시행에서 조건을 균등하게 포함해 신호 변화를 균등하게 샘플링하는 것이 중요하다. 또한 각 시행에서 모든 조건의 반복 횟수를 동일하게 유지해야 하며 순서 효과를 최소화할 수 있도록 순서를 최적화해야 한다.(앞의 사항들이 조건이나 결과와 공변할 수 있기 때문이다) 그리고 특정 조건이 인지적 난이도와 반응 시간 차이를 유발하는 경우 이는 결과 해석에 어려움을 겪을 수 있다.
MVPA가 단변량 분석보다 잡음에 민감한 이유
MVPA는 모든 정보를 학습하여 조건을 구별하려고 하므로, 연구자가 의도하지 않은 잡음 정보도 학습할 가능성이 있다. 단변량 분석에서는 일반적으로 특정 뇌 영역에서 신호의 강도 변화 만을 평가하지만, MVPA에서는 신경 반응 패턴의 차이를 분석하므로 신호 강도뿐만 아니라 미묘한 패턴 변화도 분석 대상이 된다. 이러한 문제를 방지하기 위해, 전통적인 잡음 샘플링 방법 외에도 MVPA 연구에 특화된 방법을 추가로 적용하는 것이 필요하다(Görgen et al., 2018).
장비 관련 잡음과 순서 효과 최소화 전략
MRI 실험에서 흔히 발생하는 잡음 중 하나는 스캐너 드리프트(scanner drift) 이다. 이는 스캔 세션 동안 신호가 서서히 변화하는 현상으로, 특정 조건이 특정 시간대에 집중적으로 등장하면 신호 변화가 실험 조건과 함께 변할 수 있다. 이를 해결하는 가장 일반적인 방법은 실험 내에서 자극 순서를 무작위화(randomization)하는 것이다(Mumford et al., 2014).
일부 연구에서는 실험 순서를 최적화하는 데 수학적 알고리즘을 활용하여 최적의 실험 설계를 도출하는 방법을 사용한다. 대표적인 기법은 다음과 같다. de Bruijn cycles (Aguirre et al., 2011)은 일정한 규칙을 유지하면서 모든 가능한 자극 조합이 고르게 나타나도록 설계하는 알고리즘으로, 특정 조건이 특정 다른 조건과 연속적으로 등장하는 빈도를 최소화할 수 있다. m-sequences (Buračas & Boynton, 2002)는 자극의 순서를 결정할 때, 특정 패턴이 반복되지 않도록 최적화하는 방법으로 주어진 실험 조건에서 가능한 모든 조합을 고르게 포함하도록 설계할 수 있다.
Analytical considerations
Analytical considerations specific to decoding analyses
MVPA에서 디코딩 분석(Decoding Analysis) 은 기계 학습(machine learning) 알고리즘을 활용하여 신경 반응 패턴에서 특정 조건(자극, 인지 상태 등)을 예측하는 방법이다. 다양한 기계 학습 알고리즘이 디코딩 분석에 사용될 수 있으며, 각 알고리즘은 데이터에서 조건을 구별하는 방식이 다르기 때문에, 연구 결과에 큰 영향을 미칠 수 있다(Douglas et al., 2011).
디코딩 분석에서 사용되는 대부분의 기계 학습 알고리즘은 각 특성(feature), 즉 fMRI 데이터에서는 개별 복셀(voxel) 에 가중치(weight)를 할당하여, 특정 조건을 예측할 수 있도록 학습한다. 이러한 알고리즘은 훈련(training) 과정에서 최적의 가중치를 찾고, 이후 검증(testing) 단계에서 새로운 다중복셀 패턴(multivoxel pattern)을 입력받아 조건을 예측하는 방식으로 작동한다.
Types of algorithms
일반적으로, 선형 분류(linear classification) 알고리즘에서는 각 샘플(예: 하나의 다중복셀 패턴)을 decision boundary 상에서 투영하여 조건을 구별하는 방식을 사용한다. 회귀(regression) 알고리즘의 경우, 연속적인 값을 예측하기 위해 각 복셀의 신호를 가중치의 조합으로 변환하는 방식을 사용한다. fMRI 연구에서 가장 많이 사용되는 선형 분류(linear classification) 알고리즘은 Linear SVM, LDA이다.
LDA는 범주 간 분산(between-category variance)을 최대화하면서, 범주 내 분산(within-category variance)을 최소화하는 방향으로 데이터 공간을 변환하는 알고리즘이다. 이 방식은 모든 변수(복셀 신호)가 정규 분포를 따르며, 동일한 분산을 가진다는 가정을 기반으로 하기 때문에 모든 샘플이 결정 경계를 정의하는 데 기여하며, 데이터의 전체적인 분포를 반영하여 분류를 수행한다. LDA의 장점은 계산 속도가 빠르고, 데이터의 전체적인 구조를 반영할 수 있다는 점이지만, 정규 분포 가정이 충족되지 않으면 성능이 저하될 수 있으며, 이상치(outlier)의 영향을 받을 가능성이 있다.
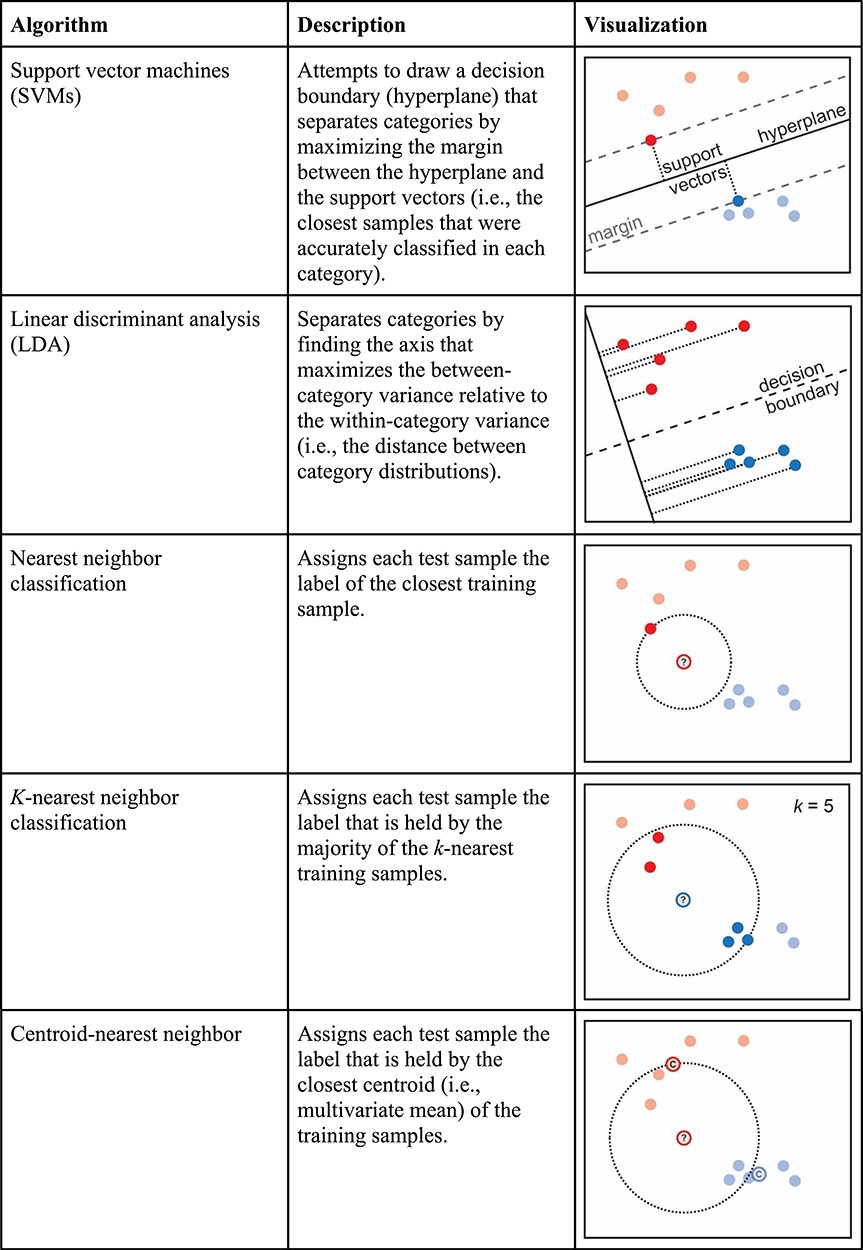
반면, SVM은 각 조건을 구별하는 최적의 초평면(hyperplane)을 찾는 방식으로 작동한다. SVM의 특징은 결정 경계와 가장 가까운 샘플들(서포트 벡터, support vectors)만을 고려하여 초평면을 결정한다는 점이다. 즉, 범주 간 거리를 최대화하는 방식으로 학습되며, 결정 경계에서 멀리 떨어진 샘플들은 모델 학습에 영향을 미치지 않는다. SVM의 장점은 소규모 데이터셋에서도 비교적 강건한 성능을 발휘하며, 이상치의 영향을 덜 받는다는 점이지만, 다중 클래스 분류(multi-class classification)에서는 추가적인 조정이 필요하며, 선형적으로 구분되지 않는 경우에는 커널(kernel) 기법을 적용해야 한다. 그 외에도 최근접 이웃 분류(Nearest Neighbor Classification) 방식이 있으며, 이는 새로운 샘플이 훈련 데이터에서 가장 가까운 샘플과 동일한 범주에 속한다고 가정하는 방법이다.
일반적으로, 모델이 학습한 가중치가 크다는 것은 해당 복셀이 조건을 구별하는 데 중요한 정보를 포함하고 있을 가능성이 크다는 것을 의미할 수 있다. 그러나, 복셀 간의 상관관계(correlation)와 데이터 정규화 방식에 따라 가중치의 해석이 왜곡될 수 있다(Pereira et al., 2009). fMRI 데이터에서 복셀들은 독립적이지 않으며, 공간적으로 인접한 복셀들끼리 높은 상관관계를 가진다. 따라서 특정 복셀이 가중치가 낮거나 0으로 설정되었다고 해서, 해당 복셀이 조건을 구별하는 데 중요하지 않다는 의미는 아니다. 또한, 분석 전에 데이터를 정규화(normalization)하면 복셀 값의 분포가 평균 0, 표준 편차 1로 조정된다. 정규화 여부에 따라 모델이 학습하는 가중치가 달라질 수 있으므로, 연구자는 정규화 여부를 신중하게 결정해야 한다.
Overfitting
Overfitting은 fMRI 데이터를 활용한 디코딩 분석에서 특히 중요한 문제로, fMRI 데이터는 일반적으로 복셀(특성, feature)의 수가 실험 반복 횟수(샘플, sample)보다 훨씬 많기 때문에 과적합이 발생하기 쉽다. 예를 들어, 특정 ROI 내에서 수백 개에서 수천 개의 복셀을 포함할 수 있지만, 한 참가자당 확보할 수 있는 실험 반복 횟수는 상대적으로 적은 경우가 많다. 이러한 데이터 특성으로 인해, 모델이 훈련 데이터에 과하게 맞춰진 최적의 가중치 조합을 찾을 가능성이 높아지며, 이로 인해 새로운 데이터에 일반화되지 않는 문제가 발생할 수 있다.
복잡한 모델일수록 훈련 데이터에 과하게 맞출 가능성이 크므로, fMRI 디코딩 분석에서는 비교적 단순한 모델(예: 비선형 모델보다는 선형 모델)을 선호하는 경우가 많다. 따라서 모델 성능을 평가할 때는 항상 훈련되지 않은 검증 데이터(test data)에서 평가하는 것이 필수적이며, 이를 통해 과적합 여부를 확인하고 모델이 새로운 데이터에서도 신뢰할 수 있는 성능을 발휘하는지 검토해야 한다.
Hyperparameter tuning
하이퍼파라미터 튜닝(Hyperparameter Tuning)은 모델이 학습하는 과정에서 영향을 미치는 추가적인 설정값을 조정하는 과정이다. 일반적으로 모델이 학습하는 파라미터(parameter) 는 훈련 데이터에서 자동으로 최적화되는 반면, 하이퍼파라미터(hyperparameter) 는 학습이 시작되기 전에 설정해야 하는 값이며, 학습 방식 자체를 결정하는 중요한 요소다. 예를 들어 선형 SVM에서는 정규화 하이퍼파라미터 C가 중요한데, 이는 훈련 데이터에서의 예측 정확도와 초평면(hyperplane) 마진을 최대화하는 균형을 조절하는 역할을 한다.
가장 단순한 하이퍼파라미터 튜닝 방법은 사용자가 설정한 여러 하이퍼파라미터 값들을 조합하여 반복적으로 모델을 훈련시키고 테스트하여 최적의 조합을 찾는 grid search이다.그러나 하이퍼파라미터 튜닝 과정이 검증 데이터(test data)에 영향을 미치지 않도록 하기 위해 nested cross validation을 사용하여 훈련 데이터를 다시 훈련용 데이터(sub-training set)와 검증 데이터(validation set)로 나누고, 다양한 하이퍼파라미터 값을 적용하여 최적의 조합을 찾은 후 최종 모델 학습에 활용한다.
Analytical considerations specific to RSA.
표상 유사성 분석(Representational Similarity Analysis, RSA)에서 신경 RDM(Representational Dissimilarity Matrix)을 생성할 때, 서로 다른 신경 반응 패턴 간의 비유사도를 계산하는 방법이 필요하다. 일반적으로 가장 널리 사용되는 방법은 피어슨 상관계수(Pearson correlation coefficient, r)를 계산한 후, 이를 비유사도로 변환하는 방식이다.
그러나 신경 반응 패턴 간 거리를 계산하는 방법에는 다양한 대안이 존재한다(Nili et al., 2014; Walther et al., 2016). 예를 들어, 유클리드 거리(Euclidean distance)는 각 복셀의 신호 차이를 제곱한 후 합산하여 제곱근을 취하는 방식으로 계산되며, 이는 신경 반응 패턴의 전체 크기 변화뿐만 아니라 공간적 패턴 차이에도 민감하다. 마할라노비스 거리(Mahalanobis distance)는 유클리드 거리와 유사하지만, 데이터의 공분산을 고려하여 정규화된 거리 측정값을 제공한다. 또한, 디코딩 분석에서 조건을 구별하는 분류 정확도(classification accuracy)를 거리 측정값으로 사용할 수도 있다.
각 거리 측정값은 데이터의 다른 측면에 민감하게 반응하며, 분석 목적에 따라 적절한 방법을 선택해야 한다. 예를 들어, 피어슨 상관계수 기반의 거리 측정값은 신경 반응 패턴의 공간적 배열 차이에는 민감하지만, 전체적인 신경 반응 강도의 변화에는 영향을 받지 않는다. 반면, 유클리드 거리는 신경 반응 패턴뿐만 아니라 전체적인 신호 크기의 변화에도 영향을 받는다. 또한, 거리 측정값의 신뢰도도 다를 수 있으며, 연속적인 측정값(예: 유클리드 거리, 피어슨 거리)이 이산적(discretized) 측정값(예: 분류 정확도)보다 더 신뢰도가 높을 수 있다(Walther et al., 2016).
General analytical considerations: processing and selecting features
fMRI 연구에서 디코딩 분석과 표상 유사성 분석(RSA)을 수행할 때, 데이터 전처리 및 복셀(feature) 선택 과정은 중요한 고려 사항이다. 여기서 ‘feature’는 일반적으로 기계 학습 알고리즘이 사용하는 예측 변수로, fMRI 연구에서는 보통 개별 복셀 또는 변환된 복셀 값이 이에 해당한다. 전처리가 완료된 후, 일반적으로 일반 선형 모델(GLM, General Linear Model) 을 사용하여 HRF를 기반으로 조건 또는 자극별 대비 맵(contrast map)을 생성한다. 이 대비 맵의 각 복셀 값은 특정 조건에서 해당 복셀에서 유발된 평균 신경 활동 수준을 나타낸다.
GLM에서는 각 복셀에 대해 베타 값(beta)과 t-값(t-statistic)이 계산되며, 이 두 값 중 하나를 분석의 feature로 사용할 수 있다. 베타 값은 특정 조건에서 혈류역학적 반응과의 관계를 수량화한 원시 값이며, t-값은 베타 값을 실험 반복 간 표준 오차(standard error)로 나누어 정규화한 값이다. 따라서, 특정 복셀에서 실험 반복 간 신경 활동 변동성이 크다면 t-값이 낮아지고, 변동성이 적다면 t-값이 높아진다.
How and when to smooth
Smoothing은 공간적 평균화를 통해 각 복셀의 신호를 인접한 복셀 값들의 가중합으로 재계산하는 과정이다. 이때, 가중치 및 포함되는 복셀의 범위는 가우시안 커널(Gaussian kernel)에 의해 결정된다. 단변량 분석에서는 잡음을 줄이고 신호 검출력을 증가시키기 위해 전처리 과정에서 공간적 스무딩이 일반적으로 수행된다. 그러나, 스무딩은 신호 패턴의 세밀한 구조를 감소시키므로, 다중복셀 패턴 분석(MVPA)에서는 오히려 해로울 수 있다.
따라서, 전처리 단계에서는 스무딩을 최소화하거나 적용하지 않는 것이 권장되며 첫 번째 수준 분석에서는 스무딩을 적용하지 않거나 최소한의 스무딩을 유지하고, 두 번째 수준 분석(집단 수준 분석)에서 스무딩을 적용하여 참가자 간 일관된 결과를 검출할 수 있도록 하는 것이 일반적이다.
Feature selection
일반적으로 fMRI 연구에서는 전뇌 대비 맵(whole-brain contrast images)을 마스킹(masking)하여 정보가 없는 복셀(예: 뇌실 내 복셀, 특정 ROI 외부의 복셀)을 제거하는 방식이 사용된다. 또한, 독립적인 데이터셋이나 메타분석을 활용하여 기능적 마스크(functional mask)를 생성할 수도 있다. 하지만 feature selection 과정은 반드시 분석에 사용되는 데이터셋과 독립적인 데이터에서 수행되어야 한다. 같은 데이터에서 ROI를 정의한 후, 동일한 데이터 내에서 MVPA를 수행하면 순환 분석(circular analysis) 문제가 발생할 수 있으며, 이는 연구자 자유도(researcher degrees of freedom)에 의해 잘못된 양성 결과(false positives)를 초래할 수 있다(Kriegeskorte et al., 2009).
특성 선택의 기준은 연구 목적에 따라 다를 수 있다. 예를 들어, 특정 조건에서 가장 강한 반응을 보이는 복셀을 선택할 수도 있고, 조건 내에서 신경 반응 패턴이 안정적인 복셀(즉, 반복 실험 간 분산이 낮은 복셀)을 선택할 수도 있으며(Mitchell et al., 2008), 조건 간 신호 변동성이 큰 복셀을 선택하거나(Pereira et al., 2009), 조건을 가장 잘 구별하는 복셀을 선택할 수도 있다(De Martino et al., 2008).
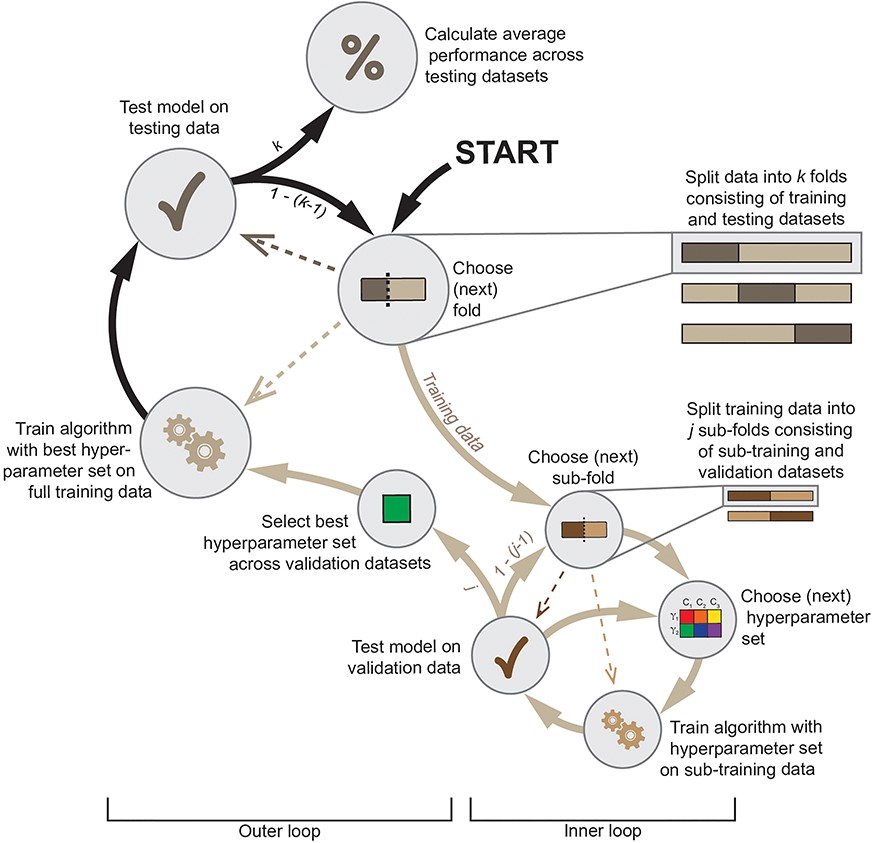
만약 동일한 데이터에서 특성 선택과 디코딩 분석을 모두 수행해야 하는 경우, 특성 선택은 훈련 데이터 내에서 독립적으로 수행해야 한다. 즉, 각 데이터 폴드(fold) 내에서 훈련 데이터를 다시 학습용(training)과 검증용(validation) 데이터로 나누어 특성 선택을 수행하는 방식(중첩 교차 검증, nested cross-validation) 을 적용할 수 있다(Figure 5).
Dimension reduction
대표적인 차원 축소 기법으로는 주성분 분석(PCA, Principal Components Analysis) 이 있으며 PCA를 사용할 경우, 연구자는 모델 학습 전에 얼마나 많은 주성분을 유지할 것인지 또는 전체 데이터 변동성의 몇 퍼센트를 유지할 것인지 nested cross-validation와 유사한 방식으로 결정할 수 있다. 이러한 기법은 fMRI 연구에서 흔히 발생하는 특성(feature) 수가 샘플(sample) 수보다 훨씬 많은 데이터 구조를 해결하는 데 유용하다. 원래 데이터의 대부분의 정보를 유지하면서도, 모델의 특성 수를 크게 줄일 수 있기 때문에, 과적합(overfitting) 방지에 효과적이며, 분석 속도를 높이고 계산 부담을 줄일 수 있다.
또한, PCA와 같은 기법은 상관관계가 높은 특성(예: 인접한 복셀 신호)을 변환하여 서로 독립적인 특성 집합을 생성하기 때문에, 개별 특성 간 독립성을 가정하는 알고리즘(예: 나이브 베이즈(Naïve Bayes), 일부 선형 회귀 알고리즘)에서 성능을 향상시키는 데 도움을 줄 수 있다.
Analytical steps
MVPA를 연구에 적용하기 위해서는 일련의 분석 단계를 거쳐야 하며, 이를 지원하는 다양한 소프트웨어 패키지가 존재한다. 파이썬 기반의 대표적인 MVPA 도구로는 Nilearn(Scikit-learn을 활용한 신경영상 데이터 분석 지원), PyMVPA, BrainIAK 등이 있으며, MATLAB 기반으로는 CoSMoMVPA, RSA Toolbox 등이 있다. 모든 분석에서 데이터 전처리와 실험 조건 설정을 반드시 수행해야 하며 이후의 분석 절차는 연구자가 수행하는 분석 유형에 따라 달라진다.
First steps
MVPA 분석의 첫 번째 단계는 실험 조건을 정의하고, 분석할 뇌 영역을 선택하는 것이다. 먼저, 실험 조건을 정의(Define the Conditions) 해야 한다. 예를 들어, 사람과 개의 얼굴을 연령별로 구분하여 네 가지 조건(아기 인간, 성인 인간, 아기 개, 성인 개)을 설정할 수 있다. 각 조건의 자극은 여러 번 반복 제시되며, 전체적으로 10개의 실험 실행(run) 동안 여러 차례 나타난다고 가정할 수 있다. 이때, 분석 단위를 조건별 평균 신경 반응(40개의 샘플, 각 조건별 10개 실행) 으로 설정할 수도 있고, 각 개별 실험 반복(trial)마다 별도로 모델링 할 수도 있다.
다음으로, 분석할 뇌 영역(Region of Interest, ROI)을 선택(Select the Region of Interest) 해야 한다. MVPA 분석은 선택한 뇌 영역에서 독립적으로 수행되며, 단일 ROI를 분석하는 경우에는 한 번만 실행되지만, 전뇌 검색(searchlight analysis) 을 수행하는 경우에는 뇌의 모든 복셀에서 반복적으로 분석이 수행된다. 이후 분석을 위해, 선택한 뇌 영역의 각 복셀 데이터를 정렬해야 한다. 각 조건에서 해당 영역의 복셀들을 벡터(vector) 형태로 변환하며, 이때 벡터의 첫 번째 복셀은 모든 조건에서 동일한 뇌 위치를 반영하도록 배치된다(Figure 1C, D).
Classification analysis
Classification에서는 데이터의 일부를 훈련(training) 데이터로 사용하여 학습한 후, 나머지 독립적인 데이터(subset)를 테스트(testing)하여 모델의 성능을 평가한다. 일반적으로 k-겹 교차 검증(k-fold cross-validation)이 사용되는데. 보통 훈련 세트에서 10~20% 정도를 테스트용으로 분할하는 것이 권장된다(Hastie et al., 2017). 예를 들어, 10개의 fMRI 실험 실행(run)을 포함하는 연구에서 5-겹 교차 검증을 수행할 경우, 10개의 실행을 5개의 부분(예: run 1-2, run 3-4, run 5-6, run 7-8, run 9-10)으로 나누고, 각 부분을 한 번씩 테스트 데이터로 사용하며 나머지 부분으로 모델을 학습하는 과정을 반복한다. leave-one-sample-out 교차 검증 은 k를 전체 샘플 수로 설정하는 방식이며, leave-one-run-out 교차 검증 은 fMRI 실험 실행 수를 k로 설정하여 각 실행(run)을 한 번씩 테스트 데이터로 사용하는 방식이다. 또한, 참가자 간 패턴 정보를 통합할 경우 leave-one-participant-out 교차 검증 을 사용할 수도 있다.
알고리즘이 특정 범주(category)를 편향적으로 예측하지 않도록 하기 위해 leave-one-run-out 교차 검증을 수행하는 것이 한 가지 해결책이 될 수 있다. 예를 들어, 연구에서 네 가지 자극(아기 인간, 성인 인간, 아기 개, 성인 개)을 사용한다면, 각 실행(run)에서 이 네 가지 자극이 동일한 빈도로 포함되도록 구성한 후, 10-겹 교차 검증을 수행하면 된다. feature selection이나 hyperparameter 선택을 수행하는 경우에는 nested cross validation을 적용해 볼 수 있다.
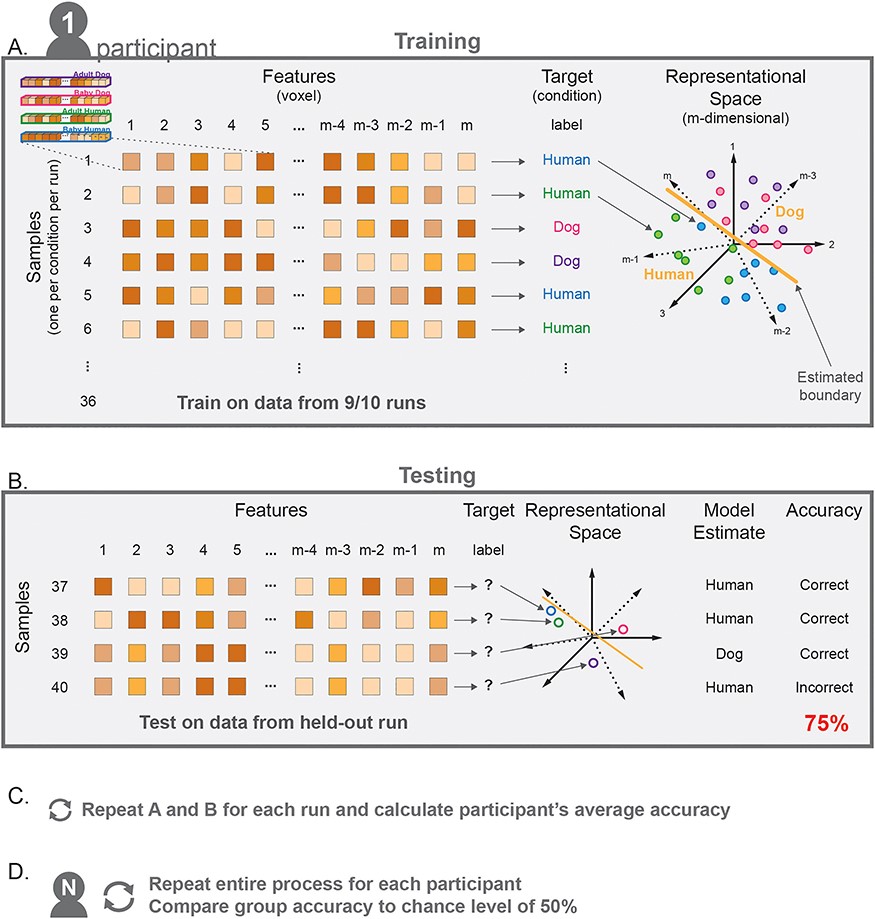
이후 모델 학습(Train Model) 단계 에서, 훈련 데이터의 각 샘플에 올바른 범주(label)를 부여한 후 알고리즘이 학습하도록 한다. 모델은 각 다중복셀 패턴을 다차원 공간상의 한 점으로 간주하며, 각 복셀이 하나의 차원에 해당한다(Figure 3). 예를 들어, m개의 복셀을 포함하는 경우, 이 데이터는 m차원 공간에서 특정 좌표를 가진다.
모델 테스트(Test Model) 단계 에서는, 학습된 모델을 검증 데이터(testing data)에 적용하여 범주를 예측하도록 한다. 테스트 데이터는 범주(label)가 없는 상태로 제공되며, 모델은 학습된 경계(boundary)를 기준으로 샘플을 분류하게 된다. 모델이 예측한 범주가 실제 범주와 얼마나 일치하는지를 계산하여 분류 정확도(classification accuracy) 를 평가한다.
MVPA에서 가장 일반적으로 사용되는 성능 지표는 분류 정확도이지만, 데이터 내 특정 범주가 과대 대표(overrepresented)됨과 같은 일부 경우 ROC(Receiver Operating Characteristic) 곡선의 면적(AUC, Area Under the Curve) 과 같은 다른 성능 측정 지표가 더 적절할 수 있다(Ling et al., 2003). 마지막으로, 모델의 평균 분류 정확도를 무작위 수준에서 기대되는 확률과 비교하여 평가한다. 예를 들어 두 개의 동등한 샘플 크기를 가진 범주를 구별하는 경우, 무작위 예측 수준에서 기대되는 정확도는 50%이며 모델이 안정적으로 기회 수준을 초과하는 분류 정확도를 보인다면, 이는 해당 뇌 영역의 신경 반응 패턴이 해당 범주를 구별할 수 있음을 시사한다.
Representational similarity analysis
표상 유사성 분석(Representational Similarity Analysis, RSA)에서는 신경 반응 패턴 간의 상대적인 차이를 나타내는 표상 비유사도 행렬(RDM, Representational Dissimilarity Matrix) 을 생성하고, 이를 활용하여 신경 데이터의 구조를 분석한다. 먼저, 신경 RDM(Neural RDM) 을 생성하기 위해, 각 자극(또는 조건)과 다른 모든 자극의 신경 반응 패턴을 비교한다. 이를 위해 각 자극의 신경 반응 패턴을 실험 실행(run) 전체에서 평균을 내어 하나의 대표 패턴을 만든다. 신경 RDM은 일반적으로 피어슨 상관 거리(Pearson correlation distance, 1 - r) 를 사용하여 각 자극 간의 유사성을 측정하지만, 유클리드 거리(Euclidean distance)나 마할라노비스 거리(Mahalanobis distance) 등 다른 거리 측정 방법도 사용할 수 있다(Figure 4A).
이렇게 계산된 거리 값들은 대칭 행렬 형태의 RDM으로 정리되며 분석 시 하위 삼각 행렬(lower off-diagonal triangle) 만 추출하여 사용한다(Figure 4A). 그다음, 비신경 RDM(Non-Neural RDM) 을 생성하여 신경 RDM과 비교할 수 있다. 예를 들어, 참가자들이 각 얼굴의 나이를 평가했다면, 각 조건 간 인식된 나이(perceived age) 차이를 계산하여 행동 RDM을 생성할 수 있다(Figure 4C). 이는 특정 뇌 영역이 얼굴을 나이에 따라 조직하는지를 테스트하는 데 활용될 수 있다.
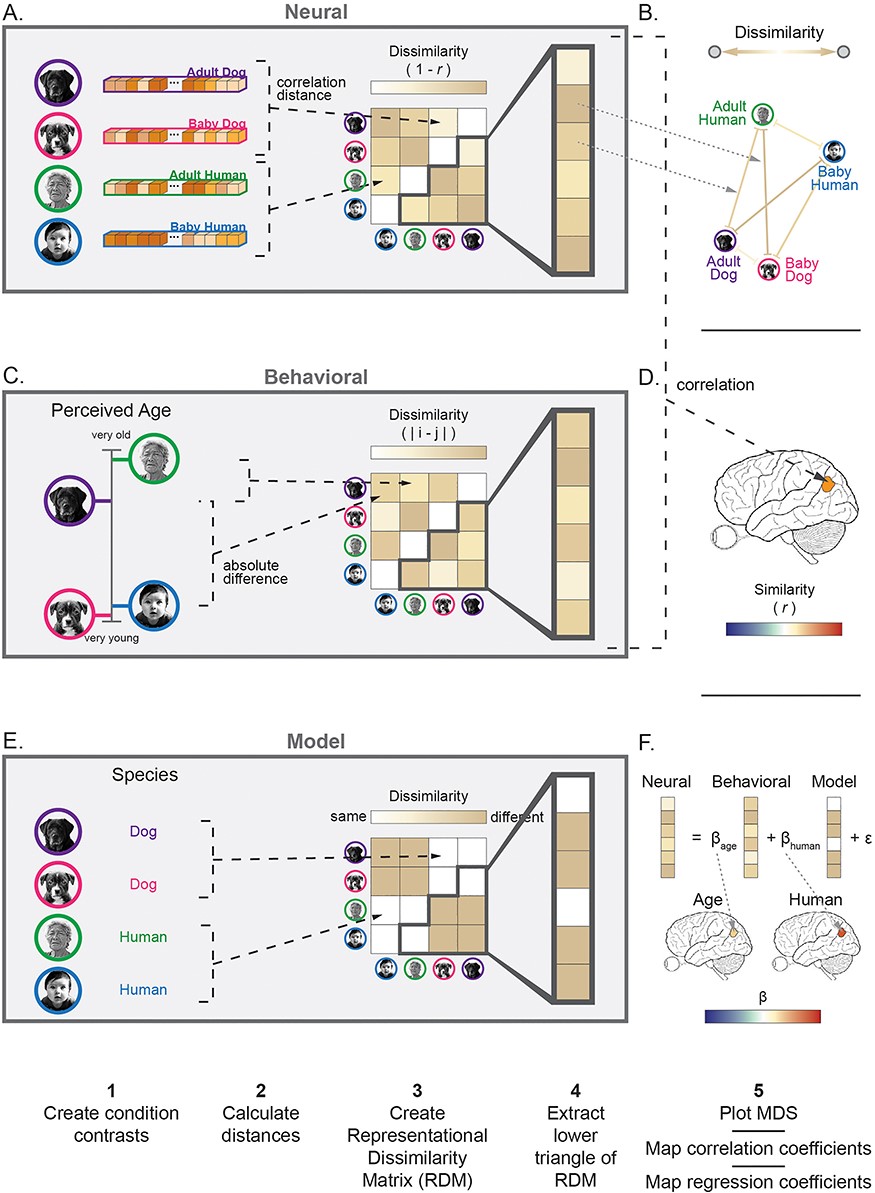
이후, 두 가지 방법 중 하나를 선택하여 분석을 수행할 수 있다. 첫 번째 옵션은 신경 RDM과 비신경 RDM을 비교(Compare Neural and Non-Neural RDMs) 하는 것이다. 이를 위해 두 RDM의 하위 삼각 행렬 간의 상관관계를 계산하는데, 피어슨 상관 대신 비선형 관계까지 포함할 수 있는 스피어만 상관(Spearman correlation) 을 사용하는 것이 일반적이다. 또한 여러 개의 예측 변수가 있는 경우 RSA 회귀 분석(RSA regression) 을 수행하여 특정 예측 변수가 신경 데이터에 미치는 영향을 개별적으로 평가할 수 있다.
두 번째 옵션은 RDM을 시각화(Visualize RDMs) 하는 것이다. RDM을 시각화할 때, 각 셀(cell)의 값에 따라 색을 부여하여, 서로 유사하게 표현되는 조건(예: 밝은 색)과 명확하게 구별되는 조건(예: 어두운 색)을 직관적으로 확인할 수 있다(Figures 2, 4). 예를 들어, 특정 뇌 영역에서 개 얼굴이 한 그룹으로 클러스터링되고, 인간 얼굴이 다른 그룹으로 구별되는 경우, 해당 뇌 영역이 종(species) 정보를 반영하는 방식으로 얼굴을 조직하고 있음을 시사할 수 있다(Figure 4B).
Statistical testing
통계적 검정(Statistical Testing)은 MVPA 분석이 완료된 후, 결과의 유의미성을 평가하는 단계이다. 상관 계수(correlation coefficient)와 분류 정확도(classification accuracy) 값은 0에서 1 사이로 제한되어 있기 때문에, 이를 변환(예: 아크사인 변환(arcsine transformation))하거나 비모수 검정(non-parametric testing, 예: 순열 검정(permutation testing)) 을 사용하는 것이 적절할 수 있다.
RSA 및 디코딩 분석 결과의 통계적 유의성을 평가하는 방법은 개별 참가자 수준(within-subject)과 집단 수준(across-subject)에 따라 각각 데이터 내 레이블을 무작위로 섞어 null distribution을 생성한 후 실제 실험 데이터를 사용하여 얻은 통계값이 귀무 분포에서 특정 임계값(예: 유의수준 α = 0.05, 단측 검정에서 95번째 백분위수)을 초과하는 경우, 결과가 유의미하다고 판단하거나 각 참가자의 데이터를 네이티브 공간(native space - searchlight분석 등)에서 분석한 경우 anatomical template에 정렬하고 추가적인 공간적 스무딩(spatial smoothing)을 적용, 단변량 연구에서 ROI(Region of Interest)나 통계적 파라메트릭 맵을 사용하여 참가자 간 유의성을 평가하는 방법과 유사하게 수행할 수 있다.
또한, MVPA 데이터(ex. searchlight 분석 결과)의 다중 비교 수정(multiple comparison correction)을 수행할 경우, 분석에 적절한 잔차(residuals)를 기반으로 매끄러움(smoothness) 값을 추정하는 것이 중요하다. 예를 들어, FWE(Family-Wise Error) 보정을 사용할 경우, 단순히 원본 반응 데이터가 아니라 검색라이트 결과의 잔차를 기준으로 매끄러움을 추정해야 한다(Linden et al., 2012).
What questions can we ask with MVPA?
MVPA는 다양한 연구 질문을 탐색하는 데 유용한 도구이며, 이를 활용하여 연구자가 답할 수 있는 주요 질문 유형에는 Brain-reading 과 Stages of Neural Processing, Underlying neurocognitive mechanisms, Individual differences가 있다.
Brain-reading
참가자가 현재 어떤 생각을 하고 있는지 또는 어떤 자극에 주의를 기울이고 있는지를 해독하는 과정이다. 만약 특정 뇌 영역에서 이 정보를 성공적으로 디코딩할 수 있다면, 해당 영역이 인간과 개의 얼굴을 근본적으로 다르게 인코딩하고 있거나, 특정 공변량(covariate)이 그 차이에 기여하고 있음을 의미할 수 있다.
Stages of neural processing
뇌가 다양한 정보를 처리하는 방식은 단순한 감각 정보에서 시작하여 점진적으로 더 추상적인 개념으로 변환되는 계층적 과정을 따른다. 예를 들어, Peelen et al.(2010)의 연구에서는 좌측 상측두구(left STS)와 배내측전전두피질(mPFC)이 감정(emotion)을 전달 매체(예: 얼굴, 몸짓, 목소리)와 무관하게 추상적인 감정적 가치(abstract emotional value)로 표현한다는 증거를 제시했다.
MVPA를 이용하면, 초기 감각 피질(early sensory cortex)에서 처리되는 저차원 감각 속성(예: 자극의 모달리티)과 후반 처리 단계에서 처리되는 고차원 의미적 속성(예: 감정적 내용) 간의 변화를 탐색할 수 있다. 이를 검증하는 한 가지 방법은, 각 뇌 영역의 신경 RDM(Neural RDM)과 모델 RDM(Model RDM, 예: 동일한 모달리티로 제시된 자극인지 여부)을 비교하여, 어떤 모델이 각 신경 처리 단계에서 가장 잘 일치하는지를 확인하는 것 이다. 또한, 다차원 척도법(MDS, Multidimensional Scaling)을 사용하여 신경 RDM을 시각화하면, 특정 자극이 각 신경 처리 단계에서 어떻게 표현되는지를 직관적으로 확인할 수 있다.
Underlying neurocognitive mechanisms
RSA를 사용하면 특정 뇌 영역이 연령(age)뿐만 아니라 종(species)에 따라 자극을 클러스터링하는지 를 발견할 수 있으며, 이를 명시적인 모델을 통해 검증할 수 있다. 즉, RSA를 통해 해당 뇌 영역이 상태(state) 또는 자극(stimulus) 표현을 조직하는 방식 을 평가할 수 있다.
디코딩 분석은 RSA와 상호 보완적으로 사용될 수 있으며, 특히 cross-classification을 활용하면 특정 정보가 다른 조건에서도 일관되게 인코딩되는지를 분석할 수 있다. 예를 들어, 인간 얼굴의 연령을 구별하도록 학습한 모델을 개 얼굴의 연령 구별에 적용할 수 있는지 테스트 할 수 있다. 만약 인간 얼굴의 연령을 학습한 모델이 개 얼굴의 연령도 신뢰성 있게 디코딩할 수 있다면, 이 뇌 영역에서 연령 정보가 종을 초월하여 일관된 방식으로 표현됨을 의미한다. 즉, 인간과 개의 얼굴 연령을 동일한 방식으로 표상하는 공통된 신경 패턴이 존재할 가능성이 크다.
Individual differences
또한, MVPA는 개인차(Individual Differences) 를 연구하는 데도 유용하다. 사람들이 세상을 인식하고 처리하는 방식이 동일한지 여부를 탐색하기 위해, 단변량 분석과 마찬가지로 MVPA 결과를 개별 차이를 예측하는 데 사용할 수 있다. 예를 들어, Ersner-Hershfield et al.(2009)의 연구에서는 현재 자아(present self)와 미래 자아(future self)의 연속성이 높은 사람들이 더 많은 퇴직 자금을 저축한다는 결과를 발견했다. 이를 fMRI 연구로 확장할 경우, 참가자의 현재 자아와 미래 자아를 표상하는 신경 반응 패턴의 유사성을 분석하고, 그 유사성이 퇴직 저축 행동을 예측하는지 테스트할 수 있다.
MVPA는 개인차 연구에서 특히 유용한데, 이는 개인차가 특정 뇌 영역의 전반적인 활성 크기(overall response magnitude) 가 아니라, 신경 패턴의 차별성(distinctiveness of neural patterns) 으로 나타날 가능성이 높기 때문이다. 즉, 단순한 활성 수준의 차이가 아니라, 개인이 정보를 신경적으로 조직하는 방식 자체가 다를 수 있으며, 이를 MVPA를 통해 보다 정교하게 분석할 수 있다.
Issues in MVPA
MVPA는 강력한 분석 도구이지만, 해석과 적용 과정에서 몇 가지 중요한 문제와 잠재적인 한계를 고려해야 한다. 특히 디코딩 분석(decoding analysis) 에서는 단순히 특정 뇌 영역이 자극을 구별할 수 있는지(yes or no)만 확인할 수 있으며, 모델 자체에 대한 심층적인 해석이 어렵다(Carlson & Wardle, 2015).
많은 MVPA 기법들은 특정 ROI의 평균 활성 크기(mean magnitude shift) 를 포착하는 데 민감하지 않지만, 단변량 분석에서는 이를 쉽게 감지할 수 있다(Davis et al., 2014; Naselaris & Kay, 2015). 반대로, 두 조건이 동일한 단변량 반응을 보이지만 다른 다중복셀 반응 패턴(multivoxel response patterns) 을 유발할 수도 있으며, 따라서 MVPA와 단변량 분석을 상호 보완적으로 사용하는 것이 바람직하다.
What are we measuring, content or process?
MVPA 해석에서 중요한 문제 중 하나는 우리가 측정하는 것이 ‘내용(content)’인지 ‘과정(process)’인지 를 명확히 구분하는 것이다. 즉, 특정 신경 패턴이 자극의 특성을 직접 인코딩(encoding) 하는 것인지, 아니면 자극 인식 이후의 연속적인 처리 과정(downstream processing)의 영향을 반영 하는 것인지 구별하는 것이 쉽지 않다. 예를 들어, 두정엽(parietal cortex)과 전운동 영역(premotor cortex)의 활성화가 도구(tool) 자극과 관련이 있는 이유에 대한 논쟁이 있다. 이는 해당 영역이 도구의 개념 자체를 인코딩하는 것인지(Mahon & Caramazza, 2008), 아니면 도구를 식별한 이후 발생하는 행동 예측(prediction of future actions) 등의 처리 과정(Martin, 2016) 을 반영하는 것인지 불분명하기 때문이다. 따라서, MVPA 결과를 해석할 때는 신경 패턴이 단순한 정보 인코딩을 의미하는지, 아니면 연속적인 인지 처리 과정과 관련된 신호인지를 신중하게 고려해야 한다.
Beyond static multivoxel response patterns
일부 연구에서는 단순히 특정 시점에서의 신경 반응 패턴을 분석하는 것보다, 시간에 따라 전개되는 심리적 과정의 신경 기제(neural mechanisms of psychological processes unfolding over time) 를 밝히는 것이 주요 목표가 될 수 있다. 이러한 경우, 시간에 따른 다중복셀 패턴의 변화(mv-pattern dynamics) 또는 기능적 연결성 패턴의 변화(functional connectivity patterns across tasks or conditions) 를 분석하는 것이 적절할 수 있다(Chang et al., 2018; R. Hyon et al., 2020; Richiardi et al., 2011; Shirer et al., 2012).
MVPA에서 사용되는 동일한 방법을 기능적 연결성 분석에 적용할 수도 있다. 예를 들어, 기능적 연결성을 기반으로 한 디코딩 분석에서는, 개별 복셀이 아닌 두 뇌 영역 간의 시간적 상관관계(correlation between time-series data from different brain regions) 를 하나의 특징(feature)로 사용한다.
Within- vs between-subject decoding
디코딩 분석에서는 충분한 훈련 데이터(training data)가 확보될수록 모델의 학습 성능이 향상되므로 분석 결과를 위해 다음의 전략을 사용해 볼 수 있다. 예를 들어, 개별 복셀 수준의 신경 반응 패턴이 아닌 기능적 연결성(functional connectivity) 을 사용하면 참가자 간 데이터 정렬 문제를 줄일 수 있다(Richiardi et al., 2011; Shirer et al., 2012). 또한, 기능적 정렬(functional alignment) 기법(Haxby et al., 2011; Chen et al., 2015) 을 활용하거나, RSA 기반 유사성 공간(similarity space)을 활용한 디코딩(Raizada & Connolly, 2012) 을 수행하면, 참가자 간의 데이터 정렬이 보다 효과적으로 이루어질 수 있다.
반면 신경 반응 패턴이 개인별로 고유할 가능성이 높은 경우처럼 참가자 간 분석보다 참가자 내 분석(within-subject decoding)이 더 적합한 경우도 존재한다. 또한, 자극이 본질적으로 개인적인 의미를 포함하는 경우(예: 개인에게 중요한 사물, Charest et al., 2014; 사회적 관계, Parkinson et al., 2017), 참가자 간 분석보다는 참가자 내 분석이 개인의 신경 패턴을 보다 정확하게 반영할 수 있다.
Imaging resolution
MVPA는 단변량 분석보다 더 정밀한 공간적 정보를 탐지할 수 있지만, 개별 뉴런 수준의 신경 활동을 직접 분석하는 기법에 비해 여전히 상대적으로 공간 해상도가 낮다. 단일 뉴런의 활동 패턴은 다양한 정보를 담고 있으며 fMRI에서 하나의 복셀(voxel)은 수십만 개의 뉴런을 포함하고 있다. 따라서 MVPA는 단변량 분석보다 세밀한 신호를 감지할 수 있지만, 훨씬 더 미세한 신경 수준의 정보를 놓칠 가능성 이 존재한다.
Examining multivoxel, rather than multi-neuron, patterns can systematically produce both false positives and false negatives
MVPA는 신경 패턴을 복셀 단위에서 분석하므로 공간 해상도가 낮다. 이러한 이유로 FP, FN의 문제가 발생할 위험이 크다. FP의 예시로는 원숭이 연구에서 안와전두피질(orbitofrontal cortex)의 서로 다른 뉴런 집단이 사회적 보상(social rewards)과 비사회적 보상(non-social rewards)을 각각 코딩 한다는 결과가 보고되었다(Watson & Platt, 2012). 그러나, fMRI의 저해상도 특성상, MVPA를 사용하면 이 두 개의 구별된 신경 집단이 하나의 공통된 인코딩 체계를 가진다고 잘못 결론내릴 가능성이 있다.
반대로 MVPA가 신경 수준에서 존재하는 중요한 정보들을 포착하지 못할 수도 있다. FN의 예시로 Dubois et al.(2015)의 연구에서는 원숭이가 얼굴을 볼 때 뉴런 수준에서는 얼굴의 정체성(identity)과 시점(viewpoint) 모두를 디코딩할 수 있었지만, MVPA 분석에서는 얼굴의 시점(viewpoint) 정보만 신뢰성 있게 디코딩할 수 있었다. 이는 시점 정보는 뉴런들이 밀집된 클러스터(cluster)로 조직되어 있지만, 얼굴 정체성 정보는 공간적으로 덜 정렬된 뉴런들에 의해 코딩되었기 때문이다.
Uncertainty about the timing of social and affective processes
사회적 또는 정서적 과정이 언제 발생하는지 정확히 알기 어려운 경우, MVPA의 적용이 어려울 수 있다. 예를 들어, 참가자가 스트레스 사건을 재평가(reappraisal)할 수 있도록 8초 동안 생각하는 시간을 제공했다면, 재평가 과정이 정확히 언제 시작되고 끝났는지 알 수 없다(Lieberman & Cunningham, 2009). 이러한 경우, 연구자는 어떤 방식으로 MVPA를 적용해야 할까?
해결 방안 1: 블록 또는 사건 단위로 분석 첫 번째 방법은, 블록(block) 전체 또는 사건(event) 전체에서 다중복셀 반응 패턴을 평균화하여 분석하는 것 이다. 이는 단변량 분석에서 특정 이벤트의 평균 신경 반응을 측정하는 방식과 유사하다. 이 접근 방식은 시간적 해상도를 희생하더라도 신뢰도 높은 신호를 확보할 수 있다.
해결 방안 2: 시점별 분석 (Time-resolved MVPA) 두 번째 방법은, 블록 내에서 각 시간 지점별로 다중복셀 패턴을 추정한 후, 시간별로 디코딩 분석 또는 RSA를 수행하여 언제 신경 패턴이 조건 간 차이를 나타내는지 분석하는 것이다(Soon et al., 2008; Cichy et al., 2014). 단, 이 방법은 참가자 간 및 실험 반복(trials) 간에 동일한 시간적 패턴이 존재할 것이라는 가정을 필요로 한다.
해결 방안 3: 시공간 패턴 분석 (Spatiotemporal Pattern Analysis) 만약 심리 과정의 타이밍이 참가자별로 다를 가능성이 높다면, 이벤트 전체에 대해 단일한 다중복셀 반응 패턴을 추정하는 방식(해결 방안 1)은 적절하지 않을 수 있다. 이를 해결하기 위해, 각 이벤트 내 서로 다른 시간 지점에서의 다중복셀 반응 패턴을 연결(concatenate)하여 하나의 확장된 특성 벡터(feature vector)로 구성한 후, 이를 기계 학습에 적용해볼 수 있다.
이러한 방법은 참가자 내 분석(within-subject decoding)에서는 각 참가자별로 서로 다른 시간 패턴을 허용할 수 있지만, 참가자 간 분석(between-subject decoding)에서는 공통된 시간적 패턴이 존재할 것이라는 가정을 필요로 한다. MVPA를 적용할 때 시간적 해상도(time resolution)가 낮다는 문제를 극복하기 위해, 연구자는 fMRI보다 더 높은 시간 해상도를 제공하는 신경영상 기법을 고려할 수도 있다. 예를 들어, MEG(Magnetoencephalography) 또는 EEG(Electroencephalography)와 같은 기법을 사용하면 시간 해상도를 획기적으로 향상시킬 수 있다.
Conclusion
이 논문에서는 사회 및 감정 신경과학 연구자를 위해 MVPA에 대한 실용적이고 접근 가능한 개요를 제공하는 것을 목표로 했다. 이를 위해, MVPA가 무엇인지, 단변량(univariate) 분석과의 차이점, MVPA를 통해 답할 수 있는 다양한 연구 질문, 그리고 MVPA를 연구에 적용하는 실용적인 절차와 고려 사항을 설명했다.