
Using deep reinforcement learning to reveal how the brain encodes abstract state-space representations in high-dimensional environments
- 논문의 이해를 위해 SARSA, Q-learning, DQN 등의 기본적인 강화학습 알고리즘, 그리고 뇌에서 일어나는 시각 처리 과정(Visual pathway)에 대한 이해를 권장합니다.
인간은 고차원적인 감각 정보를 이용하여 주어진 상황에서 결정을 내리는 데에 탁월한 강점을 가지고 있다. 그럼에도 불구하고 뇌에서 어떻게 주변의 상태를 뇌 내에서 간결하게(compactly) 표현(represent)하는지에 대해서는 명확하게 밝혀진 바가 없다. Deep reinforcement learning model 중 DQN은 고차원 입력을 nonlinear activation을 통해 action value의 형태로 반환한다. 논문의 저자는 상당히 재미있는 시도를 하였는데, DQN의 nonlinear activation이 ‘사람과 유사하게’ 일어나는지 알아보았다.
Figure 1. explanation
저자는 실험 디자인에 아타리 게임 중 Pong, Enduro, Space invaders를 사용하였다. Pong은 양 쪽에서 판들이 왔다갔다 하며 움직이는 공을 넘기는 게임, Enduro는 3인칭 시점에서 차를 좌우로 운전하며 차를 피하는 게임, 그리고 Space Invaders는 비행기를 조종하며 적을 맞추는 슈팅 게임이다. 게임의 플레이 화면은 아래의 그림에 나타나 있다.
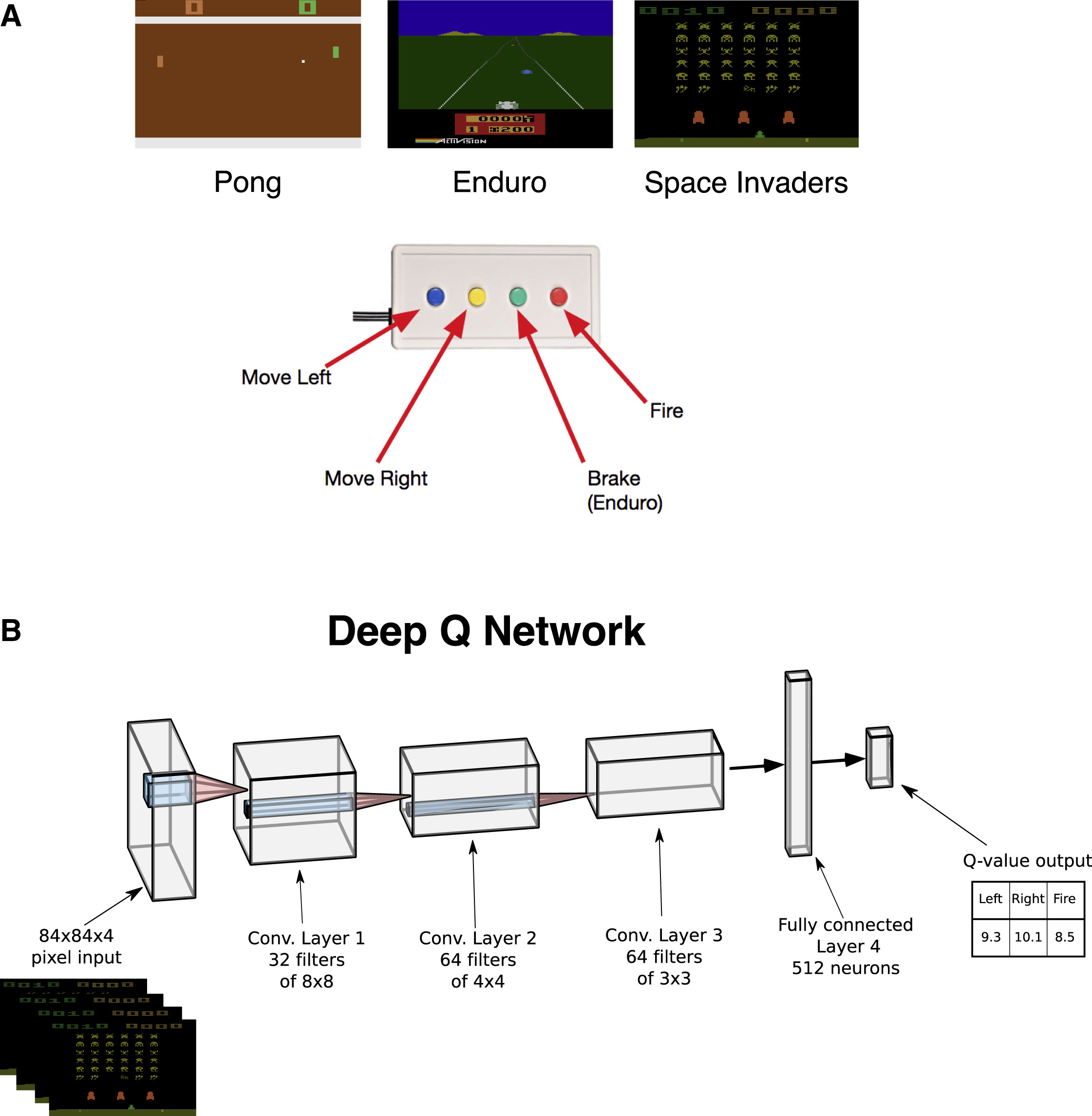
위의 두 번째 그림은 연구에서 사용한 DQN의 구조이다. DQN은 4개의 Conv layer, 1개의 FC layer, 그리고 Q-value output layer로 구성되어 있다.
앞으로 실험 결과 설명에 앞서서, 연구 디자인에 대해서 간단하게 설명하겠다. 총 6명의 참가자(이하 sub001 ~ sub006)가 존재하며, 이들이 3종류의 게임을 플레이하는 동시에 fMRI데이터를 측정하였다. 이외에 사용한 자원과 모델은 뒤에서 설명하도록 하겠다.
Figure 2. Basic concepts
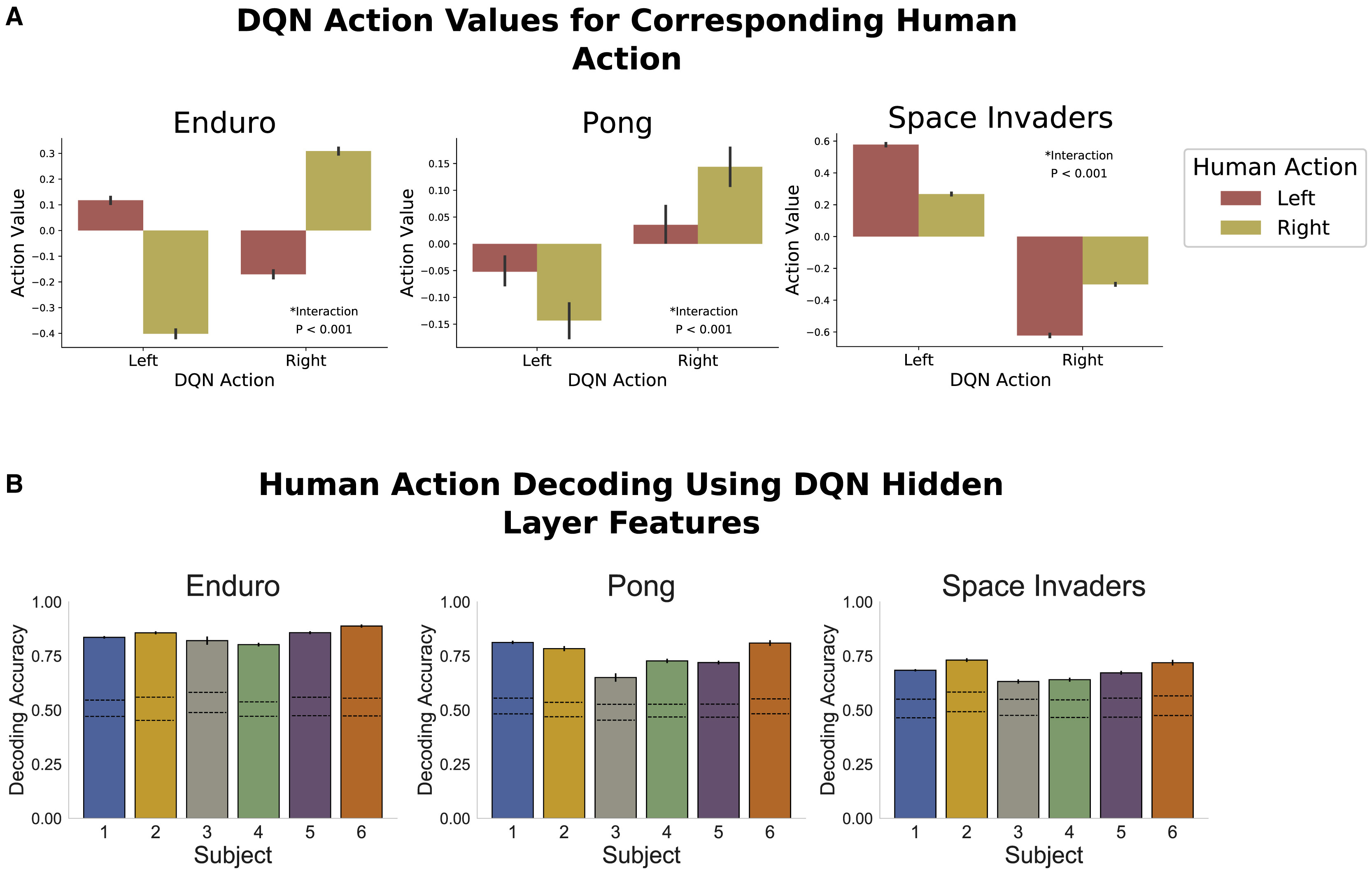
DQN 모델은 6명의 사용자와 관련없이 독립적으로 학습되었고, 각각 게임에 대해 개별적으로 학습되었다. figure 2에서는 사용자의 프레임을 주고 pretrained DQN에게 행동을 선택하도록 했고, 그 상황에서의 action value를 표시한 그림이다. 가로축은 DQN이 선택한 action, 그리고 그 상황에서 사람이 어떤 행동을 취했는지 별도로 표시하였다. 세로축은 이 행동에 대해 DQN이 평가한 action value이다. 결과를 보면 사람이 장애물을 피하기 위해 왼쪽으로 움직인 선택에 대하여 DQN도 왼쪽으로 선택하며 action value를 더 높게 평가하는 것을 볼 수 있다. 이를 통해 DQN이 인간과 유사한 방식으로 상태를 평가하고, 이를 행동에 반영할 수 있음을 알 수 있다.
아래 그림은 사용자의 게임 플레이 데이터를 DQN에 통과시켜 hidden layer의 값을 저장한 후, 이 값을을 PCA로 압축 후 100PC를 사용해 logistic regression으로 사람의 행동을 예측한 결과이다. 즉 이는 DQN으로 사람의 게임 플레이 데이터를 처리하였을 때, 이 데이터를 행동 예측에 사용할 수 있는가? 를 평가하기 위해 진행하였다고 생각하면 된다. 그 결과는 그림과 같이 6명의 참가자 모두 유의미한 정도로 행동 예측이 가능하다는 결론이 나왔다. 여기까지의 내용을 간단하게 정리하면
DQN의 내부 representation이 인간의 행동을 근사할 수 있으며, 이는 게임에 따라 예측 성능이 다르게 나타난다.
로 정리할 수 있다.
Figure 3. Encoding model
이제 DQN이 사람의 행동을 근사할 수 있다는 것 까지는 알았다. 그렇다면 ‘어떻게’ 가 밝혀져야 한다. figure 3은 DQN의 hidden layer가 사람의 뇌의 state-space representation이 어떻게 나타나는지 알아보기 위한 그림이다.
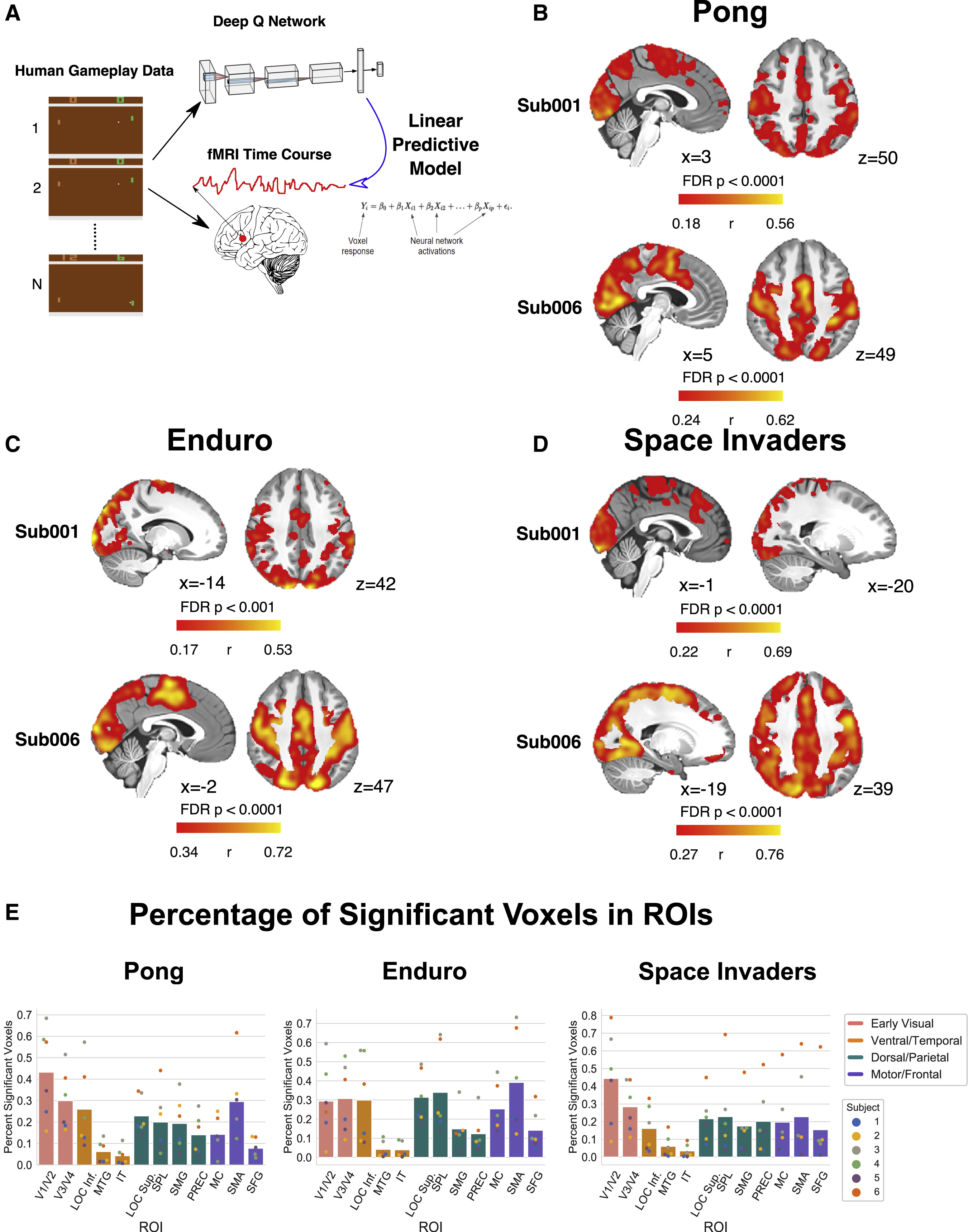
연구자들은 6명이 실험자의 게임 플레이 데이터를 DQN에 통과시킨 후, 각 4개의 hidden layer에서 PCA를 수행, 100개의 PC를 추출했다. 이 PC를 가지고 ridge regression을 수행하여 6명의 실험자의 fMRI 데이터와 대조, 각 voxel의 반응도를 예측하는 모델을 구축했다. 예측도는 원래 fMRI데이터와 대조하여 pearson correlation으로 평가되었다. 그렇게 분석을 한 결과가 위와 같은데, 결과가 꽤 인상적이다. 각 게임마다 활성화되는 부위가 조금씩 다른데, 상관계수 r가 높은 것이 유의미하게 드러나는 것을 볼 수 있다. B-D까지의 그림을 보면 공통적으로 visual cortex - posterior parietal cortex까지의 활성이 두드러지는 것을 알 수 있다.
그림 E에서는 DQN의 hidden layer에서 추출한 정보의 유의미한 voxel의 비율을 voxel을 ROI별로 분류하여 나타낸 것인데, 확실히 시각 영역(v1~v4), 공간정보처리 영역(spl, sg), 운동 영역(mc, sma, sfg)에서 유의미한 voxel 수가 많은 것을 알 수 있다. 비율이 그렇게 높지 않아 이상하게 보일 수 있지만, fMRI의 해상도가 보통 2-3세제곱밀리미터이고, 뇌에는 수천-수만개의 voxel이 존재한다는 것을 감안하면 매우 보수적인 보정을 거쳐 나온 결과이기 때문에(여기서는 자세한 보정 알고리즘은 설명하지 않음) 충분히 유의미한 결과라 해석할 수 있다. 다르게 말하면 절대적인 비율이 낮더라도 특정 voxel과 확실히 DQN의 representation이 연관된다는 점을 집중해서 해석하면 되겠다.
Figure 4. Control model
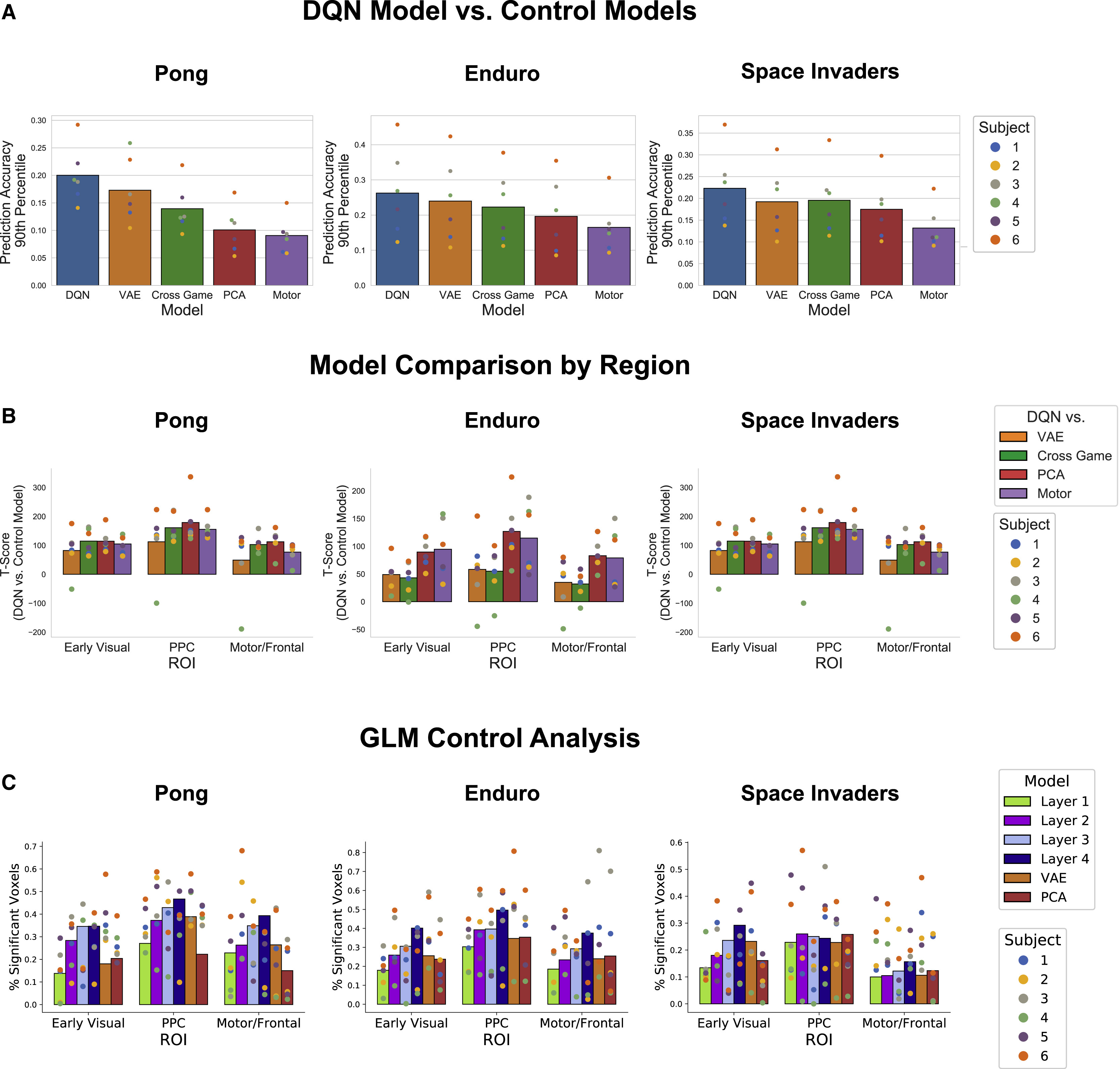
여기서부터는 DQN과 다양한 모델을 비교하면서, DQN이 얼마나 뇌의 신경 활동을 잘 설명하는지 평가해 볼 것이다. 이전과 같이 각 모델을 hidden layer에서 추출된 representation을 linear model에 통과시켜서 fMRI신호를 예측하는 방식을 사용하였다. 그림 A를 보면 DQN의 hidden layer가 VAE, Cross game model, PCA등과 비교하였을 때 예측력이 더 좋았다. 재미있는 점은 이 DQN은 다른 게임으로 학습된 DQN이라는 점이다. 즉 이 게임에 편향되어 학습한 것이 아니라 전체적인 전략을 학습한 것이라고 이해할 수 있다.
두 번째 그림에서는 게임별로 DQN을 다른 모델의 correlation과 비교하여 얼마나 우위에 있는지 T-score(student t-distribution 변환과 식이 같다)를 이용하여 정량적으로 나타낸 결과이다. 다른 모든 모델에 비교하여 정량적 우위를 나타내었으며, ROI별로 분리하여 결과를 확인하였을 때, 공간지각과 관련된 ppc에 대한 예측력이 상대적으로 높게 나타났다.
마지막 그림에서는 DQN의 layer별로 따로 예측을 시행하였고, 이번에도 다른 대조 모델들과 비교한 결과이다. 여기에서 주목할 점은 각 layer마다 예측력이 상이하였으며, 이는 게임별로 다르게 나타났다는 것이다. 저자들은 pong과 같이 단순한 게임 모델에서는 low-level feature을 수집하는 전반부 layer에서 예측력이 강하게 나타났다면, 조금 더 고차원적인 feature extraction이 필요한 Enduro, Space Invader에서는 후반부 layer에서 예측력이 더 높게 나타났다고 기술하였다.
Figure 5. Representational similiarity analysis
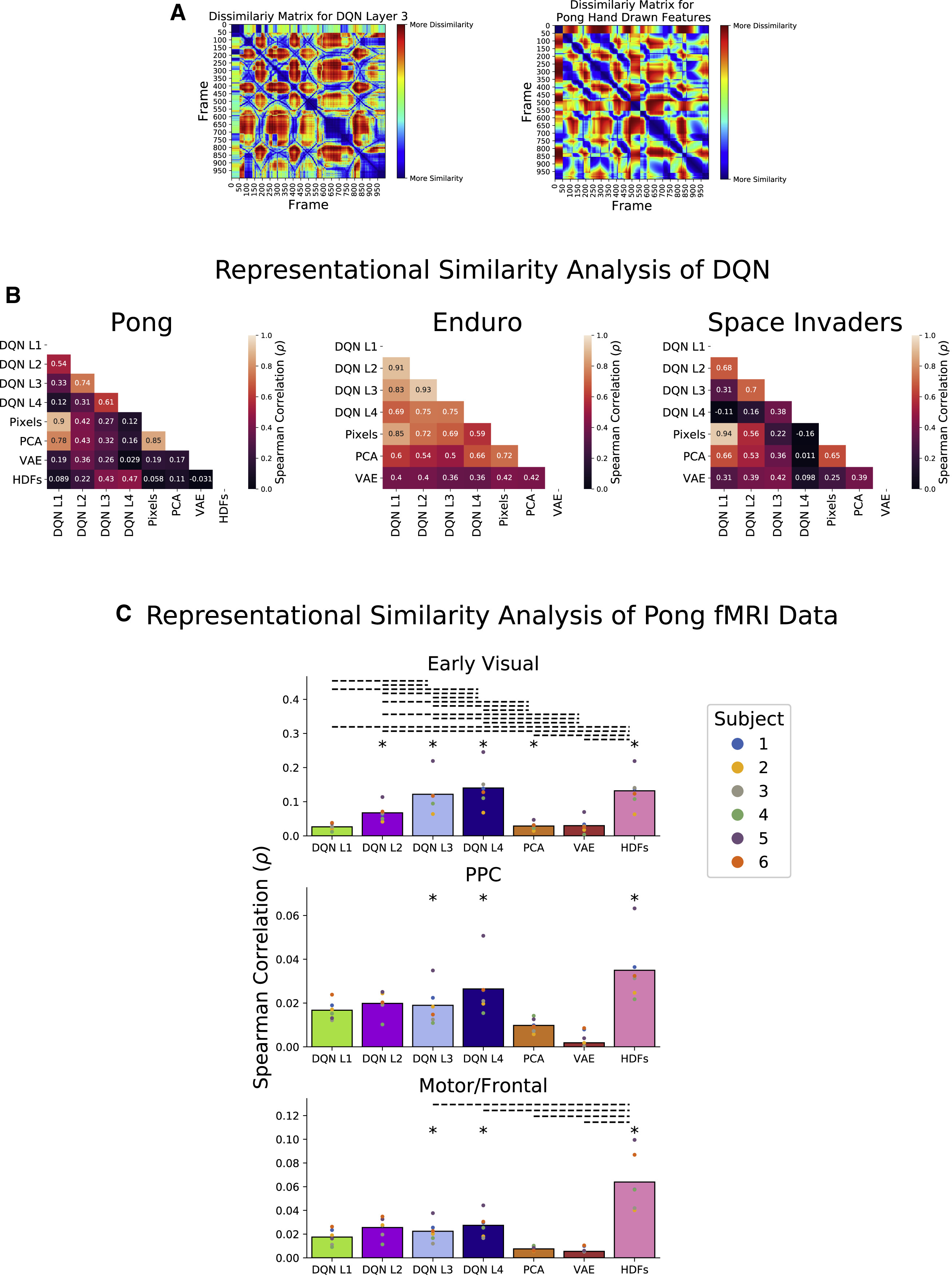
DQN이 어느 정도 예측력이 있다는 것을 알아보고 난 다음 저자들이 시행한 것은 DQN의 내부 representation 또한 인간의 state-spatial representation과 유사한 지 알아보는 과정이었다. 여기서는 representational similarity analysis (이하 RSA)라는 방법을 사용하였다. 이는 여러 고차원적인 representation을 비교하는 방법으로, 이 방법을 통해 모델의 representation change을 알아볼 것이다. 첫 번째 의 왼쪽 그림은 pong 게임에서 게임 프레임별로 DQN layer 3의 representation 간의 유사성을 측정한 dissimiliarity matrix이다. 그리고 오른쪽은 프레임 별로 수동으로 정의한 visual feature을 프레임 별로 dissimilarity matrix로 나타낸 것이다. 여기서 수동으로 정의한 feature란, 두 paddle의 위치, 공의 위치, 속도 등을 수기로 입력하여 나타낸 representation을 말한다. 두 그림을 비교하면, 완벽하지는 않지만 어느 정도 비슷해 보인다.
그림 B는 DQN의 4개 layer, hand-drawn feature, 그리고 다른 여타 모델의 내부 representation의 DSM의 상관관계(spearman)를 보여준다. 나는 여기서 왜 연구자들이 representation의 상관관계를 측정할 때 pearson correlation을 쓰지 않고 spearman rho를 사용했는지 궁금했는데, 아마 내부 representation의 경우 단순한 linear한 관계가 아닐뿐더러, 고차원적 맵핑을 비교하는 것이기 때문에 비선형성 데이터 분석에 부적합한 pearson을 배제한 것이 아닐까 하는 생각이다. 또한 dissimiarlity matrix의 경우 데이터의 상대적인 순서가 의미를 가지는 경우가 있을 수 있기 때문에 spearman 분석이 더 적합하다고 판단했던 것 같다.
전체적으로 3개 게임에서 DQN layer 3,4가 Hand drawn feature와 가장 유사한 결과가 공통적으로 나타난다.
마지막 그림에서도 representation을 DSM의 형태로 비교한 결과를 나타낸다. 다만 비교 대상이 hand drawn feature가 아닌 fMRI 데이터로 바뀌었는데, ROI별로 얼마나 유사한 결과를 나타내는지 비교하였다. 그 결과, DQN layer 4가 early visual cortex, ppc, motor/frontal cortex와 전체적인 상관관계가 높은 것으로 확인되었다. 여기까지 알 수 있는 내용은 DQN layer 3,4가 PCA, VAE보다 뇌의 representation과 유사한 표현성을 가진다는 것이다.
Figure 6. Action value results
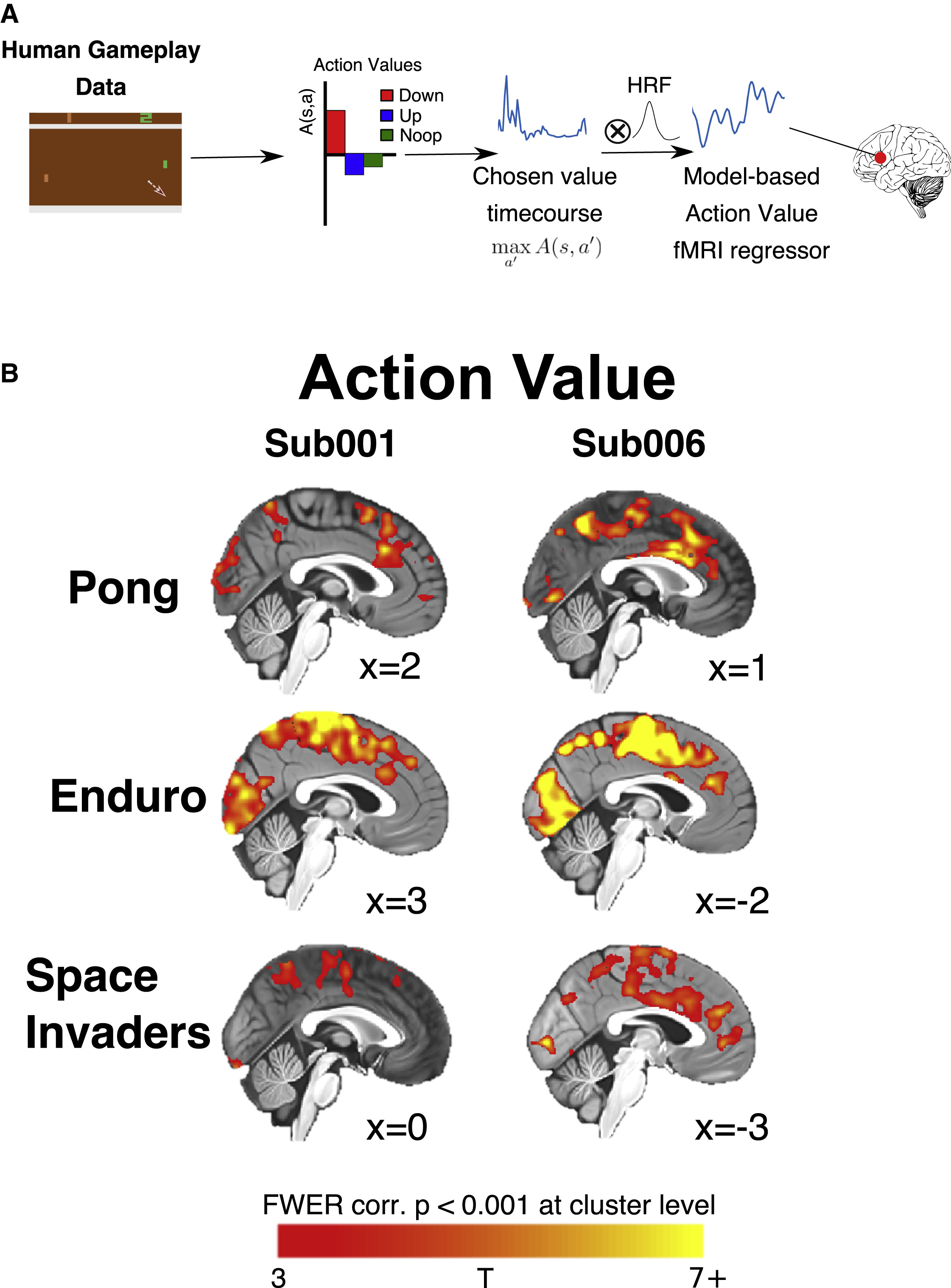
DQN의 hidden layer는 state-space를 이용, Q value를 최종 output으로 하여 action evaluation을 진행한다. 이러한 action evaluation이 뇌에서 비슷한 과정이 일어나는지 알아보기 위해 저자들은 DQN의 Q-value를 fMRI 분석에 적용해 보기로 했다. figure 6의 첫 번째 그림은 연구에 사용된 분석을 나타낸 그림이다. DQN의 Q-value를 10hz로 다운샘플링한 다음, Hemodynamic function과 Conv연산을 수행하여, 이를 GLM에 적용하였다. 이 신호를 이용해서 fMRI 반응 예측을 수행했다.
바로 아래 그림이 sub001, sub006의 분석 결과를 나타내는데, 전체적으로 운동 피질에서 유의미한 행동 표현이 관찰되었다. 이는 모든 게임에서 공통적으로 나타났다. 여기서 알 수 있는 내용은 DQN에서 평가하는 행동 가치는 운동 피질에서 인코딩되며, 시각 피질에서도 행동 가치 정보가 반영된다는 것이다.
Figure 7. Filter-based Neural Predictivity in the Brain
이전까지에서의 분석 결과로 DQN의 layer 3, 4가 뇌의 활동을 더 많이 반영하며, 게임을 플레이하는 데 있어서 몇 번의 cortical representation로부터 유용한 정보를 얻기 위해 몇 번의 nonlinear transformation이 필요하다는 것을 알게 되었다. 그런데 뇌의 서로 다른 영역은 이 layer의 다른 representation을 필요로 하지 않을까? 이런 질문은 뇌의 internal representation이 어떻게 다른 지역으로 전파되는가? 라는 질문으로도 이어질 수 있다.
DQN의 Conv filter는 모델이 input으로부터 탐지하고자 하는 바를 내포하고 있으며, 이러한 feature는 backpropagation/deconvolution을 통해 시각화할 수 있다. 이를 이용하여, 각 filter가 얼마나 voxel response를 예측할 수 있는지 알아볼 것이다. 사용자의 게임 플레이 데이터를 DQN에 입력한 후 DQN의 마지막 Conv layer (64 filters)에서 activation 값을 추출, 이를 독립적으로 사용하여 fMRI voxel 예측을 시도하였고 neural predictivity score(pearson correlation with ground truth & ridge regression result)를 통해 평가하였다.
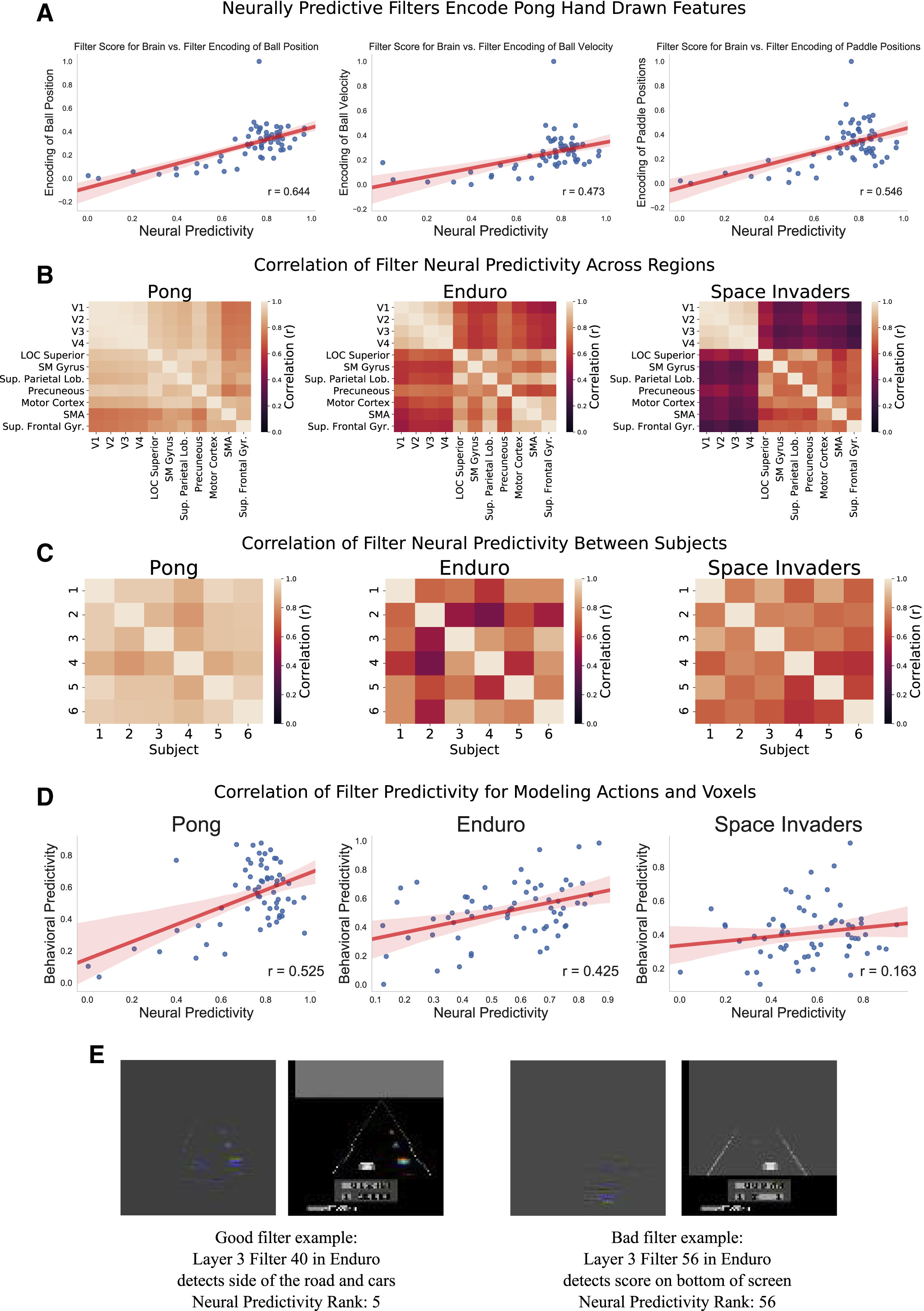
figure 7의 첫 번째 그림은 pong의 hand drawn feature과 상관 관계를 나타내었으며, 각각 공의 위치, 속도, paddle position과의 관계를 나타낸다. 그 결과 위 3가지 feature와 높은 상관관계를 갖는 필터가 발견되었다. 두 번째 그림은 region에 따른 nerual predictivity score의 상관관계를 나타낸 것이다. pong에서는 대체로 모든 roi에서 유사한 필터를 선호하는 경향성이 관찰되었다. 하지만 enduro, space invader에서는 서로 다른 roi는 서로 다른 필터와 높은 상관관계를 가지는 것으로 분석되었다. 또한 이러한 경향성은 모든 참가자 간에서 일관성 있게 유지되는 모습을 보였다.
마지막 그림은 filter가 투영하는 정보의 예시 자료인데, neural predictivity score가 높은 필터인 왼쪽 에시는 실제로 집중해야 하는 차와 도로 양 끝에 집중하는 모습을 보였고, neural predictivity score가 낮은 오른쪽 필터에서는 실제로 플레이하는 데 중요하지 않은 스코어 보드에 집중하는 모습을 보였다.
Figure 8. Representations become more insensitive to nuisances in posterior parietal cortex
그렇다면 DQN에서 학습한 표현은 시각적으로 무관한 변화(nuisance variable)로부터 얼마나 자유로울까? 예를 들어 위의 enduro의 예시에서, 자동차의 위치와 양 도로의 끝은 중요한 시각적 정보이나 스코어 보드는 상대적으로 중요도가 떨어진다. 이를 어떻게 반영할까? 아래의 첫 번째 그림에서 enduro 게임을 진행하며 배경이 지속적으로 변하지만 이는 게임 내 행동 선택과는 무관하다. 따라서 게임의 프레임에서 이러한 정보들을 배제한 상태에서 nonlinear transformation을 통해 같은 행동을 필요로 하는 장면만 같은 상태로 묶어야 한다.
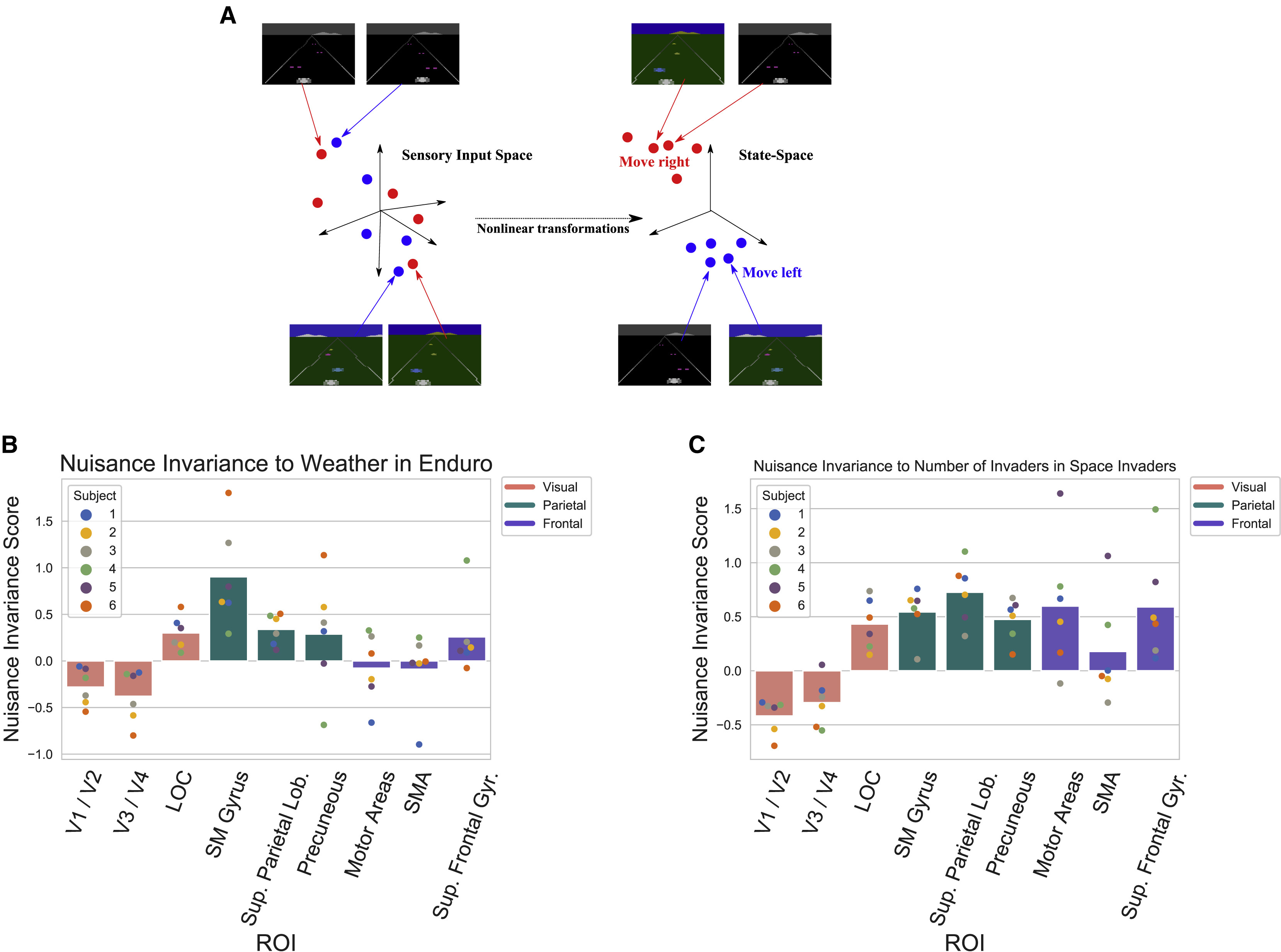
figure B에서 enduro를 분석할 때 날씨 변화를 nuisance 변수로 설정하였는데, 이 때 각 DQN 필터가 얼마나 영향을 받는지 Mutual information(MI)을 평가하였다. MI는 두 변수가 공유하는 정보량을 뜻하는데, 이는 두 변수 각각의 엔트로피의 합에서 두 변수의 결합 엔트로피를 빼서 구할 수 있다. 필터 활성화 값과 nuisance 변수의 MI지수를 계산하고, 영역별 필터와의 상관관계를 분석했을 때, PPC와 premotor cortex는 MI가 낮은 필터, 즉 nuisance 정보를 배제하는 필터와 높은 상관관계를 보였다. 또한 상대적으로 저차원 정보를 수집, 처리하는 early visual cortex는 MI가 높은 필터와 높은 상관관계를 보였다. DQN의 필터 중에서도 MI가 낮은 필터일 수록 fMRI 신호 예측력이 더 높게 나타났다. 이는 우리가 시각 정보를 인지한 다음 고등 정보 처리로 넘어가는 dorsal stream과 유사성을 지녀 개인적으로 놀라웠다. 인간의 뇌에서 dorsal stream을 따라 강화학습과 유사한 정보 처리를 수행할 가능성이 크다는 것을 시사한다.
Conclusion/Contribution
이 논문은 심층 강화학습(Deep Reinforcement Learning, DRL) 모델인 DQN이 인간의 뇌에서 상태-공간(state-space) 정보를 어떻게 표현하는지를 탐구하였다. 기존 연구들은 강화학습의 행동 정책(policy)이 인간의 의사결정 과정과 어떻게 유사한지를 다뤄왔지만, 본 연구는 한 단계 더 나아가 강화학습이 학습하는 내부 상태 표현이 뇌의 신경 활동과 구조적으로 얼마나 일치하는지를 실험적으로 분석했다. 이를 위해, 연구자들은 Atari 게임을 플레이하는 인간 피험자의 fMRI 데이터를 수집하고, DQN이 동일한 환경에서 학습한 상태 표현이 신경 활동을 얼마나 잘 설명할 수 있는지를 비교하는 접근 방식을 채택했다.
본 연구의 가장 중요한 기여는 DQN의 내부 표현이 인간의 뇌에서 특정한 신경 영역과 밀접하게 관련되어 있음을 실증적으로 보였다는 점이다. 특히, DQN이 학습한 상태-공간 표현이 두정엽(PPC), 전운동 피질(Premotor Cortex), 운동 피질(Motor Cortex)과 높은 연관성을 보였으며, 이는 뇌가 행동 계획과 의사결정을 수행하는 방식이 강화학습과 상당히 유사한 기제를 따를 가능성을 시사한다. 또한, 본 연구는 시각 피질(Visual Cortex)에서는 DQN의 초기 은닉층(hidden layers)이, 반면 고차원적 상태 표현이 요구되는 PPC와 같은 영역에서는 DQN의 후반부 은닉층이 더 높은 예측력을 갖는다는 점을 발견했다. 이는 뇌가 감각 정보 처리에서 점진적으로 상태-공간을 추상화하는 방식이 인공지능 모델이 학습하는 방식과 유사하다는 점을 보여준다. 더 나아가, 본 연구는 특정 필터가 게임 내 중요한 시각적 요소(예: Pong에서의 공과 패들, Enduro에서의 도로)를 추적하며, 이러한 필터가 인간 뇌의 특정 영역과 강한 상관관계를 가진다는 점을 밝혀, 강화학습 기반 모델이 뇌의 정보 처리 방식과 밀접한 연관성을 가질 가능성을 제시한다.
그러나 본 연구에는 몇 가지 한계점도 존재한다. 첫째, 연구에서 사용된 DQN은 인간의 게임 플레이 데이터를 학습한 것이 아니라 독립적으로 사전 학습된 모델이므로, 인간이 실제로 특정 상태에서 어떻게 학습하고 반응하는지를 정량적으로 분석하기에는 제한적일 수 있다. 즉, DQN이 학습한 상태 표현과 인간이 환경에서 학습하는 방식이 완전히 동일하다고 단정할 수 없으며, 이를 명확하게 규명하기 위해서는 인간이 플레이한 데이터를 직접 활용하여 강화학습 모델을 학습하는 추가적인 연구가 필요하다. 둘째, 본 연구는 Atari 환경이라는 제한적인 맥락에서 진행되었기 때문에, 보다 복잡한 환경에서 동일한 결과가 재현될 수 있는지는 명확하지 않다. 실제 세계에서 인간이 의사결정을 내리는 방식은 다양한 인지적 요소(예: 감정, 사회적 맥락 등)가 개입될 수 있으며, 본 연구의 결과가 보다 현실적인 환경에서도 유지되는지 검증할 필요가 있다. 마지막으로, DQN의 내부 표현과 인간 신경 활동 간의 관계가 상관분석에 기반하고 있다는 점에서, 인과적인 기제를 직접적으로 입증하는 데에는 한계가 있다. 신경 조작(neuromodulation) 기법을 활용하여 강화학습 모델과 인간 뇌의 상태-공간 표현 사이의 직접적인 인과 관계를 확인하는 후속 연구가 요구된다.
이러한 한계점에도 불구하고, 본 연구는 강화학습이 인간의 신경 기제와 구조적으로 유사할 수 있음을 실험적으로 검증했다는 점에서 중요한 의미를 갖는다. 특히, 본 연구는 DQN의 내부 표현과 인간 뇌의 신경 활동 간의 대응 관계를 체계적으로 분석함으로써, 향후 인공지능을 활용한 신경과학 연구 및 신경과학적 지식을 활용한 인공지능 모델 개선에 기여할 수 있는 중요한 토대를 마련했다.