
Adversarial vulnerabilities of human decision-making
이 연구는 인간 의사결정이 적대적 공격(adversarial attacks)에 대해 취약할 수 있음을 실험적으로 입증하고, 이를 설명하는 이론적 모델을 제시하고 있다. 기존의 연구들은 주로 딥러닝 모델이 적대적 공격에 취약하다는 점을 강조했으나, 이 논문은 인간의 의사결정 과정도 특정한 방식으로 조작될 수 있음을 보이고 있다. 이 논문에서는 실험을 통해 인간이 최적의 선택을 할 수 없는 상황을 인위적으로 설계할 수 있음을 입증하고 있으며 이는 특정한 환경에서 인간이 예측 가능한 방식으로 실수를 유도할 수 있다는 것을 의미한다. 또한, 일반적으로 인공지능 시스템의 취약점 분석에 사용되던 적대적 공격 개념을 인간의 의사결정 과정에도 적용할 수 있음을 제안한다. 마지막으로, 인간의 의사결정 취약성을 설명하기 위해 강화학습 모델을 활용하며, 이러한 취약성이 신경과학적·행동과학적 기초를 가질 수 있음을 시사한다. 이 연구는 단순한 행동 경제학적 실험을 넘어, 인공지능과 인간 의사결정의 공통된 취약점을 밝혀내고 이를 정량적으로 분석하는 데 기여한다는 점에서 중요한 의미를 가지고 있다.
Abstract
일반적으로 적대적 예제는 인공지능의 인식 시스템을 혼란스럽게 하기 위해 설계된 입력 패턴을 의미하지만, 본 연구에서는 이러한 개념을 인간의 학습 및 선택 과정에 적용하여 인간 의사결정의 적대적 취약성(adversarial vulnerabilities)을 분석한다. 연구진은 RNN 기반의 선택 모델을 바탕으로, 특정한 의사결정 과제에서 개인의 선택을 원하는 방향으로 유도할 수 있는 적대적 전략을 생성하는 프레임워크를 제안하였다. 이러한 프레임워크의 효과를 검증하기 위해 연구진은 세 가지 실험을 수행하였다.
- 행동 선택(action selection) 실험에서는 특정한 행동을 유도하는(인간이 특정한 선택을 하도록 조작할 수 있는) 적대적 패턴이 존재할 수 있음을 입증하였다.
- 반응 억제(response inhibition) 실험에서는 인간이 특정한 상황에서 적절한 억제 반응을 하지 못하도록(특정한 환경에서 인간의 충동적 반응을 유도하거나 방해할 수 있는지) 유도할 수 있음을 보였다.
- 사회적 의사결정(social decision-making) 실험에서는 특정한 사회적 맥락에서 인간의 선택을 변화시킬 수 있는 전략이 있음을 확인하였다.
또한, 연구진은 적대적 공격이 사용하는 전략을 분석하여 인간의 의사결정 과정에서 발생하는 취약성의 근본적인 원인을 파악하고자 하였다. 이러한 연구는 행동과학(behavioral sciences) 전반에 걸쳐 비합리적이거나 오류가 있는 선택을 감지하고 방지하는 데 활용될 가능성이 있다.
이 연구는 인간의 의사결정을 조작하려는 다양한 집단—광고업자, 사기꾼, 정치인, 그리고 각종 범죄자들—이 오랫동안 사용해 온 전략을 이해하고 분석하는 데 초점을 맞춘다. 이러한 조작이 효과적으로 이루어지려면, 인간의 선택 과정이 어떤 방식으로 작동하는지 정확하게 예측할 수 있는 모델이 필요하다. 따라서 인간의 의사결정 모델을 평가하는 데 있어서, 이들이 다양한 환경에서 얼마나 잘 일반화될 수 있는지를 분석하는 것은 매우 중요한 문제다. 연구진은 RNN 기반 모델이 인간 의사결정을 효과적으로 설명할 수 있음을 보여주었으나, 이 모델이 기존의 일반적인 입력 범위를 넘어선 경우에도 잘 작동하는지, 그리고 이를 통해 인간 의사결정의 취약성을 이해할 수 있는지에 대해서는 아직 명확하지 않다. 이를 해결하기 위해 연구진은 1) 의사결정 모델의 취약성을 찾고, 2) 그러한 취약성이 실제 인간의 선택 과정에서도 동일하게 나타나는지 증명하는 체계적인 방법이 필요하다고 주장하며, 이를 위한 일반적인 분석 프레임워크를 제안한다. 이 연구에서 제안된 프레임워크는 딥러닝 기반 강화학습(Deep Reinforcement Learning, RL)과 순환 신경망(RNN)을 결합한 적대적 기법(adversarial approach)을 활용한다. 먼저 RNN이 인간의 선택 행동을 모방하도록 학습한 후, 딥러닝 기반 RL 에이전트를 적대적 공격자(adversary)로 훈련시켜, 이 RNN이 인간과 유사한 방식으로 의사결정을 내리는 상황에서 특정한 선택을 유도하는 전략을 학습하도록 한다.
흥미로운 점은, 이 연구에서 개발한 적대적 기법이 반드시 악의적인 목적에만 사용될 필요는 없다는 것이다. 연구진은 동일한 프레임워크를 협력적인 목적(cooperative ends)이나 사회적 복지를 증진하는 방향(social welfare)으로도 적용할 수 있음을 강조했다. 이를 입증하기 위해, 연구진은 사회적 교환 게임에서 “공정한 결과를 유도하는 적대적 에이전트”를 설계하여 실험을 진행했다. 즉, 특정한 방식으로 인간의 선택을 유도하되, 불공정한 결과가 아니라 공정한 결과를 도출하는 방향으로 개입할 수도 있음을 보여주었다.
Adversarial framework
연구의 실험 과정은 다음과 같은 방식으로 이루어진다:
- 실험 참가자(피험자)는 특정한 선택 과제에 참여하며, 각 시행(trial)에서 현재 상태(observation)를 입력으로 받고, 이에 대한 행동(action)을 결정한다.
- 피험자가 선택한 행동에 따라, 보상(learner reward)이 주어지고 다음 상태가 제공된다.
- 이 과정은 반복되며, 피험자의 행동 패턴이 특정한 목표 방향으로 유도될 수 있는지 분석한다.
일반적인 nonadversarial 환경에서는, 이러한 보상과 상태 변화가 MDP 또는 POMDP을 따르며, 특정한 확률에 기반해 보상이 주어진다. 즉, 실험 참여자는 기존의 강화학습 환경처럼 일정한 확률적 규칙에 따라 보상을 받고 선택을 학습하는 것이다. 그러나 본 연구에서는 적대적 모델(adversary model)이 개입하여, 피험자가 받는 보상과 다음 상태를 조작할 수 있도록 설계되었다. 즉, 피험자의 행동을 특정한 방향으로 유도하기 위한 조작이 가능하도록 설계된 환경이다.
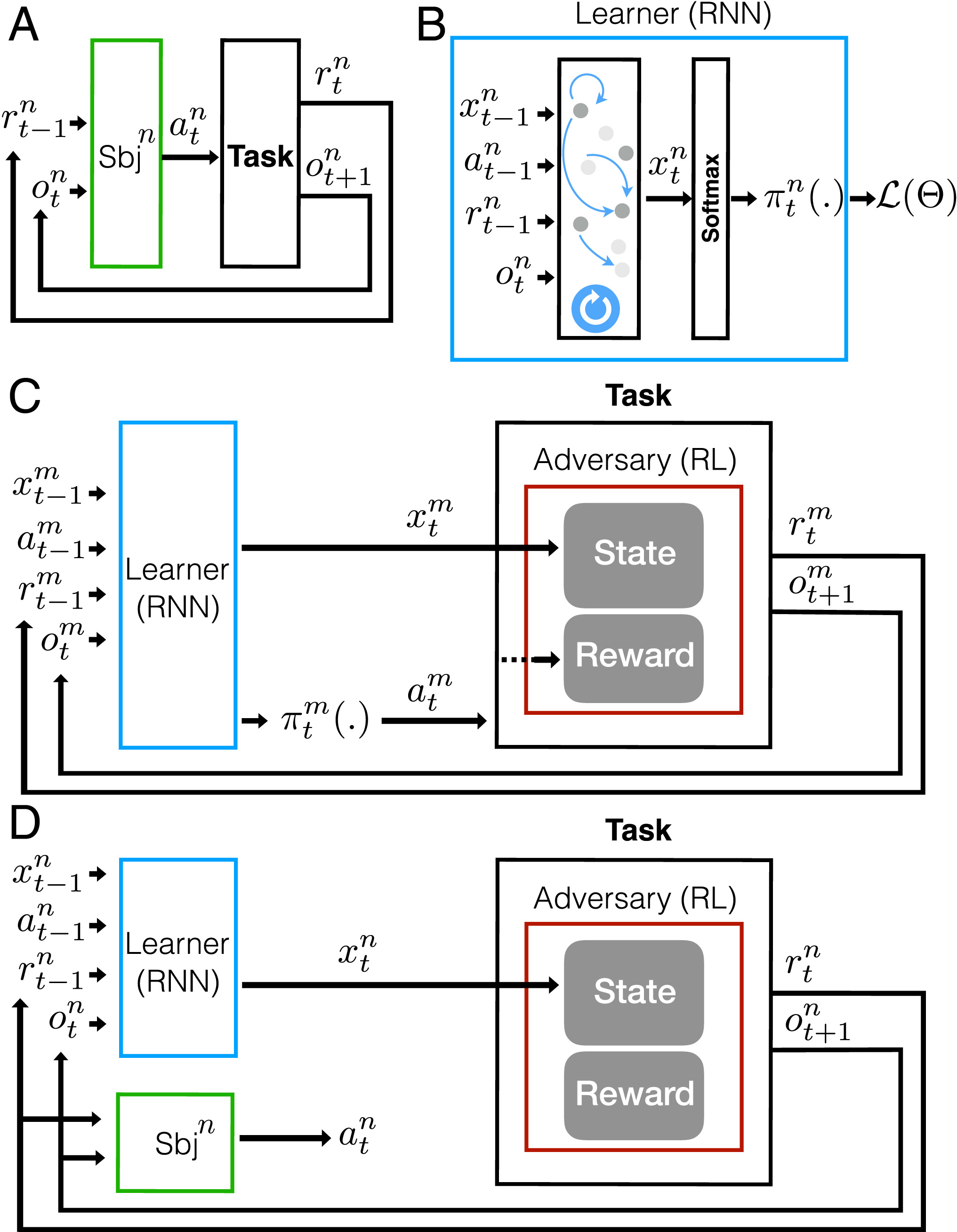
적대적 모델의 역할과 제약 조건
적대적 모델(Adversarial model)은 피험자가 받는 보상과 관측 상태를 결정하는 역할을 한다. 다만, 완전히 자유롭게 보상을 줄 수 있는 것이 아니라, 일정한 예산 제한(budget constraints) 내에서 작동해야 한다. 즉, 피험자가 특정 행동을 하도록 강제로 보상을 몰아주는 것이 아니라, 전략적으로 조작된 보상을 통해 피험자의 행동을 장기적으로 변화시키는 방식으로 설계되었다. 이 모델의 목표는 피험자가 특정한 행동을 더 선호하게 만들거나, 특정한 게임 상황에서 적대적 모델이 최대한의 이익을 얻도록 유도하는 것이다.
적대적 모델의 학습 과정
이 연구에서는 적대적 모델을 강화학습(RL) 기반의 인공지능 에이전트로 설계하였다. 적대적 에이전트는 피험자의 학습 이력(learning history)을 입력으로 받아, 다음 시행(trial)에서 피험자가 받을 보상과 관측 상태를 결정하는 역할을 한다. 강화학습(RL) 관점에서 보면, 적대적 모델의 상태(state)는 피험자의 학습 이력이며, 적대적 모델의 행동(action)은 피험자가 받는 보상과 관측 상태를 설정하는 것으로 정의된다. 적대적 모델은 피험자가 목표 행동(target behavior)이나 목표 전략(target strategy)을 따르게 만들었을 때 더 높은 보상을 받도록 학습된다. 이를 적대적 보상(adversarial reward)이라고 하며, 적대적 모델은 실험이 진행되는 동안 장기적인 총 적대적 보상을 극대화하는 방향으로 학습된다.
적대적 모델의 학습을 위한 RNN 기반 인간 모델
적대적 모델을 학습하는 과정에서 직접 인간과 상호작용하는 것은 비효율적이고 현실적으로 어려운 접근법이다. 실제 인간과의 인터랙션을 통한 학습은 많은 시간이 걸릴 뿐만 아니라, 학습을 위해 방대한 데이터가 필요하기 때문에 실제 실험 참가자만을 대상으로 적대적 모델을 학습하는 것은 현실적으로 불가능하다. 이를 해결하기 위해, 연구진은 최근 개발된 순환 신경망(RNN) 기반 인간 선택 모델을 활용하였다. 먼저, 인간이 비적대적 환경에서 수행한 데이터를 사용하여, RNN 기반의 인간 선택 모델(learner model)을 학습시킨다. 이후, 적대적 모델(adversary)은 이 RNN 모델을 사용하여 학습한다. 즉, 적대적 모델이 직접 인간과 상호작용하는 것이 아니라, 인간의 행동을 예측할 수 있는 RNN을 상대로 학습함으로써, 인간을 대상으로 한 실험 없이도 최적의 적대적 전략을 찾을 수 있도록 설계되었다.
이러한 접근 방식은 다음과 같은 추가적인 장점을 가진다:
- 기존에 축적된 데이터(nonadversarial 학습 데이터)를 활용할 수 있기 때문에, 새로운 실험 데이터를 생성하지 않고도 적대적 모델을 학습할 수 있다.
- 인간을 직접 학습 대상으로 삼지 않기 때문에, 비용과 시간 측면에서 훨씬 효율적인 방식이다.
- 적절한 모델링만 가능하다면, 다양한 적대적 훈련 시나리오를 시뮬레이션할 수 있으며, 이를 통해 인간의 의사결정 취약성을 보다 깊이 분석할 수 있다.
Learner model
학습자 모델은 순환 신경망(RNN)과 소프트맥스(softmax) 층으로 구성되며, 이를 통해 인간의 행동 패턴을 모방한다. RNN 내부 상태(internal state)는 과거 행동 및 보상 데이터를 반영하며, 이를 기반으로 다음 행동을 예측한다. 또한 각 시행(trial) t 에서, 피험자 n의 RNN 내부 상태는 벡터 \(x_{t-1}^n\) 로 표현되며, 이는 이전 시행까지의 입력을 반영한다. 내부 상태는 다음과 같은 요소를 바탕으로 반복적으로 업데이트된다:
- 이전 행동 \(a_{t-1}^n\)
- 이전 보상 \(r_{t-1}^n\)
- 현재 관측값 \(o_t^n\) (예: 화면에 표시되는 시각적 단서)
업데이트된 내부 상태 \(x_t^n\)은 소프트맥스 층으로 전달되며, 이를 통해 다음 행동 \(pi_t(cdot)\)을 예측하며, 모델이 예측한 행동과 피험자가 실제로 수행한 행동 \(a_t^n\)을 비교하여 **손실 함수 \(*L(Theta)*\) 를 계산하며, 이를 기반으로 학습자 모델이 훈련된다.
Adversary
적대적 학습자는 강화학습(RL) 기반의 에이전트(agent)로 설계되었으며, 피험자가 받는 보상(learner reward)과 관측값(observation)을 조작하여 목표 행동을 유도하는 것이 목표이다. 적대적 모델은 단순히 개별 시행의 행동을 조작하는 것이 아니라, 연속된 시행(trial) 동안 피험자의 행동을 특정한 패턴으로 유도하는 전략을 학습한다. 순차적 의사결정 문제(sequential decision-making problem)로 모델링되며, 이는 강화학습(RL)으로 해결된다.
- 적대적 모델의 상태(state)
- 학습자의 내부 상태 \(x_t^m\) (시뮬레이션된 학습자 \(m\)에 대한 정보)
- 적대적 모델은 이 내부 상태를 기반으로 다음 시행에서 피험자가 받을 보상과 관측값을 결정한다.
- 적대적 모델의 행동(action)
- 적대적 모델은 두 가지를 선택한다:
- 학습자에게 제공할 보상 \(r_t^m\)
- 다음 시행에서 피험자가 받을 관측값 \(o_{t+1}^m\)
- 적대적 모델은 두 가지를 선택한다:
- 적대적 모델의 보상(reward)
- 적대적 보상(adversarial reward)은 피험자가 목표 행동(target behavior)이나 목표 전략(target strategy)을 따르게 만들었을 때 부여된다.
- 적대적 모델의 목표는 장기적인 총 적대적 보상(sum of adversarial rewards)을 최대화하는 것이다.
적대적 모델은 강화학습 알고리즘으로 Advantage Actor-Critic (A2C)과 Deep Q-Network (DQN)을 사용하여 학습을 진행하였다. 중요한 점은, 적대적 모델을 훈련할 때 학습자 모델은 학습되지 않으며, 기존에 학습된 상태로 유지된다. 즉, 학습자 모델의 가중치는 고정(frozen)된 상태에서, 적대적 모델만 최적의 전략을 찾도록 학습된다.
적대적 모델의 2가지 학습 방식
1) 폐루프(Closed-loop) 적대적 모델
피험자의 과거 행동을 기반으로 보상과 관측값을 결정하는 방식이다. 적대적 모델은 피험자의 학습 이력을 반영하는 학습자 모델의 내부 상태 \(x_t^n\)을 입력으로 받아, 피험자의 행동 패턴을 실시간으로 조작할 수 있다. 피험자의 실제 학습 과정과 밀접하게 연결되므로, 보다 정밀한 조작이 가능하다는 장점이 있다.
2) 개루프(Open-loop) 적대적 모델
피험자의 과거 행동을 반영하지 않고, 단순히 사전에 정의된 정책에 따라 보상과 관측값을 설정하는 방식이다. 개루프 적대적 모델은 학습자 모델의 내부 상태를 입력으로 받지 않으며, 피험자의 행동과 관계없이 독립적으로 작동한다. 단순한 실험 세팅에서 신속하게 적용할 수 있으며, 학습자의 데이터를 실시간으로 분석하지 않아도 된다.
적대적 모델을 이용한 인간 실험
Fig. 1D는 훈련된 적대적 모델과 학습자 모델이 실제 인간 실험에서 어떻게 활용되는지를 보여준다. 실험에서, 학습자 모델은 피험자의 행동을 직접 선택하지 않지만, 피험자의 행동을 입력으로 받아 학습 이력을 추적한다.
- 피험자가 시행 \(t\)에서 행동 \(a_t^n\)을 선택한다.
- 학습자 모델은 피험자의 행동을 입력으로 받아 내부 상태 \(x_t^n\)을 업데이트한다.
- 적대적 모델은 학습자 모델의 내부 상태를 받아 보상 \(r_t^n\)과 다음 관측값 \(o_{t+1}^n\)을 결정한다.
- 피험자는 새로운 보상과 관측값을 바탕으로 다음 시행에서 행동을 선택한다.
- 이 과정이 반복되며, 적대적 모델은 피험자의 행동을 특정한 방향으로 유도한다.
Result of bandit task
이 실험은 기존 연구(ref. 1)에서 제안된 적대적(adversarial) bandit task를 기반으로 한다.
실험에서 피험자는 화면 좌측과 우측에 위치한 두 개의 정사각형 중 하나를 선택한다. 피험자가 선택한 후, 선택 결과에 따라 스마일리(face) 또는 슬픈 얼굴(sad face) 피드백을 받으며, 이 피드백은 피험자의 행동에 대한 학습자 보상(learner reward)을 의미한다. 적대적 모델(adversary)은 사전에 두 개의 선택지 중 하나에 학습자 보상을 배정하며, 피험자가 특정 행동을 선호하도록 유도하는 것이 목표이다.
적대적 모델의 목표 및 제약 조건
- 적대적 모델은 피험자가 특정 행동(타겟 행동, target action)을 비타겟 행동(nontarget action)보다 더 많이 선택하도록 유도해야 한다. 예를 들어, 실험이 시작되기 전에 왼쪽 선택지가 타겟 행동으로 설정될 수 있다.
- 하지만 제약 조건이 존재한다: 각 선택지에는 사전적으로 총 25회의 학습자 보상이 배정되어야 하기 때문에 적대적 모델이 특정 행동만 선택하도록 무제한적으로 보상을 몰아줄 수 없으며, 제한된 보상을 전략적으로 분배해야 한다.
Q-learning model
이 연구에서는 실험 프레임워크를 평가하기 위해 Q-러닝(Q-learning) 알고리즘을 활용한 시뮬레이션을 수행하였다. 먼저, Q-learning 알고리즘을 사용하는 1,000명의 가상의 학습자(learners)를 생성하였다. Q-learning 학습자의 학습 매개변수는 기존 연구에서 사용된 것과 동일하게 설정되었다. 이후 Q-learning 데이터로부터 학습자 모델(learner model)을 훈련하였다. 이후, 강화학습(RL)을 활용하여 적대적 모델(adversary)을 학습자 모델을 활용하여 학습시켰다.
적대적 모델은 학습자 모델이 타겟 행동(target action)을 선택할 때마다 보상을 획득하도록 설계되었다. 실험 수준(task level)에서, 적대적 모델은 각 행동에 대해 최대 25회의 보상만 할당할 수 있다. 즉, 적대적 모델이 25번의 보상을 모두 할당하면, 더 이상 추가적인 보상을 줄 수 없다. 반대로, 총 25-k번만 보상을 할당했다면, 남은 k회의 시행에서 반드시 해당 행동에 보상이 배정되도록 설정되었다. 이 제약은 피험자의 행동을 특정한 방향으로 조작하면서도, 지나친 보상 몰아주기를 방지하기 위한 것이다.
Result of bandit task
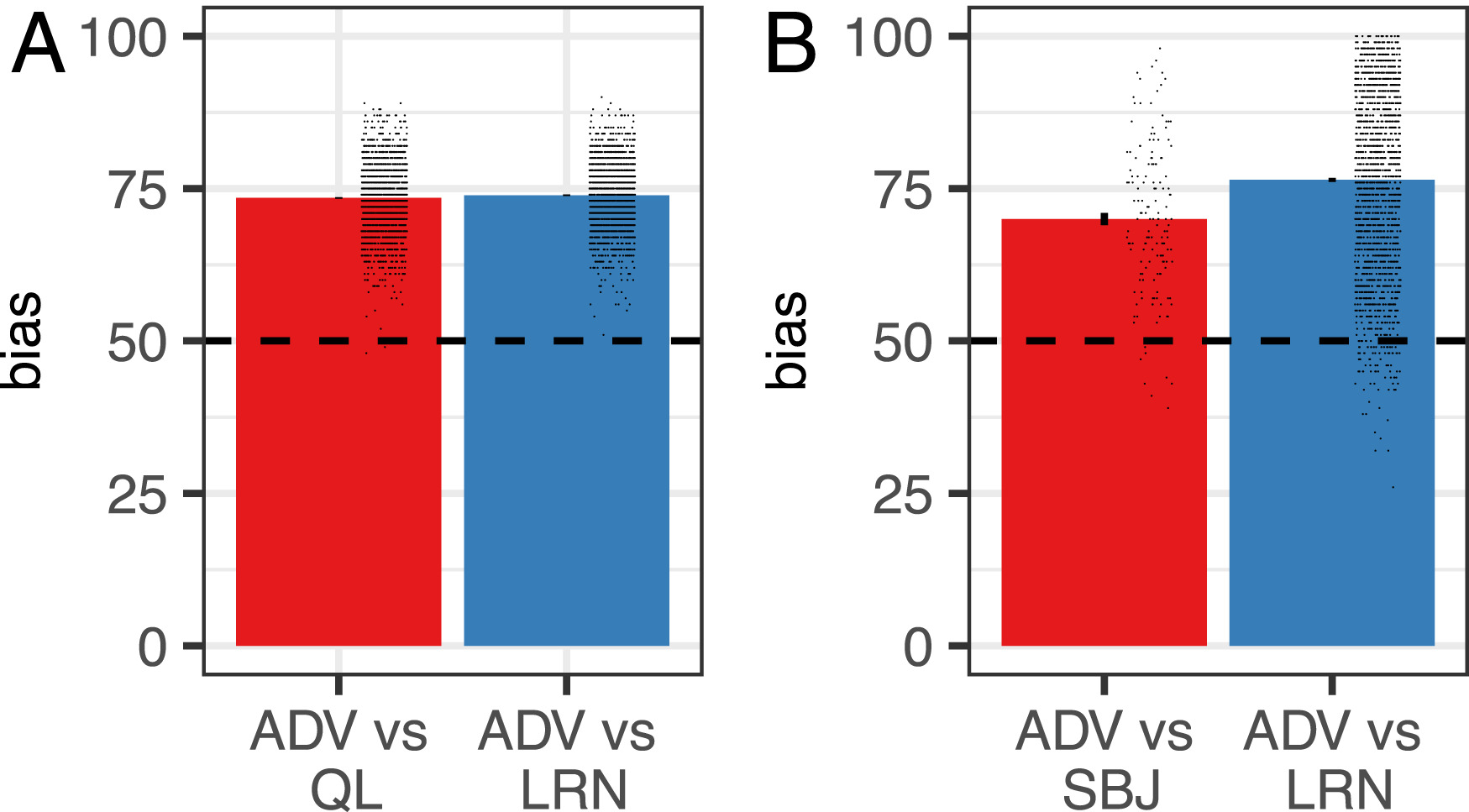
훈련된 적대적 모델을 학습자 모델(learner model)과 Q-learning 모델을 대상으로 평가하였다. 주요 종속 변수(dependent variable)는 “편향(bias)”으로, 이는 학습자/모델로부터 타겟 행동이 선택된 시행의 비율(%)을 의미한다. Q-Learning 모델을 대상으로 했을 대의 평균 편향은 73.4%으로 적대적 모델은 학습자의 선택을 타겟 행동으로 유도하는 데 성공했다. 이는 기존 연구(ref. 1)에서 얻어진 결과와 유사하지만, 본 연구에서는 Q-learning 알고리즘을 사전에 알지 못한 상태에서도 동일한 결과를 도출했다는 점에서 차별점이 있다. 학습자 모델(learner model)을 상대로 했을 때의 평균 편향은 73.8%으로, 적대적 모델은 Q-learning 모델과 학습자 모델을 상대로 유사한 수준의 편향을 유도하는 데 성공하였다. 각각의 점은 한 번의 시뮬레이션을 의미한다.
피험자가 적대적 모델과 대결할 때 타겟 행동을 선택한 평균 비율(bias)은 70%였다. 이는 완전히 무작위 선택(50%)과 비교했을 때 유의미하게 높은 수준이며, 적대적 모델이 인간 피험자를 타겟 행동으로 유도하는 데 성공하였음을 의미한다. 적대적 모델이 사람의 데이터로 학습된 학습자 모델과 대결했을 때, 타겟 행동 선택 비율이 76.4%로 나타났으며, 인간 피험자와의 실험(70%)보다 더 높은 수치를 기록하였다. 이는 적대적 모델이 인간보다 학습자 모델을 더 쉽게 조작할 수 있음을 의미한다.
Strategy analysis of adversary against learner model (figure 3A 참고)
적대적 모델은 다음과 같은 전략적인 보상 할당 방법을 사용하여 학습자 모델의 선택을 조작하였다.
-
초반 (First Half of the Task) 초반에는 타겟 행동에 대해 소량의 학습자 보상만 할당하였다. 그러나, 비타겟 행동에는 학습자 보상을 전혀 제공하지 않음으로써, 학습자 모델이 타겟 행동을 계속 선택하도록 유도하였다. 결과적으로, 학습자 모델이 타겟 행동을 선택할 확률이 70~80% 범위에서 유지되었다.
-
후반 (Toward the End of the Task) 후반부에서는 비타겟 행동에 대한 학습자 보상(nontarget learner rewards)을 집중적으로 사용(“burn”)하였다. 그러나, 동시에 타겟 행동에 대한 학습자 보상의 밀도를 증가시켜, 비타겟 보상의 효과를 상쇄하는 방식을 사용하였다. 이러한 균형 조정 전략을 통해, 학습자 모델이 지속적으로 타겟 행동을 선택하도록 유도하였다.
-
최종 결과 적대적 모델은 이러한 보상 분배 전략을 활용하여, 학습자 모델이 전체 시행(trials)의 약 73%에서 타겟 행동을 선택하도록 유도하는 데 성공하였다. 적대적 모델은 단순히 많은 보상을 제공하는 것이 아니라, 전략적으로 보상을 분배하여 학습자 모델의 행동을 조작하였다. 특히, 초반에는 소량의 타겟 보상을 제공하면서 비타겟 보상을 억제하는 방식을 사용하였으며, 후반부에는 비타겟 보상을 소진하면서 동시에 타겟 보상을 증폭시키는 전략을 사용하여 최종적으로 타겟 행동을 선택하는 비율을 높였다. 이러한 결과는 인간의 의사결정도 특정한 보상 분배 전략에 의해 쉽게 조작될 수 있음을 시사한다.
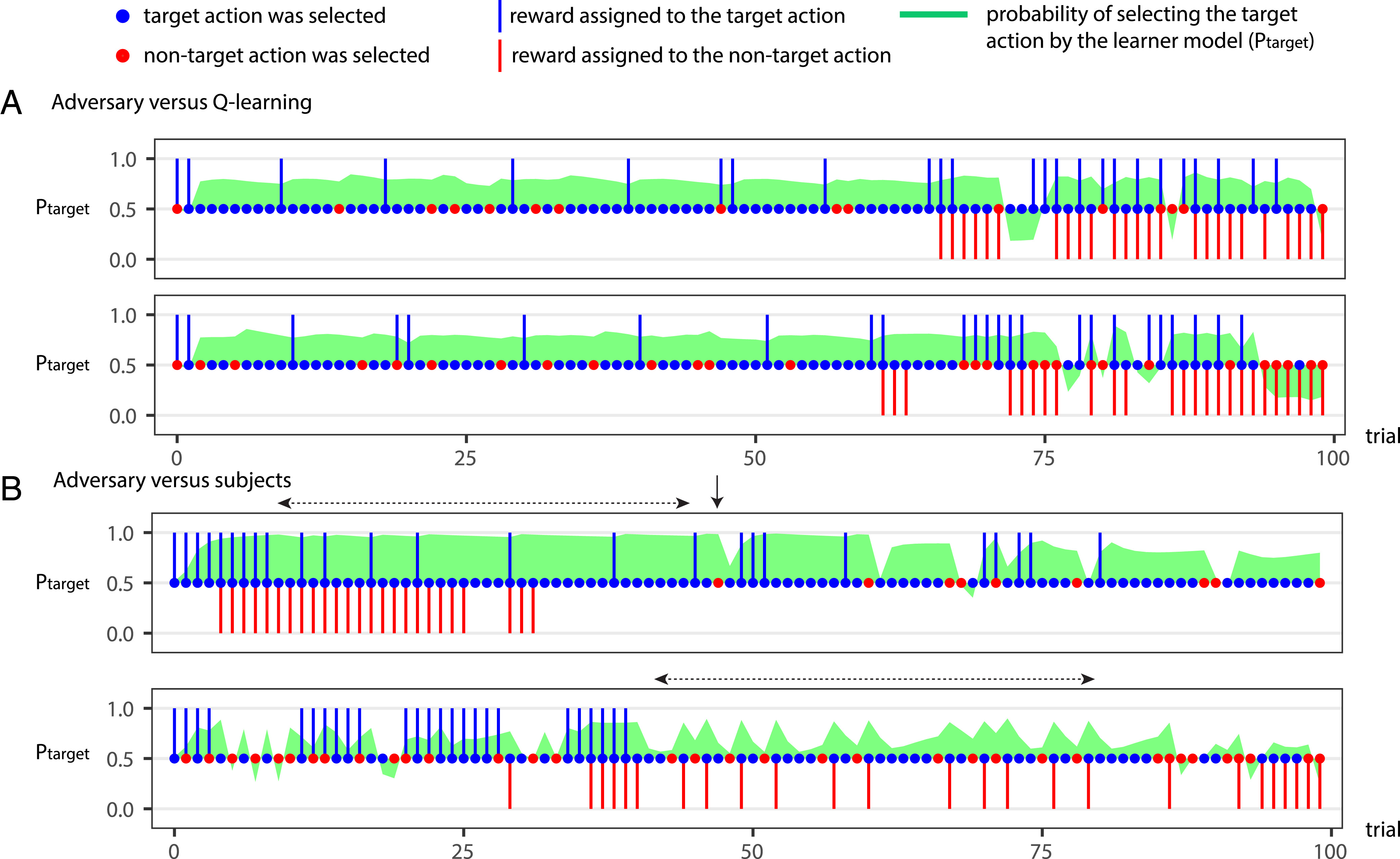
Strategy analysis of adversary against human subject (figure 3B 참고)
연구진은 앞서 개발한 적대적 프레임워크(adversarial framework)를 인간의 의사결정 과정에 적용하여 적대적 모델(adversary)이 실제 인간의 선택을 조작할 수 있는지 검증하였다.
적대적 모델은 비타겟 행동의 학습자 보상을 피험자가 경험하지 못하도록 설계하는 동시에, 타겟 행동에 대한 보상은 피험자가 명확히 인식하도록 조작하였다. 타겟 행동을 선택할 확률에 기반하여 타겟 행동이 선택될 가능성이 높은 경우, 해당 행동에 보상을 제공하였다. 반면, 비타겟 행동에 대해서는 해당 행동이 선택될 가능성이 낮은 시점에서 보상을 할당하여 피험자가 이를 경험할 확률을 줄였다. 이하로 적대적 모델의 전략은 4가지 정도로 정리할 수 있다.
초반 연속 보상(Initial Serial Learner Reward Delivery)
적대적 모델은 초반에 연속적으로 타겟 행동에 대한 보상을 배정하였다. 피험자가 타겟 행동을 선택하는 패턴이 자리 잡으면, 이후 비타겟 행동에 보상을 할당하여 이를 “소진(burn)”하였다. 즉, 비타겟 보상을 사용하되 피험자가 이를 인식하지 못하도록 함으로써, 타겟 행동 선호도를 유지하였다.
부분 강화(Partial Reinforcement) 전략
초기 보상 제공 이후, 타겟 행동에 대한 보상을 부분적으로 할당하여 보상을 절약하였다. 이는 강화학습에서의 부분 강화 효과(partial reinforcement effect)를 활용한 것으로, 타겟 행동 선택 확률을 크게 감소시키지 않으면서도 적은 보상으로 피험자의 행동을 유지하는 방식이다.
비타겟 행동 선택 시 보상 증가(Tactical Reinforcement After Nontarget Choice)
피험자가 실수로 비타겟 행동을 선택하면, 즉시 타겟 행동 보상의 빈도를 증가시켜 피험자가 다시 타겟 행동을 선택하도록 유도하였다. 이는 타겟 행동으로의 빠른 복귀를 촉진하는 전술로 작용하였다.
비타겟 보상 은닉(Hiding Nontarget Rewards)
일부 피험자는 교대로 행동을 선택하는 경향(alternation tendency)을 보였다. 적대적 모델은 이러한 패턴을 탐지하여, 비타겟 행동을 선택한 직후 보상을 제공하는 전략을 사용하였다. 이 전략을 통해 피험자가 비타겟 보상을 명확히 인식하지 못하도록 유도하였다.
연구진은 적대적 모델이 인간과 Q-learning 학습자 모델을 상대로 다르게 작동함을 실험적으로 검증하였다. 적대적 모델을 인간 피험자에 맞춰 최적화한 후, 이를 Q-learning 모델에 적용했을 때 타겟 행동 선택 비율이 55.2%로 감소하였다. 반대로, Q-learning 학습자를 대상으로 훈련된 적대적 모델을 인간에게 적용했을 때 타겟 행동 선택 비율이 58.1%로 나타났다. 이는 적대적 모델이 인간과 강화학습 모델을 각각 다른 방식으로 조작해야 효과적으로 작동한다는 점을 시사한다.
Go/No-Go Task
Go/No-Go Task는 실험 참가자가 일반적인 자극(Go stimulus)에는 반응(스페이스 바 누르기)하지만, 특정한 희귀 자극(No-Go stimulus)에는 반응을 억제해야 하는(아무 동작을 하지 말아야 하는) 과제이다. 연구진은 기존 연구(ref. 8)의 방식을 따르되, 적대적 모델(adversary)이 No-Go 자극의 배치를 조작하여 참가자가 더 많은 오류를 범하도록 유도할 수 있는지 검증하였다.
각 참가자는 총 350회의 시행(trial)을 수행한다. Go 자극(예: 주황색 원)은 90% 빈도로 등장하며, 참가자는 스페이스 바를 눌러야 한다. No-Go 자극(예: 파란색 삼각형)은 10% 빈도로 등장하며, 참가자는 반응을 억제해야 한다.
비적대적(nonadversarial) 환경에서, No-Go 자극은 균등하게 분포(랜덤 배치)되며, 참가자의 반응 패턴을 조작하지 않는다. 반대로 적대적(adversarial) 환경에서는 적대적 모델이 No-Go 자극의 배치를 전략적으로 조정하여 참가자가 더 많은 실수를 하도록 유도하나 No-Go 자극의 총 개수(10%)는 고정된 상태로 유지해야 한다.
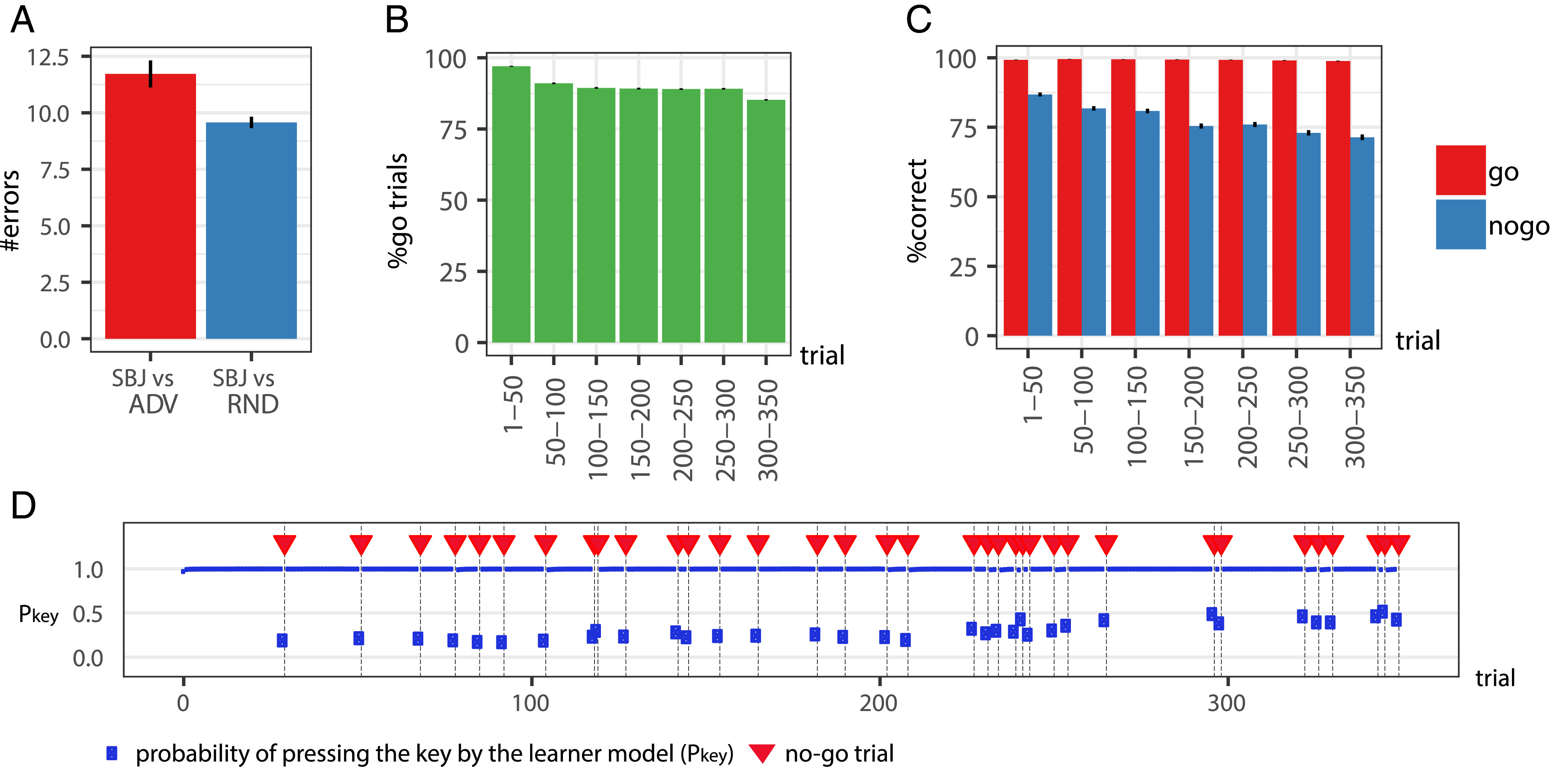
Bandit Task와의 차이점은 Bandit Task에서는 적대적 모델이 보상(learner reward)을 조작하여 피험자의 행동을 유도하였지만 Go/No-Go Task에서는 적대적 모델이 No-Go 자극의 배치를 조정하여 피험자의 실수를 유도한다는 점이다. 또한 Bandit Task에서는 적대적 모델이 피험자의 상태를 실시간으로 반영하여 조작할 수 있었지만 이번 실험에서는 적대적 모델이 피험자의 상태를 알지 못하는 상태의 open loop 방식으로 설계되었다. 즉 피험자가 이전 시행에서 어떤 반응을 했는지 모르는 상태에서 일반적인 행동 패턴을 기반으로 No-GO 자극의 배치를 최적화하는 전략을 학습한다.
먼저 무작위(No-Go 자극이 랜덤하게 배치된 조건)에서 수집된 피험자 데이터(N=770, Amazon Mechanical Turk 모집)를 학습하여 학습자 모델(learner model) 구축하였다. 학습자 모델은 인간 피험자가 일반적인 환경에서 어떻게 반응하는지를 학습하였다. 이후 학습자 모델을 이용하여 적대적 모델이 No-Go 자극 배치를 최적화하는 전략을 학습하였다. Bandit Task와 달리, 피험자의 실시간 상태 정보를 받지 않는 Open-loop 방식으로 작동한다. 마지막으로 훈련된 적대적 모델을 사용하여 새로운 피험자(N=139, Amazon Mechanical Turk 모집) 대상으로 실험 진행하였다.
figure 4A의 결과를 보면 적대적 모델이 피험자의 실수를 유도하는 데 성공한 것을 볼 수 있다. 적대적 모델 환경에서 피험자는 평균 11.7개의 오류를 범했으며 이는 No-Go 자극이 랜덤하게 분포한 환경과 통계적으로 유의미한 차이임을 확인하였다. 즉, 적대적 모델이 No-Go 자극을 전략적으로 배치함으로써 피험자의 실수를 유의미하게 증가시킬 수 있음을 입증하였다.
Fig. 4B, 4C를 보면 적대적 모델은 No-Go 자극을 실험 후반부에 더 많이 배치하는 경향을 보임 (Fig. 4B). 이는 기존 피험자 데이터(Fig. 4C)에서 실험 후반부로 갈수록 No-Go 자극에서의 오류율이 증가하는 패턴을 학습한 결과이다. 즉, 적대적 모델은 피험자가 실험 후반부에서 실수를 더 많이 한다는 사실을 학습하고, 이를 이용하여 No-Go 자극을 배치하는 방식으로 실수를 유도한 것이다. 적대적 모델이 No-Go 자극을 배치한 패턴을 보면, 실험 후반부에 집중적으로 배치되어 있는 것을 확인할 수 있는데, 실험 후반부로 갈수록 피험자의 반응 오류(공간 바 누르기 확률)가 증가하는 경향이 나타났다. 이는 적대적 모델이 No-Go 자극을 효과적으로 배치하여 피험자의 실수를 증가시킬 수 있음을 보여주었다.
Multiround Trust Task
Multiround Trust Task(MRTT)는 사회적 교환(social exchange)에서 신뢰(trust)와 협력(cooperation)의 취약성을 평가하는 실험이다. 이 실험에서 참가자(인간)는 투자자(Investor) 역할을 수행하고, 적대적 모델(Adversary)는 신뢰받는 사람(Trustee) 역할을 수행하며, 적대적 모델이 투자자의 신뢰를 조작할 수 있는지 평가한다.
실험 구조
실험은 10라운드 동안 진행되며, 두 플레이어(Investor, Trustee)가 각 라운드에서 투자 및 상환 결정을 내린다.
Investor는 매 라운드마다 20개의 화폐 단위(monetary units)를 지급받고 이 중 일부(또는 전체)를 Trustee에게 공유할 수 있으며, Trustee는 투자자가 공유한 금액을 받는다. 이 금액은 3배로 증가한 후, 일부(0%, 25%, 50%, 75%, 100%)를 투자자에게 다시 돌려줄 수 있다(Repayment). 각 플레이어의 최종 수익은 10라운드 동안 벌어들인 총합이다.
적대적 모델(Trustee)은 투자자가 특정한 방식으로 행동하도록 유도하는 전략을 학습하며, 두 가지 목표(objectives)로 학습된 두 개의 적대적 모델이 존재한다. 각각 MAX (최대 이익 목표), FAIR (공정성 목표)이다. MAX는 Trustee(적대적 모델)가 10라운드 동안 가장 많은 이익을 얻도록 유도하며 초반에는 높은 Repayment를 제공하여 투자자의 신뢰를 얻고, 후반부에는 Repayment를 줄여 투자금을 회수하는 전략을 사용한다. FAIR는 Trustee와 Investor가 최종적으로 동일한 수익을 얻도록 유도한다. 투자자가 지속적으로 신뢰를 유지하도록 하며, 적절한 수준의 Repayment를 제공하여 협력을 유지하는 전략을 사용한다.
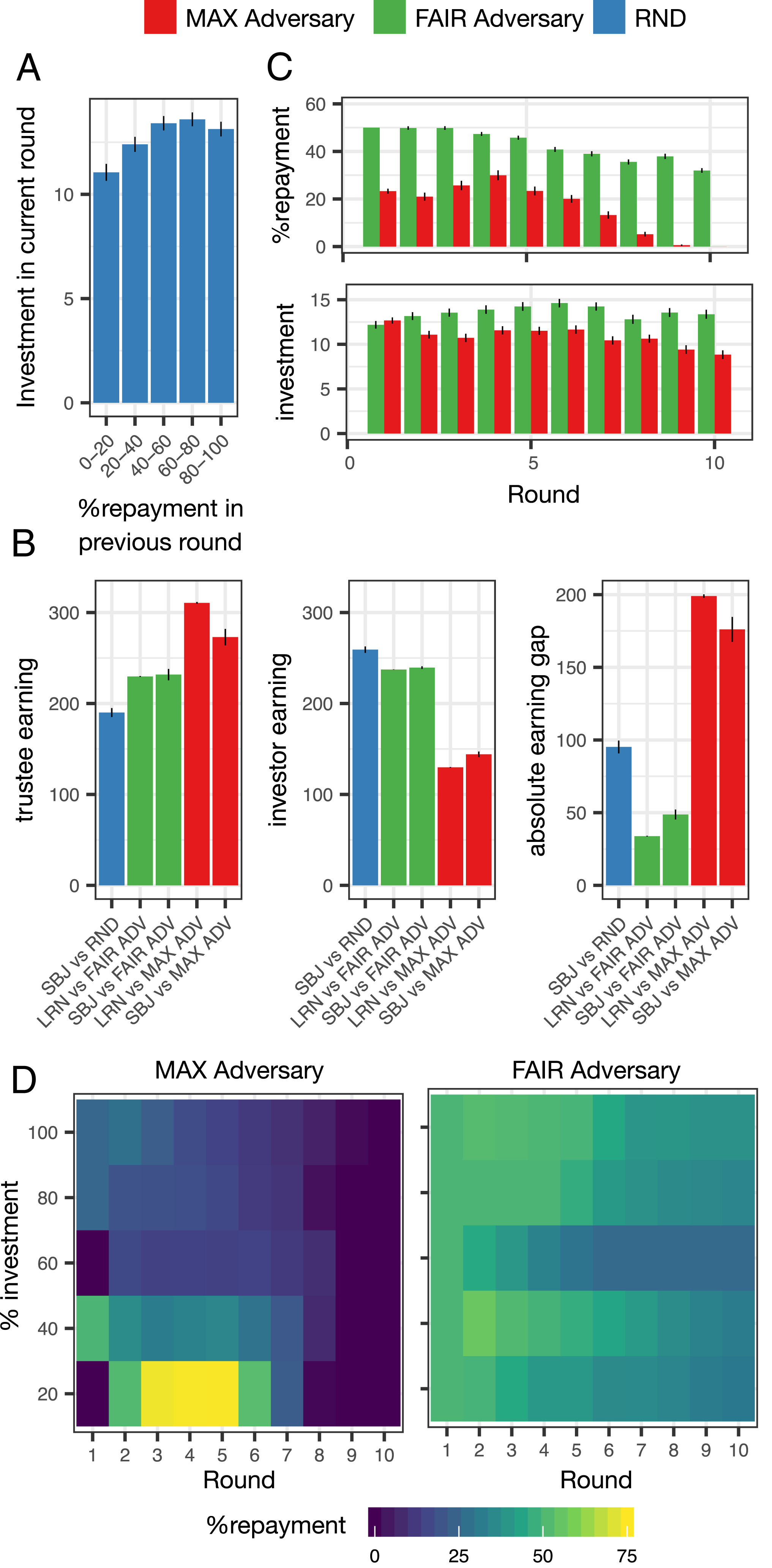
우선 Figure A를 보면 Amazon Mechanical Turk에서 모집된 무작위 투자자(RND condition, n = 232) 데이터를 분석한 결과, 이전 라운드에서 높은 Repayment를 받은 경우, 다음 라운드에서 투자 금액이 증가하는 경향이 확인되었다. 이는 Trustee가 초반에 높은 Repayment를 제공하면 투자자는 신뢰를 형성하고 더 많은 투자를 하는 경향이 있음을 시사한다. 이러한 경향을 바탕으로, MAX 목표의 적대적 모델은 초반에 신뢰를 구축한 후, 후반에는 Repayment를 줄이며 투자금을 회수하는 전략을 사용할 가능성이 높다.
B의 그림을 보면 훈련된 두 개의 적대적 모델을 인간 피험자(Subjects)와 시뮬레이션(학습자 모델)에서 평가한 결과, MAX 모델은 RND 및 FAIR 모델보다 Trustee의 총 수익이 더 높았다. 초반에는 높은 Repayment로 투자자의 신뢰를 형성하고, 후반부에는 Repayment를 줄여 수익을 극대화하는 전략이 효과적이었다. 반면, FAIR 모델은 투자자와 Trustee 간의 최종 수익 차이를 최소화하는 데 성공하였다. 이는 투자자가 지속적으로 투자하도록 유도하면서도 Trustee가 과도한 이익을 얻지 않도록 설계된 결과로 해석된다. 따라서 적대적 모델이 목표에 맞게 투자자의 행동을 조작할 수 있음이 입증되었다.
C는 라운드별 MAX와 FAIR의 repay와 그 라운드에서의 투자 금액이다. 라운드별 Repayment 및 투자 금액 변화를 살펴보면, FAIR 모델은 MAX 모델보다 더 높은 Repayment를 제공하며 투자자에게 신뢰를 유지하도록 유도했다. 투자자는 더 많은 Repayment를 받으면서 투자 금액도 점진적으로 증가하는 경향을 보였다. 즉, FAIR 모델은 투자자가 지속적인 신뢰를 유지할 수 있도록 설계된 반면, MAX 모델은 후반부에 Repayment를 급격히 줄이며, 마지막 라운드에서는 아예 Repayment를 제공하지 않는 방식을 취했다. 이는 투자자가 후반부에 신뢰를 잃게 만들고, Trustee가 최종적으로 더 많은 수익을 얻도록 유도하는 전략이다.
D는 라운드와 투자 퍼센트에 따른 각각 적대 모델의 repay 비율이다. MAX 모델의 전략을 세부적으로 살펴보면, 초반에는 투자자가 신뢰를 쌓도록 유도하기 위해 높은 Repayment(최대 75%)를 제공한다. 투자자가 지속적으로 투자하도록 신뢰를 구축한 후, 후반부에는 Repayment를 급격히 줄여 Trustee의 이익을 극대화한다. 특히 마지막 라운드에서는 Repayment를 전혀 제공하지 않음으로써 투자자의 신뢰를 이용해 최종적으로 높은 수익을 창출하는 전략을 사용한다. 투자자가 낮은 투자율(20%)을 보일 경우, 초반에 큰 Repayment를 제공하여 투자율을 증가시키도록 유도하는 방식도 활용된다.
반면, FAIR 모델의 전략은 투자자의 투자금이 중간 수준(약 50%)이면, Repayment를 약 30% 수준으로 반환하여 Trustee와 Investor 간의 수익 차이를 줄이는 방식이다. 투자가 5 미만이면, 어떠한 행동을 취하더라도 Trustee와 Investor 간의 수익 차이가 발생하기 때문에, MAX 전략과 유사하게 초반에 높은 Repayment를 제공하여 투자 신뢰를 구축한 후, 투자금에 비례하여 Repayment를 조정하는 방식을 따른다. 적대적 모델은 단순히 매 라운드마다 수익을 최적화하는 것이 아니라, 전체 10라운드 동안 투자자의 행동을 유도하는 방식으로 전략을 최적화하였다. 즉, 매 라운드마다 일정한 Repayment를 제공하는 것이 아니라, 장기적인 목표에 맞춰 Repayment를 조정하며 투자자의 신뢰를 조작하는 방식을 취했다.
Discussion
이번 연구에서는 인간 의사결정 과정에서 특정한 행동을 유도하는 적대적 모델(adversarial model)을 생성하는 일반적인 프레임워크를 제시하였다. 세 가지 실험을 통해 적대적 모델이 목표 행동을 성공적으로 유도할 수 있으며, 해당 모델이 시뮬레이션을 통해 해석 가능함을 입증하였다. 또한, 이 프레임워크가 적대적인 환경뿐만 아니라 공정성을 유도하는 게임과 같은 비적대적인 환경(nonadversarial settings)에서도 적용될 수 있음을 보여주었다.
인지적 편향(Cognitive Biases)과의 관계
적대적 모델이 사용하는 전략은 학습자 모델(learner model)의 구조와 가중치에 내재된 선택 특성(choice characteristics)에 의해 결정된다. 이러한 선택 특성이 적대적 모델에 의해 활용될 경우, 학습자 모델은 비합리적이고 최적화되지 않은 행동을 하게 된다. 이는 전통적인 인지적 편향(cognitive biases)이 인간의 선택을 규범적 기준에서 벗어나게 만드는 것과 유사한 효과를 보인다. 즉, 적대적 모델이 학습자 모델을 조작하는 방식은 기존의 인지적 편향을 함축적으로 일반화한 형태로 볼 수 있으며, 이를 더 깊이 탐구하는 것이 향후 연구에서 중요한 방향이 될 것이다.
Batch 강화학습(Batch RL)과의 비교
이번 연구에서 제시한 프레임워크와 비교할 수 있는 대안적인 방법으로 배치 강화학습(Batch RL) 알고리즘이 있다. 배치 RL은 미리 수집된 데이터셋에서 학습을 진행하며, 환경과의 직접적인 상호작용 없이 학습이 가능하다는 점에서 차별성이 있다. 이는 RL2(Learning to Reinforcement Learn) 프레임워크와 유사한 방식이다. 그러나 본 연구의 접근 방식이 Batch RL보다 우월한 점은, 적대적 모델이 학습자 모델의 행동을 기반으로 해석 가능하도록 설계되었다는 점이다. 즉, 적대적 모델이 어떤 전략을 사용하여 학습자 모델을 조작하는지에 대한 명확한 설명이 가능하며, 이는 행동과학 및 인지심리학 연구에서 중요한 의미를 갖는다.
실험 설계(Experiment Design) 및 확장 가능성
이번 연구에서는 한 단계(one-step)에서의 적대적 조작을 중심으로 다루었지만, 동일한 프레임워크를 다단계(multistep) 실험 설계에도 적용할 수 있다. 예를 들어, 연구자가 특정한 행동 패턴을 피험자에게 유도하고자 하지만, 이에 적합한 실험 변수(확률, 지연 시간 등)를 사전에 알지 못한다고 가정하자. 이 경우, 학습자 모델을 훈련한 후, 해당 모델을 이용하여 적대적 모델을 학습시키면, 적대적 모델이 최적의 실험 변수를 찾아낼 수 있다. 이후, 도출된 실험 변수를 실제 실험에 적용하여 피험자가 기대한 행동을 보이는지 확인하고, 그렇지 않을 경우, 새로운 데이터셋을 사용하여 학습자 모델을 재훈련하는 과정을 반복하면 된다. 연구진은 이 과정이 반복될수록 수렴할 가능성이 높을 것이라고 추측하며, 이는 적대적 모델을 활용한 실험 설계에서 중요한 응용 가능성을 시사한다.