
States versus Rewards: Dissociable Neural Prediction Error Signals Underlying Model-Based and Model-Free Reinforcement Learning
강화 학습(Reinforcement Learning, RL)에서는 환경에서 직면하는 상황(상태, state)과 그에 따른 결과를 순차적으로 경험하면서, 특정 행동이 얼마나 좋은 결과를 가져오는지를 학습하는데, 이 과정에서 두 가지 주요 학습 방식이 존재한다. 첫 번째는 모델 자유 학습(Model-Free RL) 이다. 이 방식에서는 특정 행동이 예상보다 더 나은 보상을 받았는지, 혹은 더 나쁜 보상을 받았는지를 비교하는 보상 예측 오류(Reward Prediction Error, RPE)가 중심적인 역할을 한다. 모델 자유 학습에서는 환경의 구조를 명시적으로 이해하려 하지 않고, 단순히 경험적으로 보상 패턴을 기반으로 행동을 조정한다.
두 번째는 모델 기반 학습(Model-Based RL) 이다. 이 방식에서는 단순히 보상을 예측하는 것이 아니라, 환경의 상태 전이(state transition)와 보상 구조를 학습하여 내부적으로 모델을 구축한다. 이 모델을 활용하여 앞으로 일어날 가능성이 있는 상태 변화와 보상을 예측하고, 이를 바탕으로 최적의 행동을 선택한다. 모델 기반 학습에서는 상태 예측 오류(State Prediction Error, SPE) 가 중요한 역할을 한다. SPE는 기존의 내부 모델이 예측한 상태 전이와 실제 관찰된 상태 전이 간의 차이를 나타내며, 환경의 구조를 더 정교하게 학습할 수 있도록 돕는다. 이 논문의 요지는 MB, MF system에서 핵심적인 부분은 SPE, RPE를 인코딩하는 뇌 영역이 있는지 확인하고, 이 두 가치를 반영하여 의사 결정을 내리면 어떤 결과가 일어나는지 관찰하는 것이라고 이해하면 되겠다.
Introduction
이 연구에서는 피험자들에게 확률적 마르코프 결정 과제를 수행하도록 하였다. 이 과제는 이전의 상태와 행동에 따라 확률적으로 다른 상태로 전이되며, 최종적으로 금전적 보상(0¢, 10¢, 25¢)이 주어지는 구조를 가진다. 실험은 두 개의 세션으로 나누어졌다:
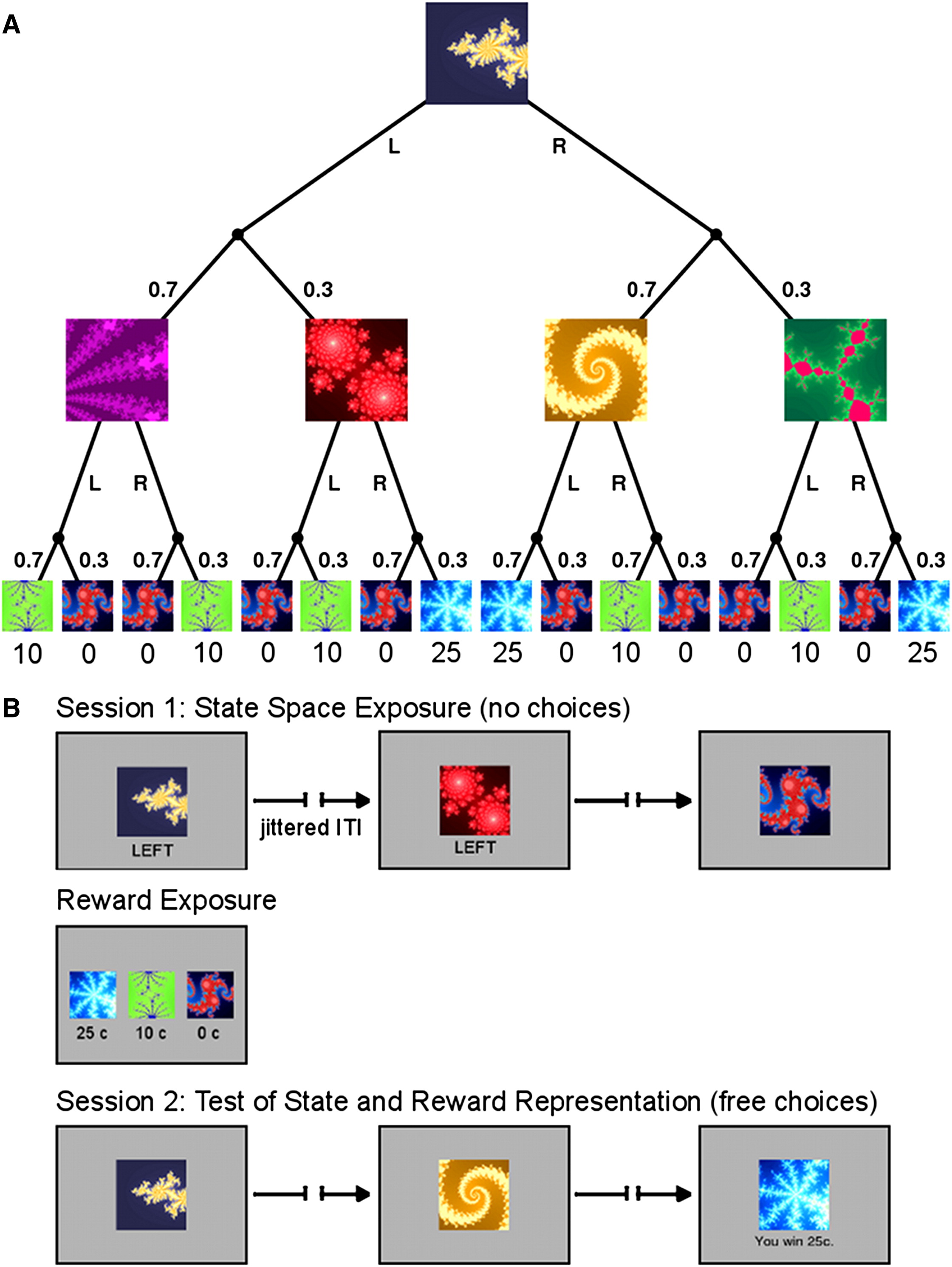
Session 1 (보상 없음): 참가자는 같은 초기 상태(starting state) 에서 시작하여, 모든 선택이 사전에 지정된(instructed) 상태이며, 피험자들은 단순히 버튼을 눌러 전이(transitions)를 경험하기만 한다. 피험자들은 결정된 선택을 따르며 보상이 제공되지 않을 학습할 기회가 주어진다. → 순수한 모델 기반 학습(SPE)이 일어나는 과정을 관찰할 수 있을 것이다.
Session 2 (보상 제공됨, 자유 선택 가능): 첫 번째 세션이 끝난 후, 피험자들은 각 결과 상태(outcome state)와 보상(reward) 간의 관계를 학습하며, 연구진은 피험자들에게 보상 구조(reward contingencies)를 알려주고, 간단한 연습 과제(choice task)를 통해 이를 익히도록 한다. 이번에는 피험자들은 이전 세션에서 학습한 상태 전이 정보를 바탕으로 스스로 선택을 수행하며, 최종적으로 보상을 받게 된다. → 보상 기반 학습(RPE)이 활성화되는 과정을 분석할 수 있을 것이다.
Results
연구진은 Session 2(자유 선택 세션)의 첫 번째 선택에서 참가자들이 최적의 선택을 했는지 평가하였다.
모델 기반 학습(Model-Based Learning)은 환경의 상태 전이(state transition)와 보상 구조를 학습하는 반면, 모델 자유 학습(Model-Free Learning)은 보상만을 기반으로 학습하기 때문에 Session 1(보상 없음) 동안 모델 자유 학습은 아무런 학습도 수행할 수 없다. 따라서, Session 2의 첫 선택이 확률적 우연이 아니라 더 나은 선택을 반영한다면, 이는 모델 기반 학습의 영향을 시사하는 증거가 된다. 실험 결과, 18명의 참가자 중 13명이 최적의 선택인 Right(R) 를 선택하였고(그림 A 참고), 5명만이 Left(L) 를 선택하였다. 이는 단순 확률보다 유의미하게 높은 비율이며, p < 0.05 (sign-test, one-tailed)에서 통계적으로 유의미한 결과였다. 따라서 참가자들의 선택이 모델 자유 학습만으로는 설명될 수 없으며, 모델 기반 학습을 통해 환경의 상태 전이 정보를 학습하고 이를 활용했음을 시사한다.
Computational model
연구진은 참가자들의 상태(state) 및 보상(reward) 학습이 행동과 뇌 활동에서 어떻게 나타나는지를 정량적으로 분석하기 위해, 수학적인 강화 학습(RL) 모델을 설계하였다. 이를 통해 모델 자유 학습(Model-Free RL)과 모델 기반 학습(Model-Based RL)이 뇌에서 어떻게 구현되는지를 보다 정밀하게 평가하고자 하였다.
📌 모델 자유 학습: SARSA (Model-Free RL)
첫 번째로, 연구진은 모델 자유 학습을 기반으로 한 SARSA(state-action-reward-state-action) 학습자(learner) 를 구현하였다. SARSA는 보상 예측 오류(Reward Prediction Error, RPE) 를 이용하여 행동 가치를 업데이트하는 방식이다. 피험자가 특정 상태에서 행동을 수행한 후, 예상했던 보상과 실제 받은 보상의 차이를 RPE로 계산하고, 이를 바탕으로 행동 가치를 수정한다. 이 모델은 순전히 경험을 기반으로 학습하며, 환경의 상태 전이(state transition) 정보를 명시적으로 고려하지 않는다. Session 1에서는 보상이 제공되지 않았기 때문에 RPE 값이 항상 0이었다. 즉, Session 1 동안 SARSA 모델은 아무런 학습도 수행할 수 없었다. 반면, Session 2에서 보상이 주어지면서 RPE가 활성화되었고, 모델 자유 학습이 본격적으로 작동하게 되었다.
📌 모델 기반 학습: FORWARD Learner (Model-Based RL)
두 번째로, 연구진은 모델 기반 학습을 반영한 FORWARD learner 를 구현하였다. 이 모델은 환경의 상태 전이 확률(state transition probability)을 학습하여, 이후의 행동을 평가하는 방식을 따른다. 행동을 수행할 때마다 실제 관찰된 상태 전이와 기존에 예측한 상태 전이 간의 차이를 상태 예측 오류(State Prediction Error, SPE)로 계산하여, 환경 모델을 업데이트한다. SPE는 피험자가 환경의 구조를 학습하는 데 중요한 역할을 한다. Session 1에서는 보상이 없었지만, 상태 전이(State Transition)를 학습하는 것이 가능했기 때문에, FORWARD 모델은 학습을 수행할 수 있었다. 즉, Session 1에서 FORWARD 모델만이 작동할 수 있었으며, 이때 RPE는 0이고, 오직 SPE만이 Nonzero이었다.
- FORWARD 모델의 핵심 구조
FORWARD 모델은 특정 상태 \(s\) 에서 행동 \(a\) 를 했을 때, 다음 상태 \(s'\) 로 전이될 확률 상태 전이 확률 \(T(s, a, s′)\)를 업데이트한다. 상태 예측 오류 는 \(δ_{SPE} = 1 - T(s, a, s')\)으로 계산할 수 있다. 그리고 상태 전이 확률 업데이트는 \(T(s, a, s') = T(s, a, s') + η ⋅ δ_{SPE}\)의 과정으로 전이 확률 matrix를 업데이트한다.
\(η\) : 상태 전이 확률의 학습률 (learning rate) \(δ_{SPE}\) : 상태 예측 오류 (State Prediction Error) \(T(s, a, s')\) : 현재 상태 전이 확률
SPE가 클수록, 새로운 경험을 반영하여 상태 전이 확률을 더 많이 수정하며 반복된 학습을 통해, 실제 환경의 상태 전이 확률에 점점 더 가까워진다.
- 가치 함수 업데이트
FORWARD 모델에서는 각 상태의 가치를 미래 보상의 기대값으로 평하는데 이때, 벨만 방정식(Bellman Equation) 을 기반으로 상태 가치를 업데이트한다. \(V(s) = ∑_a P(a | s) Q(s, a)\) \(Q(s, a)\) : 행동 \(a\) 의 가치 \(P(a | s)\) : 상태 \(s\) 에서 행동 \(a\) 를 선택할 확률
- 행동 가치
그리고 행동 가치 함수 \(Q(s, a)\) 는 상태 전이 확률 \(T\)와 가치 함수 \(V\)를 이용해 계산한다.
\[Q(s, a) = ∑_{s'} T(s, a, s') [ R(s') + γ V(s') ]\]\(R(s')\) : 다음 상태 \(s'\) 에서 얻을 수 있는 보상 \(γ\) : 할인율 (discount factor, 0 ≤ γ ≤ 1) \(V(s')\) : 다음 상태 \(s'\) 의 기대 가치
행동의 가치는 보상의 기대값과 미래의 상태 가치를 합산하여 계산되며, 이 과정에서 상태 전이 확률 \(T(s, a, s')\) 이 학습됨에 따라, 행동 가치 \(Q(s, a)\) 도 점점 더 정확해진다.
📌 모델 통합: HYBRID Learner
이전 연구들(Daw et al., 2005; Doya, 1999; Doya et al., 2002)에 따르면, 인간의 뇌는 모델 자유 학습과 모델 기반 학습을 모두 구현하는 것으로 보인다. 이에 따라 연구진은 두 학습 방식을 결합한 HYBRID learner를 설계하였다. HYBRID learner는 SARSA와 FORWARD learner에서 계산된 행동 가치(action value)를 가중 평균(weighted average)하여 최종적인 선택을 수행한다. 두 학습 방식의 상대적인 가중치는 시간이 지나면서 변화하는데, 연구진은 이 변화가 어떤 패턴을 따르는지 분석하였다.
1️⃣ HYBRID Learner의 구조
HYBRID learner는 FORWARD 모델(모델 기반 학습)과 SARSA 모델(모델 자유 학습)의 가중 평균(weighted average)을 통해 행동 가치를 계산한다. HYBRID learner는 각 행동 \(a\) 의 가치를 모델 기반 학습과 모델 자유 학습의 가치를 조합하여 평가한다.
\[Q_{HYB}(s, a) = w_t Q{FWD}(s, a) + (1 - w_t)Q_{SARSA}(s, a)\]\(Q_{HYB}(s, a)\) : HYBRID learner가 평가한 행동의 가치 \(Q_{FWD}(s, a)\) : 모델 기반 학습(FORWARD)의 행동 가치 \(Q_{SARSA}(s, a)\) : 모델 자유 학습(SARSA)의 행동 가치 \(w_t\) : 모델 기반 학습(FORWARD)의 가중치 (시간에 따라 변화)
2️⃣ HYBRID Learner의 가중치 업데이트
또한 연구진은 FORWARD의 가중치가 시간이 지나면서 점차 줄어들고, SARSA의 가중치가 증가하는 패턴을 따를 것이라고 가정하였다. 이를 표현하는 모델로 지수적 감쇠(exponential decay) 모델을 사용하였다.
\[w_t = l e^{-kt}\]즉 초기에는 모델 기반 학습이 우세하지만, 반복된 학습을 통해 경험적 학습(SARSA)이 점점 더 강해지는 패턴을 보인다.
행동 모델 적합성 평가
이 부분에서는 실험에서 사용한 강화 학습 모델(FORWARD, SARSA, HYBRID) 이 참가자들의 행동 데이터를 얼마나 잘 설명하는지 평가한 과정과, 추가적인 행동 증거를 통해 모델 기반 학습(Model-Based Learning)의 역할을 분석한 내용을 다룬다. 연구진은 각 학습 모델(FORWARD, SARSA, HYBRID)이 피험자들의 행동 데이터를 얼마나 정확하게 설명하는지 비교하기 위해, 모델 적합성 평가를 수행하였다. 이를 위해 Negative Log-Likelihood(NLL)를 최소화하는 방식으로 모델의 자유 매개변수(free parameters)를 최적화하였다.
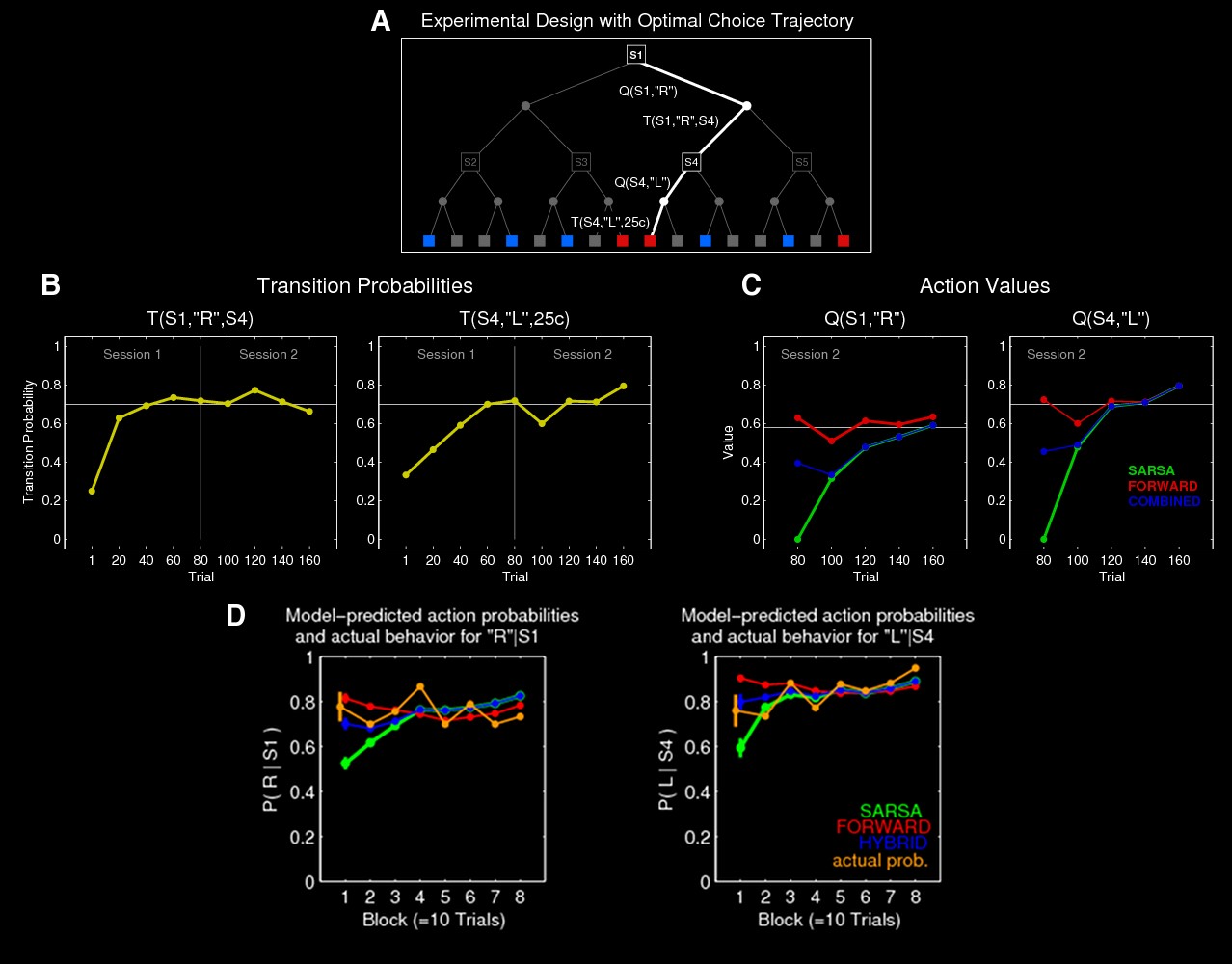
Figure S2는 실험 참가자들이 수행한 강화 학습 과정에서 상태 전이 확률, 행동 가치, 그리고 행동 선택 확률이 어떻게 변화하는지를 시각적으로 보여준다. 먼저, Figure S2(A)는 실험에서 제공된 의사 결정 트리 내에서 참가자들이 따라야 하는 최적의 경로를 나타낸다. 실험 중 참가자들은 특정 상태에서 왼쪽 또는 오른쪽 버튼을 선택할 수 있으며, 최적의 선택은 더 높은 보상을 받을 확률이 높은 경로를 따르는 것이다. 이 최적 경로를 학습하는 과정에서 FORWARD 모델이 먼저 환경의 상태 전이 확률을 학습하고, 이후 SARSA 모델이 보상을 경험하면서 점진적으로 최적의 행동을 학습하는 방식으로 진행된다.
Figure S2(B)에서는 FORWARD 모델이 예측한 상태 전이 확률의 변화를 보여준다. 노란색 곡선은 실험이 진행될수록 모델이 학습한 상태 전이 확률이 실제 상태 전이 확률(0.7)에 수렴하는 모습을 나타낸다. 이는 FORWARD 모델이 Session 1(보상이 없는 세션) 동안 순수하게 상태 전이 확률을 학습할 수 있음을 의미한다. 반면, SARSA 모델은 보상 기반 학습을 수행하기 때문에 Session 1에서는 전혀 학습이 이루어지지 않는다. 이로 인해 Session 2의 초반에는 FORWARD 모델이 학습한 상태 전이 확률을 바탕으로 행동을 결정하는 반면, SARSA 모델은 무작위로 행동을 선택하는 모습을 보인다.
Figure S2(C)에서는 행동 가치의 변화를 나타낸다. 최적 행동과 비최적 행동 간의 가치 차이를 분석한 결과, Session 2의 초반부에서 FORWARD 모델은 이미 학습한 상태 전이 정보를 바탕으로 최적 선택과 비최적 선택을 명확하게 구분하지만, SARSA 모델은 초기에는 이 차이를 인식하지 못한다. 시간이 지남에 따라 SARSA 모델도 보상을 경험하면서 점진적으로 최적 행동의 가치를 학습하고, 결국 최적 선택과 비최적 선택을 구분할 수 있게 된다. 그러나 SARSA 모델은 제한된 경험을 바탕으로 학습하기 때문에 행동 가치 차이를 다소 과대평가하는 경향을 보인다. 한편, HYBRID 모델은 FORWARD와 SARSA 모델을 가중 평균하여 행동 가치를 평가하는 방식으로 동작한다. Session 2의 초반부에서는 FORWARD 모델이 행동 선택을 주도하지만, 시간이 지나면서 SARSA 모델의 영향력이 점점 증가하여 최종적으로 행동 가치 차이가 SARSA 모델과 유사한 양상을 보이게 된다. 이는 FORWARD 모델의 가중치가 시간이 지남에 따라 감소하고, SARSA 모델의 가중치가 증가하는 HYBRID 모델의 특성과 일치하는 결과이다.
마지막으로, Figure S2(D)는 Session 2 동안 최적 행동이 선택될 확률의 변화를 보여준다. FORWARD 모델은 Session 2의 초반부에서 높은 확률로 최적 행동을 선택하는 반면, SARSA 모델은 초기에 무작위 선택을 하지만 보상을 경험하면서 점진적으로 최적 행동 선택 확률이 증가한다. HYBRID 모델은 Session 2 초반에는 FORWARD 모델의 행동 선택 패턴을 따르지만, 이후에는 SARSA 모델과 유사한 패턴을 보이며 점차 경험적 학습을 반영한다. 참가자들의 실제 행동 선택 확률과 모델의 예측값을 비교했을 때, HYBRID 모델이 참가자들의 행동을 가장 잘 설명하는 모델임을 확인할 수 있다.
Nerual signature of PRE and SPE
이 연구의 핵심 목표 중 하나는 SARSA와 FORWARD 모델에서 계산된 예측 오류(prediction errors)가 뇌의 특정 영역에서 어떻게 반영되는지를 분석하는 것이다. 이를 위해 연구진은 보상 예측 오류(Reward Prediction Error, RPE)와 상태 예측 오류(State Prediction Error, SPE)를 각각 신경 활동과 비교하였다. 연구진은 각 참가자의 신경 활동을 예측 오류 값과 비교하기 위해 단일 피험자(single-subject) 분석을 수행하였다. RPE & SPE를 각각 두 번째 결정 상태(state 2)와 최종 보상 결과 상태(outcome state)에서 파라메트릭 조절자(parametric modulators)로 포함시키고 각 뇌 영역이 해당 예측 오류 값과 얼마나 강하게 공변하는지를 베타 계수(beta estimate)로 측정하였다. 이 베타 이미지를 그룹 수준에서 repeated-measures ANOVA을 수행하여, 전체 참가자에서 RPE와 SPE가 신경 활동과 얼마나 일관되게 관련이 있는지 분석하였다.
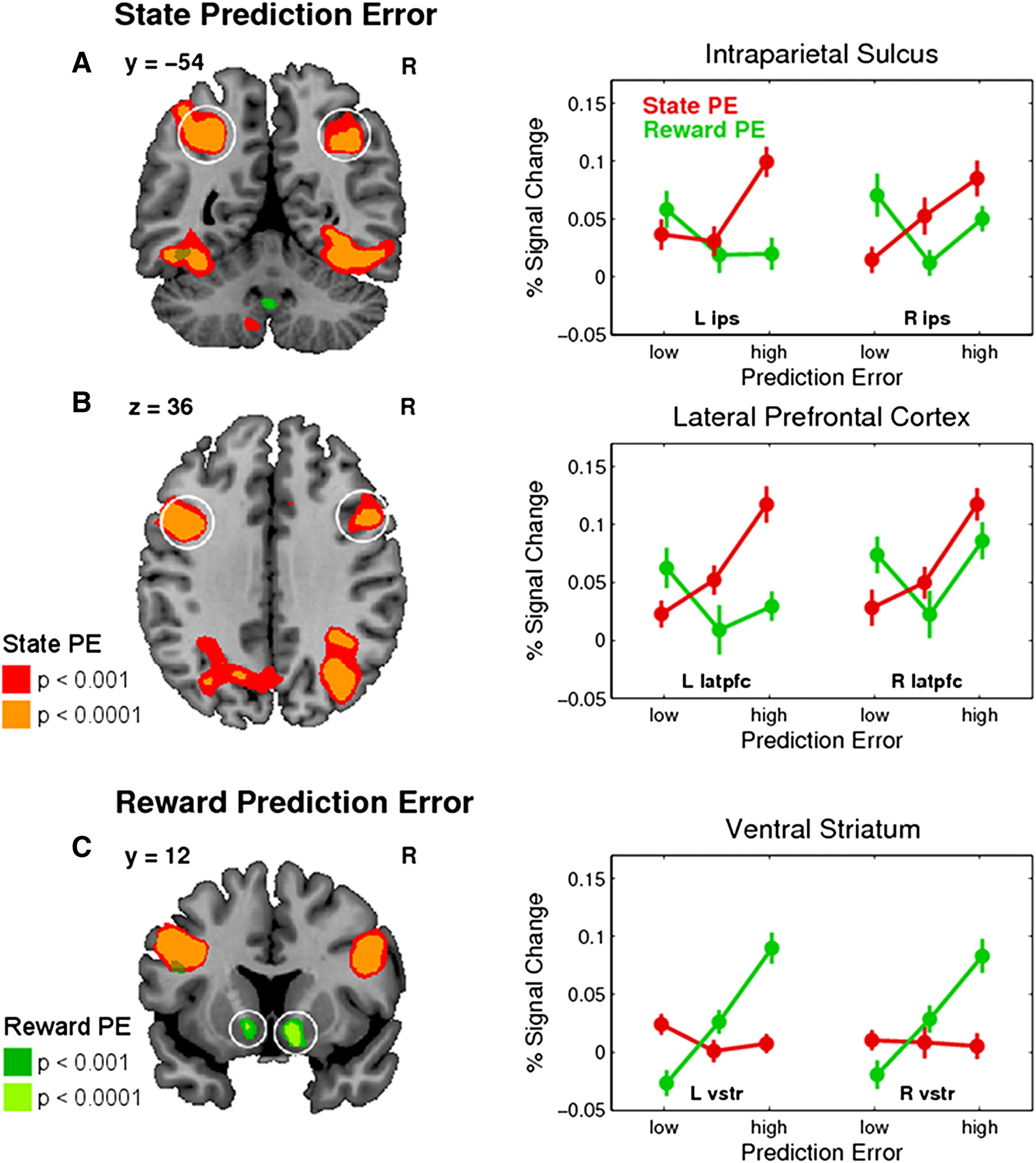
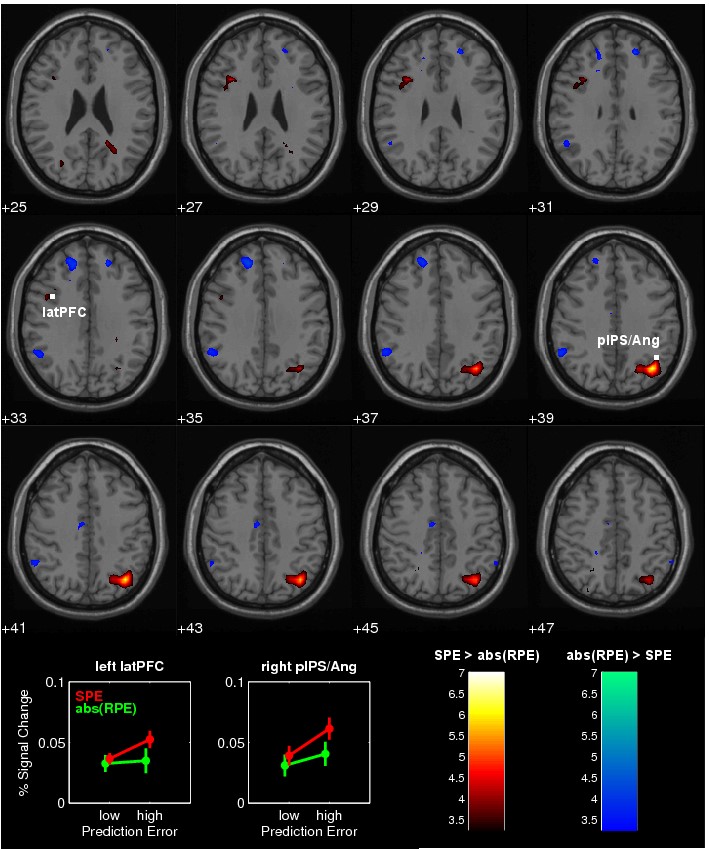
figure 3에서는 SPE와 RPE가 서로 다른 신경 영역에서 반영됨을 확인할 수 있다. 연구진은 RPE와 SPE가 뇌의 어떤 영역에서 유의미한 신경 활동을 유발하는지를 분석하였으며, 그 결과가 시각적으로 제시되었다.
Figure 3A와 3B에서는 SPE와 강한 상관관계를 보이는 신경 영역이 확인되었다. 연구 결과에 따르면, pIPS(posterior intraparietal sulcus)와 latPFC(lateral prefrontal cortex)에서 SPE와 강한 신경 반응이 관찰되었다. 구체적으로,
- 좌측(왼쪽) pIPS에서는 상부 두정소엽(Superior Parietal Lobule, SPL)까지 활성화됨.
- 우측(오른쪽) pIPS에서는 Angular Gyrus까지 활성화됨.
- latPFC에서는 후하전두이랑(posterior inferior frontal gyrus, pIFG)에서 SPE가 반영됨.
이러한 결과는 Figure 3A와 3B에서 원으로 표시된 영역에서 확인할 수 있다. 이와 달리, Figure 3C에서는 RPE와 강한 상관관계를 보이는 신경 영역을 분석하였다. 그 결과, RPE는 ventral striatum (vStr)에서 강한 신경 반응과 관련됨이 확인되었다. 또한, vStr에서는 RPE 값이 증가할수록 선형적으로 BOLD 신호가 증가하는 경향이 뚜렷이 나타남을 볼 수 있다.
반면, SPE와 관련된 pIPS 및 latPFC에서는 RPE와 유의미한 신경 반응이 관찰되지 않았으며, vStr에서는 SPE와의 유의한 신경 반응이 확인되지 않았다. 이는 SPE와 RPE가 서로 독립적인 신경 네트워크에서 반영됨을 의미한다.
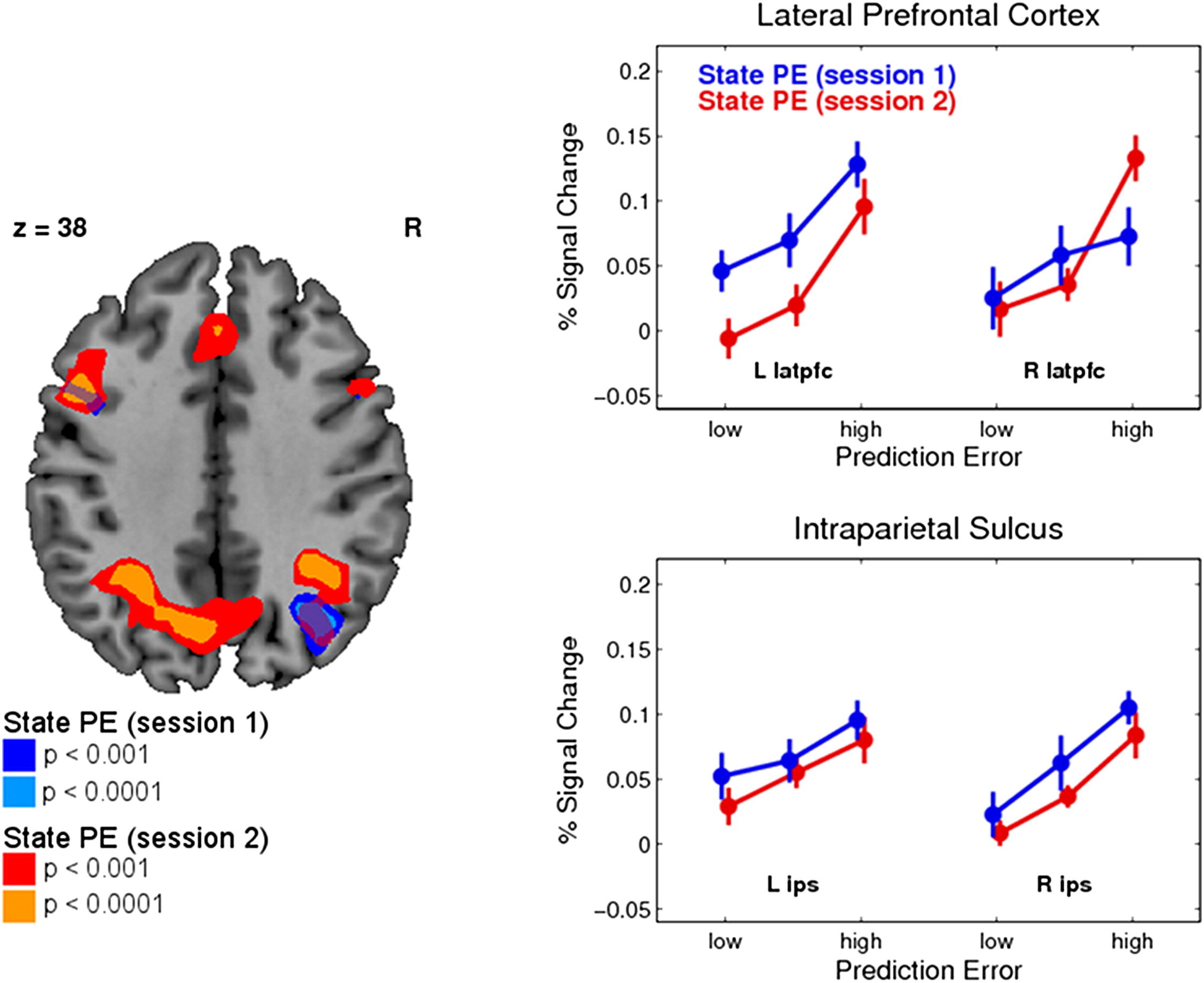
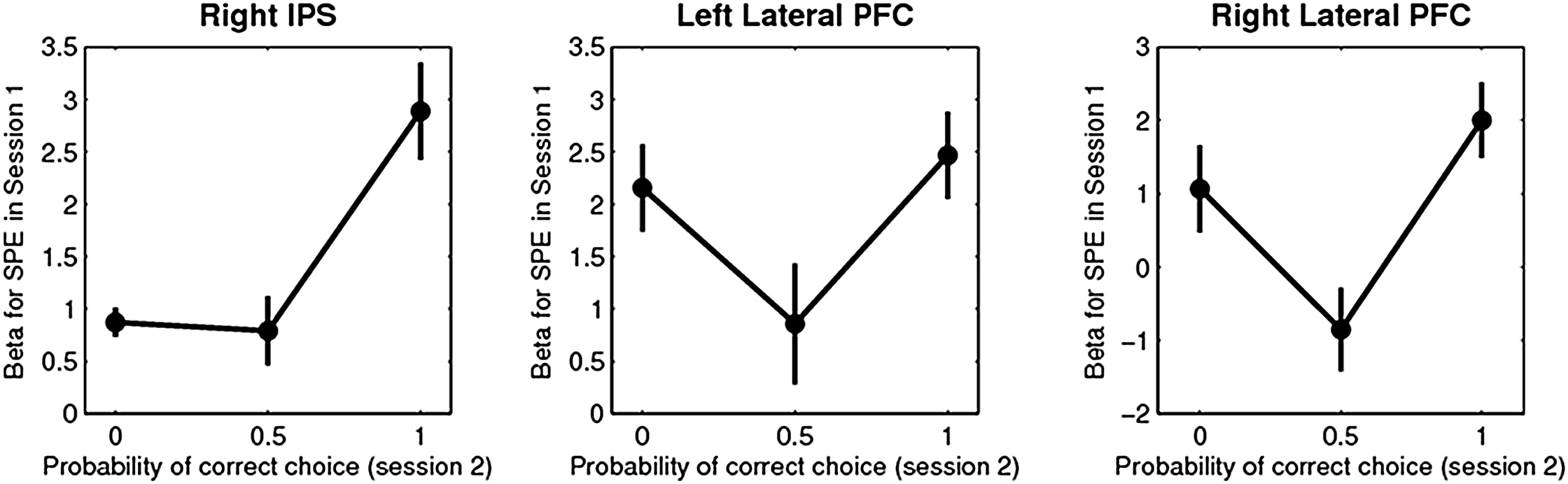
Figure 4에서는 Session 1에서도 SPE 신경 신호가 관찰되었는지 검증하는 분석 결과가 포함되었다. 연구진은 Session 2에서 SPE와 강한 신경 반응을 보였던 영역(pIPS 및 latPFC)을 기반으로, 동일한 신경 반응이 Session 1에서도 나타나는지 확인하고자 하였다. 이를 위해 Session 2에서 SPE와 가장 강하게 연관된 피크 복셀(peak voxel) 좌표를 찾아낸 후, Session 1에서도 동일한 좌표에서 신경 활동을 분석하였다.
그 결과, Session 1에서도 latPFC 및 pIPS/angular gyrus에서 유의미한 SPE 신경 활동이 관찰되었다. 이는 SPE 신호가 보상 정보 없이도 환경의 상태 전이(state transition)를 학습하는 과정에서 발생한다는 점을 의미한다. 즉, 모델 기반 학습(FORWARD 모델)은 보상이 없는 상태에서도 순수한 환경의 상태 변화를 학습하는 데 기여할 수 있음을 시사한다.
신경적 SPE 신호와 행동의 관계 (Relationship between Neural SPE Signal and Behavior)
이 연구에서는 SPE(State Prediction Error)가 단순히 신경 활동과 관련된 것이 아니라 실제 행동에도 영향을 미치는지 여부를 검증하고자 하였다. 즉, SPE를 강하게 반영하는 뇌 영역에서의 활동이 참가자들이 더 나은 선택을 하는 능력과 연관이 있는지 분석하였다. 이전 분석에서는 SPE가 특정 뇌 영역(latPFC 및 pIPS)에서 강하게 반영된다는 점을 확인하였다.
이제 연구진은 이 신경적 SPE 신호가 실제 행동(올바른 선택을 하는 능력)과 상관관계를 갖는지 분석하고자 하였다.만약 SPE 신경 신호가 실제 행동과 관련이 있다면, Session 1에서 SPE와 강한 연관을 보였던 뇌 영역(pIPS 및 latPFC)의 신경 활동과, Session 2에서 참가자가 올바른 선택을 한 비율(percent correct choices) 사이에 유의미한 상관관계가 나타날 것이라고 예상하였고 반대로, 만약 이 신경 신호가 단순한 신경 반응에 불과하고 행동과 직접적인 연관이 없다면, Session 2에서 올바른 선택을 한 비율과 신경 신호 간의 상관관계는 나타나지 않을 것이라 예상하였다.
연구진은 다음과 같은 분석을 수행하였다.
✅ 신경 신호 (Neural Data) 추출
Session 1에서 SPE가 강하게 반영된 영역을 대상으로 신경 활동을 분석을 진행하였다. 이전 분석에서 유의미한 신경 활동을 보였던 두정엽 pIPS 및 양측(latPFC)에서 신경 신호를 추출해서 각 피험자의 신경 활동 값을 그룹 피크 복셀(peak voxel)을 중심으로 반경 10mm 구체적 영역(spherical volume)에서 평균 내어 계산하였다.
✅ 행동 선택 정확도 (Behavioral Performance) 측정
Session 2에서 참가자가 최적의 행동을 선택한 비율(percent correct choices)과 비교해서 최적의 행동은 기대 보상 크기(reward magnitude) × 실제 상태 전이 확률(true transition probability)이라 정의하였다. 이는 연구에 사용된 계산 모델과 독립적인 행동 지표이며, 강화 학습 모델과 무관하게 순수한 행동적 정확도를 측정하는 지표이다.
연구 결과, 우측 pIPS의 신경 활동과 올바른 선택 비율(percent correct choices) 간에 유의미한 양의 상관관계가 나타났다. 상관계수 r=0.57,p=0.013 로 통계적으로 유의미한 수준으로, 우측 pIPS에서 SPE를 강하게 반영하는 피험자일수록 Session 2에서 더 나은 선택을 하는 경향을 보였다.(figure 5A 참고) 반면 latPFC에서는 유의미한 상관관계가 나타나지 않았다. (figure 5B 참고) 좌측 latPFC의 결과는 r=0.28,p=0.27, 우측 latPFC는 r=0.38,p=0.12로 각각 유의미하지 않은 결과가 나왔다. 즉, latPFC는 SPE를 반영하지만, 행동 선택 정확도를 직접적으로 설명하지는 않았다.
SPE 신호가 단순한 주의(attention) 또는 살리언스(salience) 효과가 아님을 검증
연구진은 SPE(State Prediction Error) 신호가 단순히 특정 상태가 예상보다 예기치 않게 등장했을 때 피험자들이 더 많은 주의를 기울인 결과인지, 아니면 실제로 모델 기반 학습과 관련된 신경 신호인지를 검증하고자 하였다. 이 연구에서는 주의(attention)나 살리언스(salience, 자극의 눈에 띄는 정도)가 강한 사건일수록 더 높은 BOLD 반응을 유발할 수 있기 때문에, SPE 신호가 단순히 이러한 비특이적(arousal-related) 신호가 아닌지 분석하였다.
가능성 있는 대안 가설 (Null Hypothesis)은 SPE 신호는 단순히 예기치 않은 상태(state)의 등장에 의해 주의력이 증가한 결과일 수 있다. 즉, SPE 신호는 실제 학습과 관련된 것이 아니라, 단순히 예측과 다른 상태가 등장했을 때 더 많은 주의를 기울이기 때문일 가능성이 있다는 것을 의미한다. 이러한 경우, 예측과 다른 상태가 등장했을 때뿐만 아니라, 보상이 예상과 다르게 제공(또는 미제공)될 때에도 유사한 신경 반응이 발생해야 한다.
이에 대한 연구진의 가설 (Alternative Hypothesis)은 SPE 신호는 단순한 놀람 효과(surprise signal)나 살리언스 효과(salience effect)가 아니라, 모델 기반 학습과 직접적으로 관련된 신경 신호여야 한다는 것이다. 만약 SPE 신호가 단순한 놀람 신호라면, 보상 예측 오류(RPE)와도 동일한 방식으로 작동해야 한다. SPE 신호와 절대값 RPE(abs(RPE)) 신호가 동일한 뇌 영역에서 나타나지 않는다면, 이는 SPE가 단순한 놀람 효과가 아님을 도출할 수 있다.
연구진은 보상 예측 오류(RPE)의 절대값(abs(RPE))을 사용하여, 단순한 놀람(surprise) 신호와 SPE 신호가 동일한지 분석하였다. abs(RPE) 신호는 두정엽 피질(IPS) 전방(anterior IPS)에서 강한 신경 활성화를 유발하였다. (p < 0.001, uncorrected) 그러나, SPE와 강한 상관관계를 보였던 후방 IPS(posterior IPS)와는 다른 위치에서 abs(RPE) 신호가 나타났다. 즉, 놀람 신호(surprise)와 SPE 신호는 뇌의 서로 다른 영역에서 반영되었다.
SPE 신호와 abs(RPE) 신호 직접 비교(Figure S4 분석 결과)한 결과는 다음과 같다. 후방 IPS (posterior IPS) 영역에서는 SPE 신호가 abs(RPE) 신호보다 유의미하게 더 강하게 설명되었다. (p < 0.05, corrected). latPFC에서도 SPE 신호가 abs(RPE) 신호보다 유의미하게 더 강하게 설명되었다. (p < 0.001, uncorrected). 즉, SPE 신호가 단순한 놀람(surprise) 신호나 살리언스(salience) 신호보다 모델 기반 학습과 관련이 더 큼을 의미한다.
추가적으로 SPE와 abs(RPE) 신호의 중첩 영역 분석 (Conjunction Analysis)에서는 연구진은 SPE와 abs(RPE) 신호가 같은 뇌 영역에서 중첩되는지 확인하기 위해 conjunction analysis를 수행하였다. 결과적으로, 어떠한 뇌 영역에서도 SPE와 abs(RPE) 신호가 동시에 활성화되는 중첩 효과가 나타나지 않음으로 즉, SPE 신호와 놀람(surprise) 신호는 완전히 별개의 신경 과정임이 확인되었다.
Discussion
이번 연구에서는 모델 기반 학습(Model-Based Learning)과 모델 자유 학습(Model-Free Learning)이 서로 다른 신경 네트워크를 통해 작동한다는 점을 신경과학적으로 검증하였다. 연구진은 이를 위해 보상 예측 오류(Reward Prediction Error, RPE)와 상태 예측 오류(State Prediction Error, SPE)의 신경적 표식을 분석하였으며, 각각이 다른 뇌 영역에서 반영됨을 확인하였다. 또한, 인간이 환경의 상태 전이를 학습할 때 SPE 신호를 기반으로 모델 기반 학습을 수행한다는 점을 실험적으로 증명하였다.
이 연구의 결과는 인간의 의사 결정 과정에서 모델 기반 학습이 어떻게 구현되는지, 그리고 강화 학습 시스템이 뇌에서 어떻게 작동하는지에 대한 중요한 시사점을 제공한다. 연구의 주요 결과와 논의를 다음과 같이 정리할 수 있다.
-
모델 기반 학습과 모델 자유 학습의 신경적 차별화 연구 결과, 모델 기반 학습과 모델 자유 학습은 서로 독립적인 신경 시스템을 통해 구현됨이 확인되었다. SPE는 후방 두정내구(pIPS)와 외측 전전두 피질(latPFC)에서 강한 신경 반응을 보였으며, 이는 환경의 상태 전이를 학습하는 과정과 밀접한 관련이 있음을 시사한다. 반면, RPE는 배측 선조체(vStr)에서 강하게 반영되었으며, 이는 보상 기반 학습과 관련된 신경 활동을 의미한다. 이러한 결과는 모델 기반 학습과 모델 자유 학습이 서로 다른 신경 기제를 통해 독립적으로 작동한다는 점을 신경과학적으로 증명하는 것이다.
-
pIPS와 latPFC의 역할: 모델 기반 학습의 핵심 영역 연구진은 pIPS와 latPFC가 모델 기반 학습에서 중요한 역할을 수행한다는 점을 실험적으로 검증하였다. pIPS는 환경의 상태 전이를 학습하는 데 핵심적인 역할을 하며, 보상이 없는 상태에서도 신경 반응을 보이는 것이 확인되었다. 이는 모델 기반 학습이 보상 유무와 관계없이 환경의 구조를 학습할 수 있음을 의미한다. 즉, pIPS는 환경 내 상태 간의 관계를 학습하는 데 중요한 역할을 수행하며, 이를 통해 인간은 보상 없이도 환경의 상태 변화를 학습할 수 있다.
한편, latPFC 역시 SPE 신호를 반영하지만, 행동 선택과 직접적인 상관관계는 나타나지 않았다. 이는 latPFC가 모델 기반 학습에서 정보 통합을 담당하는 역할을 할 가능성이 높음을 시사하지만, 실제 행동 선택 과정에서 직접적인 영향을 미치는 것은 pIPS임을 의미한다. 따라서 pIPS는 단순히 상태 전이를 학습하는 것이 아니라, 이를 바탕으로 실제 행동을 결정하는 데까지 영향을 미치는 핵심 신경 영역이라 할 수 있다.
- SPE 신호는 단순한 놀람(Surprise) 신호가 아님 연구진은 SPE 신호가 단순한 놀람(surprise) 효과가 아니라, 환경의 상태 전이를 학습하는 신경 신호임을 증명하였다. 이를 검증하기 위해 SPE 신호와 절대값 RPE(abs(RPE)) 신호를 비교하는 분석을 수행하였으며, 그 결과 SPE 신호는 후방 IPS(pIPS) 및 latPFC에서 강하게 반영되었지만, abs(RPE) 신호는 서로 다른 영역에서 반응을 보였다. 이는 SPE가 단순한 놀람 효과가 아니라, 실제 모델 기반 학습과 관련된 신경 신호임을 의미한다.
또한, 연구진은 SPE 신호와 abs(RPE) 신호가 뇌에서 중첩되는지 확인하기 위해 conjunction analysis를 수행하였으며, 그 결과 SPE 신호와 abs(RPE) 신호가 중첩되는 영역이 없음이 확인되었다. 즉, SPE 신호는 단순히 예기치 않은 사건(surprise)에 대한 반응이 아니라, 환경의 상태 전이를 학습하는 신경적 과정에서 발생하는 신호임이 증명되었다.
- 모델 기반 학습과 모델 자유 학습의 상호작용 이 연구의 또 다른 중요한 시사점은 인간의 의사 결정 과정에서 모델 기반 학습과 모델 자유 학습이 상호작용할 가능성이 높다는 점이다. 연구 결과, Session 2 초반에는 모델 기반 학습(FORWARD 모델)이 주도적으로 작동하지만, 시간이 지나면서 모델 자유 학습(SARSA 모델)이 점차 더 큰 영향을 미치는 경향이 확인되었다. 즉, 초기에는 환경의 상태 전이를 학습한 정보를 바탕으로 행동을 결정하지만, 반복된 경험을 통해 보상 기반 학습이 점점 더 중요한 역할을 하게 된다. 이는 모델 기반 학습과 모델 자유 학습이 독립적으로 작동하지만, 시간이 지나면서 두 시스템이 서로 상호작용할 가능성이 있음을 시사한다.